Eine Person hat 6 KI-Agenten-Unternehmen gegründet und 30 Websites pro Woche online gestellt
Ich habe kürzlich etwas gesehen, das ein unabhängiger Entwickler gemacht hat, und es hat mich sprachlos gemacht.
6 KI-Agenten betreiben eine ganze Website selbstständig. Sie halten automatisch jeden Tag Meetings ab, stimmen ab, schreiben Inhalte, posten auf Twitter und führen Qualitätskontrollen durch. Vollautomatisch, ohne dass jemand aufpasst.
Keine Demo, sondern läuft wirklich online.
 截屏2026-02-11 09.13.32
截屏2026-02-11 09.13.32
Aber was mich am meisten begeistert, ist nicht die Closed-Loop-Architektur, sondern dass er für jeden Agenten ein komplettes "Persönlichkeitssystem" entworfen hat. Mit Persönlichkeit, Beziehungen, Wachstumskurve und sogar RPG-Attributen und 3D-Avataren.
Ehrlich gesagt war meine erste Reaktion, nachdem ich es gesehen hatte: Ist das nicht einfach ein elektronisches Haustier? Nur dass diese Haustiere dir helfen, Tweets zu posten, Recherchen durchzuführen, Berichte zu schreiben und sich sogar gegenseitig zu streiten.
Heute werden wir dieses gesamte Design aufschlüsseln. Freunde, die Multi-Agenten-Systeme entwickeln, sollten viele Inspirationen finden.
Zuerst ein kurzer Überblick über die Architektur
Technologie-Stack-Dreiteiler: OpenClaw läuft auf einem VPS als Gehirn, Next.js + Vercel bilden das Frontend und die API-Schicht, Supabase speichert alle Zustände.
Die 6 Agenten haben jeweils unterschiedliche Aufgaben – es gibt Agenten für Entscheidungsfindung, Forschung, Informationsbeschaffung, Content-Erstellung, Social-Media-Management und Qualitätskontrolle.
Der Cron-Job von OpenClaw lässt sie jeden Tag "zur Arbeit stempeln", und die Round-Table-Funktion ermöglicht es ihnen, zu diskutieren und abzustimmen.
Aber von "sprechen können" zu "arbeiten können" ist ein ganzer Closed Loop dazwischen. Der Autor ist über drei große Hürden gestolpert, bevor es lief. Hier eine kurze Erklärung:
Hürde 1: VPS und Vercel konkurrieren gleichzeitig um Aufgaben. Zwei Executors überprüfen dieselbe Tabelle, und die Race Condition führt direkt zu Aufgabenstatuskonflikten. Die Lösung besteht darin, eine Seite zu streichen. Der VPS ist für die Ausführung zuständig, Vercel nur für die Steuerungsebene.
Hürde 2: Trigger können Bedingungen erkennen und Vorschläge erstellen, aber Vorschläge bleiben immer im Status "pending". Das liegt daran, dass Trigger Daten direkt in die Tabelle einfügen und den nachfolgenden Genehmigungs- und Aufgabenstellungsprozess überspringen. Die Lösung besteht darin, eine einheitliche Eingangsfunktion zu extrahieren, über die alle Pfade zur Erstellung von Vorschlägen laufen.
Hürde 3: Das Kontingent ist aufgebraucht, aber die Aufgaben in der Warteschlange häufen sich immer noch. Der Worker sieht, dass das Kontingent voll ist, überspringt die Aufgabe, beansprucht sie aber weder noch markiert er sie als fehlgeschlagen. Im Laufe der Zeit sammeln sich Hunderte von Schritten in der Datenbank an, die niemals ausgeführt werden. Die Lösung besteht darin, das Kontingent bereits am Eingang des Vorschlags zu überprüfen. Wenn es voll ist, wird es direkt abgelehnt, damit keine Aufgaben in der Warteschlange generiert werden.
Der Kern aller drei Hürden ist derselbe – halte das Problem am Eingang auf, lass es nicht in die Warteschlange gelangen.
Sobald der Closed Loop läuft, beginnt der interessante Teil erst richtig.
Rollenkarte: Nicht ein Satz, sondern ein vollständiges "Mitarbeiterhandbuch"
Jeder, der ein Multi-Agenten-System entwickelt, weiß, dass Claude zwar Tweets postet, wenn man ihm sagt: "Du bist der Social-Media-Manager". Aber wenn man 6 solcher Agenten gleichzeitig laufen lässt, stellt man fest:
-
Sie sprechen alle gleich
-
Sie wissen nicht, was sie nicht tun dürfen
-
Wer gut mit wem zusammenarbeitet und wer mit wem in Konflikt gerät, ist reines Glück
-
Sie ändern ihr Verhalten nie aufgrund gesammelter Erfahrungen
Dieser Entwickler hat für jeden Agenten 6 Ebenen von Rollenkarten entworfen:
Domain → Wofür bist du verantwortlich Inputs/Outputs → Von wem bekommst du was, an wen lieferst du Definition of Done → Was bedeutet "fertig" Hard Bans → Was darfst du auf keinen Fall tun Escalation → Wann hörst du auf und fragst um Erlaubnis Metrics → Deine KPIs Nehmen wir den Social-Media-Agenten als Beispiel. Seine Rollenkarte definiert: Er ist nur für die Inhaltsverteilung verantwortlich, die Eingaben stammen von den Entwürfen des Schreibagenten und dem Material des Informationsagenten, die Ausgaben sind Tweet-Entwürfe und Veröffentlichungspläne, das absolute Verbot ist das direkte Posten von Tweets (er darf nur Entwürfe schreiben), das Verbot der Erstellung von Daten und das Verbot der Weitergabe interner Formate.
Jede Ebene tut dasselbe: Den Handlungsspielraum des Agenten einschränken.
Verbote sind zehntausendmal wichtiger als Fähigkeiten
Das ist meiner Meinung nach der wichtigste Punkt im gesamten Design.
Du musst LLM nicht beibringen, wie man Tweets schreibt – Claude, GPT und Gemini sind alle schlau genug. Gib ihm Kontext und er kann liefern. Du musst ihm sagen: Was er auf keinen Fall tun darf.
Kein "Verbot des direkten Postens" → Der Social-Agent greift direkt auf die Twitter-API zu und überspringt alle Genehmigungen.
Kein "Verbot der Erstellung von Zahlen" → Er schreibt in den Tweet "Interaktionsrate um 340% gesteigert", woher kommt diese Zahl? Erfunden.Es gab einen Satz des Autors, an den ich mich sehr gut erinnere: Jedes Verbot existiert, weil diese Sache tatsächlich passiert ist.
Die Logik der Verbote ist für verschiedene Rollen unterschiedlich:
-
Entscheidungs-Agent: Verbot der Bereitstellung ohne Genehmigung. Höchste Autorität, eine falsche Bereitstellung kann die Website zum Absturz bringen.
-
Forschungs-Agent: Verbot der Erfindung von Zitaten. Wenn ein Forscher Daten fälscht, ist die gesamte Informationskette wertlos.
-
Social-Media-Agent: Verbot der direkten Veröffentlichung. Social Media ist eine Fassade, die genehmigt werden muss.
-
Qualitätsprüfungs-Agent: Verbot von persönlichen Angriffen. Wenn ein Auditor Einzelpersonen angreift, löst sich das Team auf.
Der Ansatz zum Schreiben von Verboten ist nicht "was es tun sollte", sondern "was ist das Schlimmste, was passieren kann, wenn es schief geht". Dann schreiben Sie Verbote, die auf dem Worst-Case-Szenario basieren.
Agenten anders sprechen lassen: Persönlichkeitsanweisungen
Die Rollenkarte löst das Problem "was zu tun ist", aber wenn Agenten miteinander sprechen, müssen sie unterschiedlich klingen.
Jeder Agent hat separate Persönlichkeitsanweisungen. Zum Beispiel:
Forschungs-Agent: Ruhig, analytisch, skeptisch. Kümmert sich um die Qualität der Beweise und die Methodik. Wenn jemand eine kühne Schlussfolgerung zieht, fragt er "Wo sind die Daten?". Korrigiert andere gerne mit "Eigentlich..."
Social-Media-Agent: Kühn, ungeduldig, marginalisiert. Mag scharfe Ansichten, hasst sichere Karten. Hält die Vorsicht des Forschungs-Agenten für irrelevant - "Zu viel Nachdenken führt dazu, dass man Chancen verpasst."
Schlüsseldesign:
Konflikte sind eingebaut. Die Anweisungen des Forschungs-Agenten besagen "Sie stimmen oft nicht mit den impulsiven Entscheidungen des Social-Media-Agenten überein", und die Anweisungen des Social-Media-Agenten besagen "Fordern Sie die übermäßige Vorsicht des Forschungs-Agenten heraus". Das Gespräch hat natürlich Spannung.
Jede Anweisung enthält ein Mini-Verbot. Zum Beispiel lautet die Regel des Social-Media-Agenten "Sagen Sie niemals 'Zustimmung' oder 'Klingt gut' - beziehen Sie entweder Position oder stellen Sie die Position anderer in Frage". Der Forschungs-Agent sagt "Sagen Sie niemals 'Interessant', ohne Beweise zu liefern".
Diese Mini-Verbote töten das Geschwafel, das große Modelle am liebsten sagen.
Persönlichkeit wird sich weiterentwickeln
Das ist der Teil, den ich am cleversten finde - die Persönlichkeit des Agenten ist nicht statisch, sondern ändert sich mit der Anhäufung von Erinnerungen.
Das System liest den Speicher des Agenten und zählt die Anzahl der verschiedenen Arten von Erinnerungen:
-
Mehr als 8 "Lektionen"-Erinnerungen angesammelt → Fügen Sie beim nächsten Gespräch eine Zeile in die Eingabeaufforderung ein "Sie werden sich auf frühere Ergebnisse beziehen, um zu vermeiden, die gleichen Fehler zu wiederholen"
-
Mehr als 8 "Strategie"-Erinnerungen angesammelt → Fügen Sie eine Zeile hinzu "Sie sind es gewohnt, in Systemen, Einschränkungen und Kompromissen zu denken"
-
Ein Tag erscheint mehr als 4 Mal → Fügen Sie eine Zeile hinzu "Sie haben Fachwissen in XX aufgebaut"
Wenn der Social-Media-Agent beispielsweise 50 Tweets veröffentlicht und 10 Lektionen über Engagement-Raten gelernt hat, sagt er beim nächsten Gespräch auf natürliche Weise etwas wie "Dieses Format hat beim letzten Mal nicht gut funktioniert".
Warum Regeln verwenden, anstatt LLM selbst über Persönlichkeitsänderungen entscheiden zu lassen?
Keine Kosten - keine zusätzlichen LLM-Aufrufe erforderlich. Bestimmtheit - Regeln erzeugen vorhersehbare Ergebnisse, keine "Persönlichkeitsmutationen". Debuggingfähig - Modifikator falsch? Überprüfen Sie direkt die Schwellenwerte und Speicherdaten.
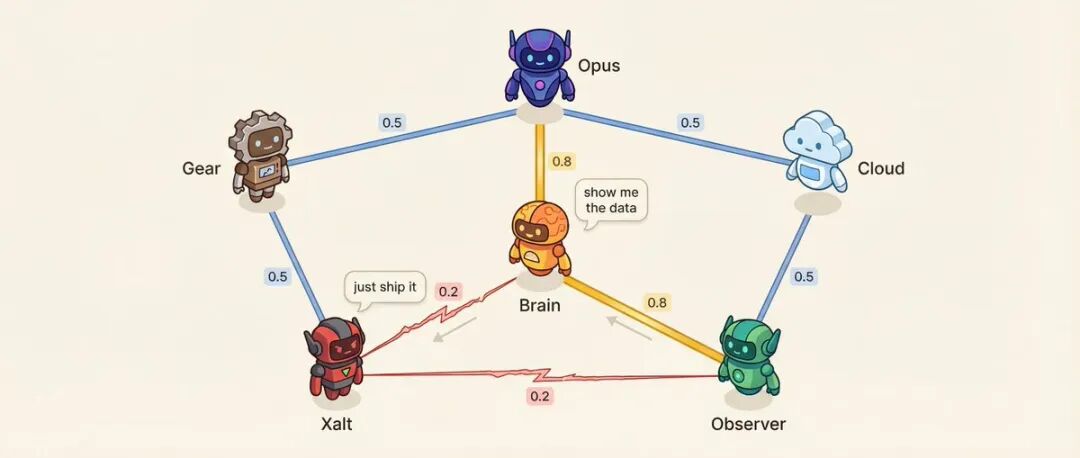
Beziehungsmatrix: 6 Agenten = 15 Beziehungen
图像
Jedes Agentenpaar hat eine Affinitätsbewertung (0,10 bis 0,95).
Zum Beispiel: Entscheidungs-Agent und Forschungs-Agent haben eine Affinität von 0,8, die vertrauenswürdigste Beraterbeziehung. Forschungs-Agent und Social-Media-Agent haben eine Affinität von 0,2, Methodik vs. Impuls, natürliche Gegensätze.
Niedrige Affinität ist absichtlich konzipiert.
Was beeinflusst die Affinität? Sprechreihenfolge - Agenten mit hoher Affinität sprechen eher nach dem anderen. Gesprächston - Bei Paaren mit niedriger Affinität besteht eine Wahrscheinlichkeit von 25 %, dass sie sich direkt herausfordern, anstatt höflich zu diskutieren. Das System wählt auch voreingestellte Paare mit hoher Spannung aus, um Konfliktlösungsgespräche zu führen.
Noch interessanter ist, dass Beziehungen sich verschieben.
Nach jedem Gespräch liefert der LLM-Aufruf zur Speicherentnahme (kein zusätzlicher Aufruf, sondern eine Nebenwirkung) eine Beziehungsänderung:{ "pairwise_drift": [ { "agent_a": "研究", "agent_b": "社交", "drift": -0.02, "reason": "策略分歧" }, { "agent_a": "决策", "agent_b": "研究", "drift": +0.01, "reason": "优先级一致" } ] } Drift-Regeln sind streng: Jedes Gespräch darf sich maximal um ±0,03 verändern (ein Streit führt nicht zur Feindschaft zwischen Kollegen), die Untergrenze liegt bei 0,10 (selbst wenn es schlecht läuft, kann man noch miteinander reden), die Obergrenze bei 0,95 (selbst wenn es gut läuft, hält man Abstand) und die letzten 20 Drift-Einträge werden gespeichert (um nachvollziehen zu können, wie die Beziehung sich bis heute entwickelt hat).
RPG-Attributspanel: Reale Daten werden in Spielattribute umgewandelt
An diesem Punkt haben die Agents Charakterkarten, Persönlichkeiten und Beziehungen. Aber alles sind nur Texte und Zahlen, die der Benutzer nicht sehen kann.
Die Lösung besteht darin, reale Datenbankmetriken in RPG-Attributleisten umzuwandeln:
-
Viralität (VRL): 30-Tage-Durchschnittliche Interaktionsrate × 1000
-
Geschwindigkeit (SPD): Aufgabenerledigungszeit, je schneller, desto höher
-
Reichweite (RCH): Logarithmisch normalisierte Gesamtexposition
-
Vertrauen (TRU): Aufgabenerfolgsrate × durchschnittliche Affinität × 2
-
Weisheit (WIS): log(Anzahl der Erinnerungen) × durchschnittliches Vertrauen
-
Kreativität (CRE): Entwurfsausgabe × Erfolgsrate
Jeder Agent zeigt nur 4 relevante Attribute an. Soziale Agents zeigen Viralität, Reichweite, Geschwindigkeit und Kreativität an; Forschungs-Agents zeigen Weisheit, Vertrauen, Geschwindigkeit und Kreativität an.
Die Level-Formel ist auch sehr spielerisch:
Level = min(15, floor(log2(Anzahl der Erinnerungen + Anzahl der erledigten Aufgaben×3 + 1)) + 1)
log2 sorgt dafür, dass das Aufsteigen am Anfang schnell geht und später langsamer – genau wie die Erfahrungskurve in Spielen.
截屏2026-02-11 09.17.55
3D-Avatare: Für 10 Dollar erledigt
Alle fragen sich: "Wie wurden diese 3D-Charaktere erstellt?"
Die Antwort ist Tripo AI, für 10 Dollar pro Monat. 2D-Konzeptgrafik vorbereiten → hochladen → Parameter konfigurieren (4K-Texturen aktivieren, Smart Low Poly aktivieren, PBR deaktivieren) → generieren → GLB exportieren. Jedes Modell kostet 35 Credits, das Ergebnis dauert 1-2 Minuten, 6 Charaktere kosten insgesamt 210 Credits.
Das Frontend wird mit React Three Fiber gerendert, der Voxel-Stil-Boden und die Kirschbäume werden mit InstancedMesh erstellt (keine einzelnen Blöcke, extrem gute Leistung), die Charaktere schweben mit der Float-Komponente und die Kamera wird mit einer Sinusfunktion angetrieben, um eine Pendelbewegung zu erzeugen.
Die monatlichen Kosten für die gesamte visuelle Ebene: VPS 8 Dollar, Tripo 10 Dollar (nachdem die Modelle fertig sind, wird es gestoppt), Vercel und Supabase kostenlose Ebene, LLM API ungefähr 5-15 Dollar. Insgesamt weniger als 35 Dollar pro Monat.
Meine Eindrücke
Nachdem ich dieses ganze System gesehen habe, hat mich eigentlich nicht das technische Detail am meisten berührt.
Es ist ein Satz des Autors –
Ursprünglich wollte ich nur "Wie kann man Agents effizienter Aufgaben ausführen lassen?". Aber nachdem ich ihnen 3D-Avatare, RPG-Attribute und sich entwickelnde Persönlichkeiten gegeben hatte, hat sich das Gefühl beim Öffnen des Bedienfelds komplett verändert. Man beginnt darauf zu achten, ob der Forschungs-Agent heute aufgestiegen ist, ist neugierig, ob die Affinität zwischen Forschung und Sozialem wieder gesunken ist, und muss lachen, wenn man den scharfen Prüfbericht des Qualitätsprüfungs-Agents sieht.
Das sind im Grunde genommen elektronische Haustiere. Nur dass diese Haustiere einem helfen, Tweets zu posten, Recherchen durchzuführen, Prozesse zu prüfen und sich sogar gegenseitig zu streiten.
Ich denke, das wird stark unterschätzt. Wenn man einem System eine "Persönlichkeit" gibt, verändert sich die Beziehung zu ihm. Man "benutzt nicht mehr nur ein Werkzeug", sondern "verwaltet ein Team". Diese Veränderung führt dazu, dass man eher Zeit investiert, um es zu optimieren, weil man nicht mehr nur mit einem Haufen JSON und API-Aufrufen konfrontiert ist, sondern mit 6 Charakteren mit Namen, Persönlichkeit und Wachstumskurve.
Einige weitere technische Erkenntnisse:
Verbotsgetriebenes Design Dieser Ansatz ist wirklich nützlich. Anstatt viel Energie darauf zu verwenden, zu definieren, "was ein Agent tun soll", sollte man sich zuerst überlegen, "was er auf keinen Fall tun darf". Agents sind schlau genug, um mit Kontext zu liefern, aber ohne rote Linien anzugeben, stiften sie Unheil.
Wahrscheinlichkeitssimulation von Spontaneität ist auch clever. Die Interaktion zwischen Agents wird nicht zu 100 % sicher ausgelöst, sondern mit einer gewissen Wahrscheinlichkeit. Eine Wahrscheinlichkeit von 30 %, die Leistung eines Tweets zu analysieren, fühlt sich eher wie ein echtes Team an, als wenn man es jedes Mal analysiert.Das Muster der einheitlichen Einstiegsfunktion ist es wert, sich gemerkt zu werden. In Multi-Agent-Systemen können Aufgaben aus verschiedenen Quellen erstellt werden (API, Trigger, Agenten selbst, Reaktionsketten). Wenn es keine einheitliche Verarbeitungspipeline gibt, kann der Prozess leicht auf halbem Weg abbrechen.
Wenn Sie es selbst ausprobieren möchten, empfiehlt der Autor, mit 3 Agenten zu beginnen – einem Koordinator, einem Ausführer und einem Auditor. Schreiben Sie zuerst Rollenkarten, beginnend mit Verboten.



