Una persona creó 6 empresas de Agentes de IA y lanzó 30 sitios web en una semana
Recientemente vi algo hecho por un desarrollador independiente que me dejó en silencio.
6 Agentes de IA, operando un sitio web completo por sí mismos. Reuniones automáticas diarias, votaciones, redacción de contenido, publicación en Twitter, control de calidad. Todo automático, sin que nadie lo supervise.
No es una demo, está funcionando en línea de verdad.
 截屏2026-02-11 09.13.32
截屏2026-02-11 09.13.32
Pero lo que más me impactó no fue la arquitectura de circuito cerrado, sino que diseñó un "sistema de personalidad" completo para cada Agente. Con personalidad, relaciones, curva de crecimiento e incluso paneles de atributos RPG y avatares 3D.
Para ser honesto, mi primera reacción después de verlo fue: ¿no son estas mascotas electrónicas? Solo que estas mascotas te ayudan a tuitear, investigar, escribir informes e incluso pelearse entre ellas.
Hoy vamos a desglosar todo este diseño. Los amigos que hacen sistemas multi-Agente deberían encontrar mucha inspiración.
Repasemos rápidamente la arquitectura
El conjunto de herramientas técnicas: OpenClaw se ejecuta en un VPS como cerebro, Next.js + Vercel hacen el frontend y la capa API, Supabase almacena todo el estado.
Los 6 Agentes tienen diferentes divisiones del trabajo: algunos toman decisiones, otros investigan, otros recopilan inteligencia, otros escriben contenido, otros gestionan las redes sociales y otros hacen control de calidad.
El cron job de OpenClaw les permite "fichar" todos los días, y la función de mesa redonda les permite discutir y votar.
Pero desde "poder hablar" hasta "poder trabajar", hay todo un circuito cerrado de diferencia. El autor tropezó con tres grandes obstáculos antes de que funcionara. Aquí hay una breve descripción:
Obstáculo 1: VPS y Vercel compiten por las tareas al mismo tiempo. Dos ejecutores consultan la misma tabla, y las condiciones de carrera conducen directamente a conflictos de estado de la tarea. La solución es cortar un lado, el VPS se encarga de la ejecución y Vercel solo hace el plano de control.
Obstáculo 2: Los activadores pueden detectar condiciones y crear propuestas, pero las propuestas siempre se quedan en pendiente. Porque los activadores insertan datos directamente en la tabla, omitiendo los procesos posteriores de aprobación y creación de tareas. La solución es extraer una función de entrada unificada, y todas las rutas para crear propuestas pasan por la misma.
Obstáculo 3: La cuota se ha agotado, pero las tareas en cola siguen acumulándose frenéticamente. El Worker ve que la cuota está llena y se la salta, sin reclamarla ni marcarla como fallida. Con el tiempo, la base de datos acumula cientos de pasos que nunca se ejecutarán. La solución es comprobar la cuota en la entrada de la propuesta, y si está llena, rechazarla directamente, para que no genere tareas en cola.
El núcleo de los tres obstáculos es lo mismo: detener el problema en la puerta, no dejar que entre en la cola.
Una vez que el circuito cerrado está en funcionamiento, la parte interesante realmente comienza.
Tarjeta de rol: no es una frase, es un "manual del empleado" completo
Las personas que hacen sistemas multi-Agente saben que si le dices a Claude "eres el gerente de redes sociales", ciertamente tuiteará. Pero si ejecutas 6 Agentes como este al mismo tiempo, encontrarás que:
-
Todos hablan con el mismo tono
-
No saben lo que no deberían hacer
-
Quién trabaja bien con quién, quién entra en conflicto con quién, depende de la suerte
-
Nunca cambiarán su comportamiento debido a la experiencia acumulada
Este desarrollador diseñó 6 capas de tarjetas de rol para cada Agente:
Dominio → De qué eres responsable Entradas/Salidas → De quién obtienes cosas, a quién las entregas Definición de Hecho → Qué significa "hecho" Prohibiciones Duras → Qué es lo que absolutamente no puedes hacer Escalada → Cuándo detenerse y pedir instrucciones Métricas → Tu KPI Tomando como ejemplo el Agente de redes sociales, su tarjeta de rol define: solo es responsable de la distribución de contenido, la entrada proviene de los borradores del Agente de escritura y los materiales del Agente de inteligencia, la salida son borradores de tuits y planes de publicación, la prohibición estricta es publicar directamente tuits (solo puede escribir borradores), prohibido inventar datos, prohibido revelar formatos internos.
Cada capa está haciendo lo mismo: reducir el espacio de comportamiento del Agente.
Las prohibiciones son un millón de veces más importantes que las habilidades
Esta es la opinión más esencial de todo el diseño.
No necesitas enseñarle a LLM cómo escribir tuits: Claude, GPT, Gemini son lo suficientemente inteligentes. Dale contexto y puede entregar. Lo que necesitas decirle es: qué es lo que absolutamente no puede hacer.
Sin "prohibido publicar directamente" → El Agente de redes sociales llama directamente a la API de Twitter, omitiendo todas las aprobaciones.
Sin "prohibido inventar números" → Escribirá en el tuit "la tasa de interacción aumentó un 340%", ¿de dónde salió este número? Inventado.El autor dijo una frase que recuerdo muy bien: Cada prohibición existe porque esto realmente sucedió.
La lógica de las prohibiciones es diferente para cada rol:
-
Agente de Decisión: Prohibido el despliegue sin aprobación. Tiene la máxima autoridad, un despliegue incorrecto puede arruinar el sitio web.
-
Agente de Investigación: Prohibido inventar citas. Si alguien que investiga falsifica datos, toda la cadena de información se arruina.
-
Agente Social: Prohibido publicar directamente. Las redes sociales son la fachada, deben ser aprobadas.
-
Agente de Control de Calidad: Prohibido los ataques personales. Si un auditor ataca a alguien, el equipo se disuelve.
La idea al escribir prohibiciones no es "qué debería hacer", sino "¿qué es lo peor que podría pasar si lo arruina?". Luego, escribir la prohibición en función del peor escenario.
Hacer que los Agentes hablen diferente: Instrucciones de personalidad
La tarjeta de rol resuelve el problema de "qué hacer", pero cuando los Agentes dialogan entre sí, también necesitan sonar diferentes.
Cada Agente tiene instrucciones de personalidad separadas. Por ejemplo:
Agente de Investigación: Calmado, analítico, escéptico. Se preocupa por la calidad de la evidencia y la metodología. Si alguien dice una conclusión audaz, preguntará "¿dónde están los datos?". Al corregir a otros, le gusta decir "en realidad..."
Agente Social: Audaz, impaciente, marginal. Le gustan los puntos de vista agudos, odia las apuestas seguras. No está de acuerdo con la actitud cautelosa del Agente de Investigación: "Pensar demasiado te hará perder la oportunidad".
Diseño clave:
El conflicto está escrito. Las instrucciones del Agente de Investigación dicen "a menudo no estás de acuerdo con las decisiones impulsivas del Agente Social", las instrucciones del Agente Social dicen "desafía la excesiva cautela del Agente de Investigación". La conversación naturalmente tiene tensión.
Cada instrucción tiene una mini-prohibición. Por ejemplo, la regla del Agente Social es "nunca digas 'estoy de acuerdo' o 'suena bien' - o tomas una posición o cuestionas la posición de los demás". El Agente de Investigación es "nunca digas 'interesante' sin hacer un seguimiento con evidencia".
Estas mini-prohibiciones eliminan las tonterías que a los modelos grandes les encanta decir.
La personalidad evoluciona
Esta es la parte que me parece más ingeniosa: la personalidad del Agente no es estática, cambia a medida que se acumulan los recuerdos.
El sistema lee la base de datos de memoria del Agente y cuenta el número de diferentes tipos de recuerdos:
-
Acumuló más de 8 recuerdos de tipo "lección" → La próxima vez que hable, agregue una línea en el prompt "Te referirás a resultados pasados para evitar repetir errores"
-
Acumuló más de 8 recuerdos de tipo "estrategia" → Agregue una línea "Estás acostumbrado a pensar en términos de pensamiento sistémico, restricciones y compensaciones"
-
Una etiqueta aparece más de 4 veces → Agregue una línea "Has acumulado experiencia en XX"
Por ejemplo, si el Agente Social publica 50 tuits y acumula 10 lecciones aprendidas sobre las tasas de interacción, naturalmente dirá algo como "Ese formato no funcionó bien la última vez" en su próxima conversación.
¿Por qué usar reglas en lugar de dejar que el LLM decida por sí mismo los cambios de personalidad?
Costo cero: no requiere llamadas adicionales al LLM. Determinismo: las reglas producen resultados predecibles, sin "cambios repentinos de personalidad". Depurable: ¿el modificador es incorrecto? Simplemente verifique el umbral y los datos de la memoria.
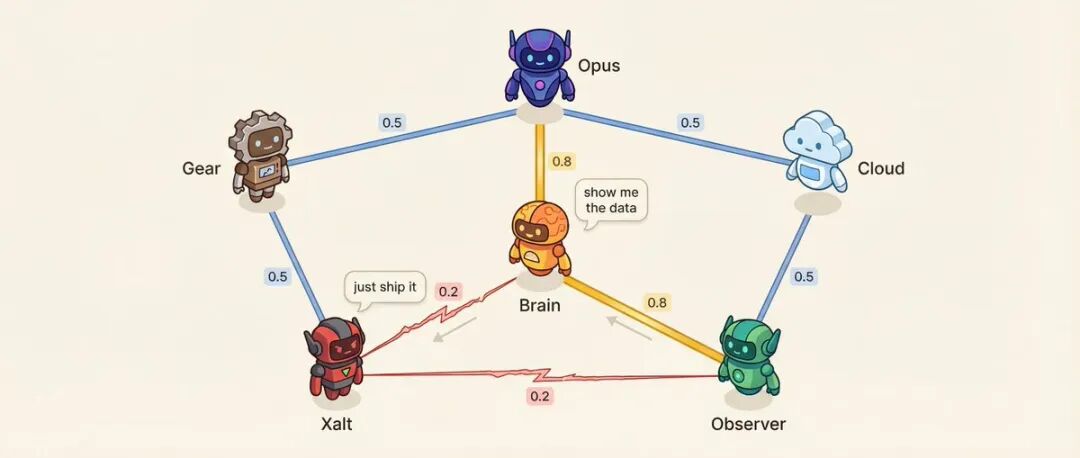
Matriz de relaciones: 6 Agentes = 15 pares de relaciones
Imagen
Cada par de Agentes tiene un puntaje de afinidad (0.10 a 0.95).
Por ejemplo: el Agente de Decisión y el Agente de Investigación tienen una afinidad de 0.8, la relación de asesor más confiable. El Agente de Investigación y el Agente Social tienen una afinidad de 0.2, metodología vs. impulso, naturalmente opuestos.
La baja afinidad está diseñada a propósito.
¿Qué afecta la afinidad? Orden de hablar: es más probable que los que tienen alta afinidad hablen después del otro. Tono de conversación: los pares de baja afinidad tienen un 25% de probabilidad de desafiar directamente en lugar de discutir cortésmente. El sistema también elegirá pares de alta tensión preestablecidos para realizar conversaciones de resolución de conflictos.
Lo que es aún más interesante es que las relaciones cambian.
Después de cada conversación, la llamada LLM de extracción de memoria (no una llamada adicional, es una salida incidental) dará un cambio de relación:`{ \Vale la pena recordar este patrón. En un sistema multi-agente, varias fuentes pueden crear tareas (API, activadores, el propio Agente las propone, cadenas de reacción), si no hay un canal de procesamiento unificado, el flujo puede interrumpirse fácilmente a la mitad.
Si quieres probarlo por ti mismo, el autor sugiere comenzar con 3 Agentes: un coordinador, un ejecutor y un auditor. Primero escribe las tarjetas de rol, comenzando con las prohibiciones.



