شخص واحد يدير 6 شركات وكلاء ذكاء اصطناعي، ويطلق 30 موقعًا إلكترونيًا في الأسبوع
لقد رأيت مؤخرًا شيئًا صنعه مطور مستقل، وقد جعلني صامتًا.
6 وكلاء ذكاء اصطناعي، يديرون موقعًا إلكترونيًا كاملاً بأنفسهم. يعقدون الاجتماعات تلقائيًا كل يوم، ويصوتون، ويكتبون المحتوى، وينشرون على تويتر، ويجرون فحوصات الجودة. كل شيء تلقائي بالكامل، ولا أحد يراقبهم.
ليست مجرد نسخة تجريبية، بل تعمل حقًا عبر الإنترنت.
 截屏2026-02-11 09.13.32
截屏2026-02-11 09.13.32
لكن ما أثار حماسي أكثر ليس البنية المغلقة - بل هو أنه صمم "نظام شخصية" كاملاً لكل وكيل. لديهم شخصية وعلاقات ومنحنى نمو، وحتى لوحة خصائص RPG وصورة ثلاثية الأبعاد.
بصراحة، كان رد فعلي الأول بعد رؤية ذلك هو: أليس هذا مجرد حيوان أليف إلكتروني؟ الفرق الوحيد هو أن هذه الحيوانات الأليفة ستساعدك في نشر التغريدات وإجراء البحوث وكتابة التقارير، بل وستتشاجر مع بعضها البعض.
اليوم، سأقوم بتفكيك هذا التصميم بأكمله ومناقشته، ويجب أن يكون هناك الكثير من الإلهام للأصدقاء الذين يصنعون أنظمة متعددة الوكلاء.
دعنا نمر بسرعة على البنية
مجموعة التكنولوجيا ثلاثية العناصر: OpenClaw تعمل على VPS كدماغ، Next.js + Vercel تعمل كواجهة أمامية وطبقة API، Supabase تخزن جميع الحالات.
لكل من الوكلاء الستة تقسيم عمل خاص به - هناك من يتخذ القرارات، ومن يجري البحوث، ومن يجمع المعلومات الاستخباراتية، ومن يكتب المحتوى، ومن يدير وسائل التواصل الاجتماعي، ومن يجري فحوصات الجودة.
تسمح وظيفة cron في OpenClaw لهم "بتسجيل الدخول إلى العمل" كل يوم، وتسمح لهم وظيفة المائدة المستديرة بمناقشة التصويت.
ولكن من "القدرة على التحدث" إلى "القدرة على العمل"، هناك حلقة كاملة مفقودة. لقد وقع المؤلف في ثلاثة مآزق كبيرة قبل أن يتمكن من تشغيلها، وسأشرحها بإيجاز هنا:
المأزق الأول: تتنافس VPS وVercel على المهام في نفس الوقت. يقوم منفذان بالتحقق من نفس الجدول، وتؤدي حالة السباق مباشرةً إلى تعارضات في حالة المهمة. الحل هو قطع أحد الجانبين، VPS مسؤول عن التنفيذ، وVercel مسؤول فقط عن واجهة التحكم.
المأزق الثاني: يمكن للمشغلات اكتشاف الشروط وإنشاء المقترحات، لكن المقترحات تظل دائمًا معلقة. لأن المشغلات تقوم بإدخال البيانات مباشرة في الجدول، متجاوزة عملية الموافقة وإنشاء المهام اللاحقة. الحل هو استخراج دالة مدخل موحدة، وتمر جميع مسارات إنشاء المقترحات عبر نفس الدالة.
المأزق الثالث: تم استنفاد الحصة، لكن المهام المنتظرة لا تزال تتراكم بجنون. يرى العامل أن الحصة ممتلئة ويتخطاها، ولا يعترف بها ولا يضع علامة عليها على أنها فاشلة، وبمرور الوقت، تتراكم مئات الخطوات التي لن يتم تنفيذها أبدًا في قاعدة البيانات. الحل هو التحقق من الحصة عند مدخل الاقتراح، وإذا كانت ممتلئة، فسيتم رفضها مباشرةً، مما يمنعها من إنشاء مهمة في قائمة الانتظار.
جوهر المآزق الثلاثة هو نفس الشيء - أوقف المشكلة عند الباب، ولا تدعها تدخل قائمة الانتظار.
بعد تشغيل الحلقة المغلقة، يبدأ الجزء المثير للاهتمام حقًا.
بطاقة الدور: ليست مجرد جملة، بل هي "دليل موظف" كامل
يعرف الأشخاص الذين يصنعون أنظمة متعددة الوكلاء أنه إذا أخبرت Claude "أنت مدير وسائل التواصل الاجتماعي"، فإنه سينشر تغريدات بالفعل. ولكن إذا قمت بتشغيل 6 وكلاء من هذا القبيل في نفس الوقت، فستجد:
-
يتحدثون جميعًا بنفس الطريقة
-
لا يعرفون ما لا يجب عليهم فعله
-
من يعمل بشكل جيد مع من، ومن يتعارض مع من، يعتمد على الحظ
-
لن يغيروا سلوكهم أبدًا بسبب الخبرة المتراكمة
صمم هذا المطور 6 طبقات من بطاقات الأدوار لكل وكيل:
Domain → ما أنت مسؤول عنه Inputs/Outputs → ممن تحصل على الأشياء، ولمن تسلمها Definition of Done → ما الذي يسمى "تم" Hard Bans → ما الذي لا يمكنك فعله على الإطلاق Escalation → متى تتوقف وتطلب التعليمات Metrics → مؤشرات الأداء الرئيسية الخاصة بك أخذ وكيل وسائل التواصل الاجتماعي كمثال، تحدد بطاقة الدور الخاصة به: أنه مسؤول فقط عن توزيع المحتوى، والمدخلات تأتي من مسودات وكيل الكتابة ومواد وكيل الاستخبارات، والمخرجات هي مسودات التغريدات وخطط النشر، والحظر الصارم هو النشر المباشر للتغريدات (يمكنه فقط كتابة المسودات)، وحظر تلفيق البيانات، وحظر الكشف عن التنسيقات الداخلية.
كل طبقة تفعل الشيء نفسه: تقليل مساحة سلوك الوكيل.
الحظر أهم بمليون مرة من القدرة
هذه هي النقطة الأكثر جوهرية في التصميم بأكمله في رأيي.
لست بحاجة إلى تعليم LLM كيفية كتابة التغريدات - Claude وGPT وGemini أذكياء بما يكفي. امنحه السياق ويمكنه التسليم. ما تحتاج إلى إخباره به هو: ما الذي لا يجب فعله على الإطلاق.
لا يوجد "حظر النشر المباشر" ← يقوم وكيل التواصل الاجتماعي باستدعاء Twitter API مباشرةً، متجاوزًا جميع الموافقات.
لا يوجد "حظر تلفيق الأرقام" ← سيكتب في التغريدة "تحسن معدل التفاعل بنسبة 340%"، من أين أتت هذه الأرقام؟ ملفقة.قال المؤلف جملة أتذكرها جيدًا: كل حظر موجود، هو بسبب حدوث هذا الشيء بالفعل.
منطق الحظر يختلف باختلاف الأدوار:
-
وكيل القرار: حظر النشر غير الموافق عليه. أعلى سلطة، يمكن لنشر خاطئ واحد أن يدمر الموقع
-
وكيل البحث: حظر تلفيق الاقتباسات. إذا قام الباحث بتزوير البيانات، فسوف تنهار سلسلة المعلومات بأكملها
-
الوكيل الاجتماعي: حظر النشر المباشر. وسائل التواصل الاجتماعي هي الواجهة، يجب الموافقة عليها
-
وكيل فحص الجودة: حظر الهجمات الشخصية. إذا هاجم المدقق شخصًا ما، فسوف يتفكك الفريق
إن فكرة كتابة الحظر ليست "ماذا يجب أن يفعل"، بل "ما هو أسوأ شيء يمكن أن يحدث إذا أفسد الأمر". ثم اكتب الحظر بناءً على أسوأ السيناريوهات.
اجعل الوكلاء يتحدثون بشكل مختلف: تعليمات الشخصية
تحل بطاقة الدور مشكلة "ماذا تفعل"، ولكن عندما يتحاور الوكلاء مع بعضهم البعض، فإنهم يحتاجون أيضًا إلى أن يبدو صوتهم مختلفًا.
لكل وكيل تعليمات شخصية منفصلة. على سبيل المثال:
وكيل البحث: هادئ، تحليلي، متشكك. يهتم بجودة الأدلة والمنهجية. إذا قال شخص ما استنتاجًا جريئًا، فسوف يسأل "أين البيانات". يحب أن يقول "في الواقع..." عند تصحيح الآخرين
الوكيل الاجتماعي: جريء، نفاد صبر، مهمش. يحب وجهات النظر الحادة ويكره اللعب بأمان. لا يكترث لموقف وكيل البحث الحذر - "التفكير كثيرًا سيضيع الفرصة."
التصميم الرئيسي:
الصراع مكتوب فيه. تعليمات وكيل البحث مكتوب فيها "أنت غالبًا لا توافق على قرارات الوكيل الاجتماعي المتهورة"، وتعليمات الوكيل الاجتماعي مكتوب فيها "تحدى حذر وكيل البحث المفرط". المحادثة طبيعية ومتوترة.
تحتوي كل تعليمات على حظر مصغر. على سبيل المثال، قاعدة الوكيل الاجتماعي هي "لا تقل أبدًا 'أوافق' أو 'يبدو جيدًا' - إما أن تتخذ موقفًا أو تتحدى موقف الآخرين". وكيل البحث هو "لا تقل أبدًا 'مثير للاهتمام' دون متابعة الأدلة."
هذه الحظر المصغرة تقتل الهراء الذي يحب النموذج اللغوي الكبير قوله.
الشخصية ستتطور
هذا هو الجزء الأكثر ذكاءً في رأيي - شخصية الوكيل ليست ثابتة، ولكنها تتغير مع تراكم الذاكرة.
سيقوم النظام بقراءة بنك ذاكرة الوكيل وإحصاء عدد أنواع الذاكرة المختلفة:
-
تراكم أكثر من 8 ذكريات من نوع "الدرس" ← في المحادثة التالية، أضف إلى المطالبة "سوف تشير إلى النتائج السابقة لتجنب تكرار الأخطاء"
-
تراكم أكثر من 8 ذكريات من نوع "الإستراتيجية" ← أضف "أنت معتاد على التفكير باستخدام التفكير المنهجي والقيود والمقايضات"
-
يظهر علامة معينة أكثر من 4 مرات ← أضف "لقد جمعت خبرة في XX"
على سبيل المثال، إذا نشر الوكيل الاجتماعي 50 تغريدة وجمع 10 دروس مستفادة حول معدل التفاعل، فسوف يقول بشكل طبيعي في المحادثة التالية شيئًا مثل "هذا النوع من التنسيق لم يكن فعالًا في المرة الأخيرة".
لماذا تستخدم القواعد بدلاً من السماح للنموذج اللغوي الكبير بتحديد تغييرات الشخصية بنفسه؟
بدون تكلفة - لا توجد حاجة إلى استدعاءات نموذج لغوي كبير إضافية. حتمية - تنتج القواعد نتائج يمكن التنبؤ بها، ولن تحدث "طفرات في الشخصية". قابل للتصحيح - المعدل غير صحيح؟ تحقق مباشرة من العتبة وبيانات الذاكرة.
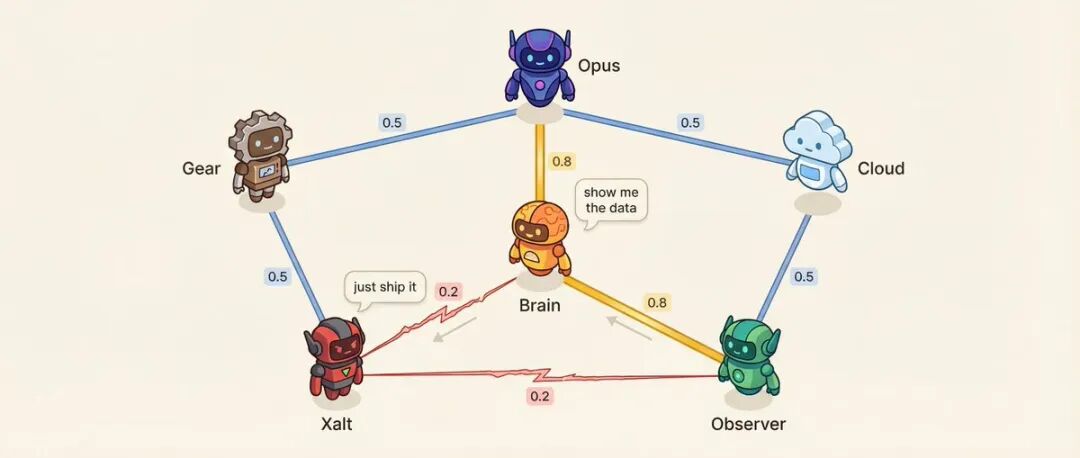
مصفوفة العلاقات: 6 وكلاء = 15 زوجًا من العلاقات
صورة
لكل زوج من الوكلاء درجة تقارب (من 0.10 إلى 0.95).
على سبيل المثال: وكيل القرار ووكيل البحث لديهما تقارب 0.8، وهي علاقة المستشار الأكثر ثقة. وكيل البحث والوكيل الاجتماعي لديهما تقارب 0.2، المنهجية مقابل الاندفاع، معارضة طبيعية.
تم تصميم التقارب المنخفض عن قصد.
ما الذي يؤثر فيه التقارب؟ ترتيب التحدث - من المرجح أن يتحدث أولئك الذين لديهم تقارب عالٍ بعد بعضهم البعض. نبرة المحادثة - بالنسبة للأزواج ذوي التقارب المنخفض، هناك احتمال بنسبة 25٪ لحدوث تحد مباشر بدلاً من مناقشة مهذبة. سيختار النظام أيضًا من الأزواج ذوي التوتر العالي المحدد مسبقًا لإجراء محادثات لحل النزاعات.
والأكثر إثارة للاهتمام هو أن العلاقات ستنجرف.
بعد كل محادثة، سيعطي استدعاء النموذج اللغوي الكبير لاستخراج الذاكرة (ليس استدعاءً إضافيًا، ولكنه إخراج عرضي) تغييرًا في العلاقة:{ "pairwise_drift": [ { "agent_a": "研究", "agent_b": "社交", "drift": -0.02, "reason": "策略分歧" }, { "agent_a": "决策", "agent_b": "研究", "drift": +0.01, "reason": "优先级一致" } ] } 漂移规则很严格:每次对话最多变化±0.03(一次吵架不会让同事反目),下限0.10(再差也能说话),上限0.95(再好也保持距离),保留最近20条漂移记录(可以追溯关系是怎么走到今天的)。
RPG属性面板:真实数据映射成游戏属性
到这一步,Agent有了角色卡、性格、关系。但都是文字和数字,用户看不见。
解法是把真实数据库指标映射成RPG属性条:
-
病毒性(VRL):30天平均互动率 × 1000
-
速度(SPD):任务完成时间,越快越高
-
触达(RCH):对数归一化的总曝光量
-
信任(TRU):任务成功率 × 平均亲和力 × 2
-
智慧(WIS):log(记忆数量) × 平均置信度
-
创造力(CRE):草稿产出 × 通过率
每个Agent只显示4个相关属性。社交Agent显示病毒性、触达、速度、创造力;研究Agent显示智慧、信任、速度、创造力。
等级公式也很游戏化:
Level = min(15, floor(log2(记忆数 + 完成任务数×3 + 1)) + 1) log2让早期升级快、后期升级慢——跟游戏的经验曲线一样。
截屏2026-02-11 09.17.55
3D头像:$10搞定
所有人都在问"那些3D角色怎么做的"。
答案是Tripo AI,每月10刀。准备2D概念图 → 上传 → 配置参数(开4K贴图,开Smart Low Poly,关PBR)→ 生成 → 导出GLB。每个模型35积分,1-2分钟出结果,6个角色一共210积分。
前端用React Three Fiber渲染,体素风格地面和樱花树用InstancedMesh(不是单独的方块,性能极好),人物悬浮用Float组件,镜头用正弦函数驱动做钟摆式扫描。
整个视觉层的月成本:VPS 8刀,Tripo 10刀(模型做完就停),Vercel和Supabase免费层,LLM API大概5-15刀。加起来不到35刀/月。
我的几点感受
看完这整套系统,最让我触动的其实不是技术细节。
是作者说的一段话——
本来只是想"怎么让Agent更高效地执行任务"。但给它们加了3D头像、RPG属性、会进化的性格之后,打开控制面板的感觉完全变了。你开始在意研究Agent今天有没有升级,好奇研究和社交的亲和力是不是又降了,看到质检Agent犀利的审计报告会笑出声。
这基本上就是电子宠物。只不过这些宠物会帮你发推文、做调研、审流程,还会互相吵架。
我觉得这点被严重低估了。当你给系统"人格"的时候,你和它的关系就变了。你不再是"用一个工具",而是"管理一个团队"。这种转变会让你更愿意投入时间去优化它,因为你面对的不是一堆JSON和API调用,而是6个有名字、有性格、有成长曲线的角色。
另外几个技术层面的体会:
禁令驱动设计这个思路真的很实用。与其花大量精力定义Agent"应该做什么",不如先想清楚"绝对不能做什么"。Agent够聪明,给上下文就能交付,但不画红线它就会惹祸。
概率模拟自发性也很聪明。Agent之间的互动不是100%确定触发,而是有概率的。30%的概率去分析一条推文的表现,这比每次都分析更像真实团队的感觉。دالة الدخول الموحدة هذا النمط يستحق التذكر. في نظام متعدد الوكلاء، يمكن لمصادر مختلفة إنشاء مهام (واجهة برمجة التطبيقات، والمشغلات، والوكيل نفسه يقترح، وسلسلة ردود الفعل)، وإذا لم تكن هناك قناة معالجة موحدة، فمن السهل أن تنقطع العملية في منتصف الطريق.
إذا كنت ترغب في تجربتها بنفسك، يقترح المؤلف أن تبدأ بثلاثة وكلاء فقط - منسق ومنفذ ومدقق حسابات. ابدأ بكتابة بطاقات الأدوار، وابدأ بكتابة المحظورات.



