Un gars a créé 6 entreprises d'agents IA et a mis en ligne 30 sites web en une semaine
Récemment, j'ai vu le travail d'un développeur indépendant qui m'a laissé sans voix.
6 agents IA, gérant chacun un site web complet. Réunions automatiques quotidiennes, votes, rédaction de contenu, publication de tweets, contrôle qualité. Entièrement automatisé, sans surveillance humaine.
Ce n'est pas une démo, c'est en production réelle.
 截屏2026-02-11 09.13.32
截屏2026-02-11 09.13.32
Mais ce qui m'a le plus fasciné, ce n'est pas l'architecture en boucle fermée, mais le fait qu'il ait conçu un "système de personnalité" complet pour chaque agent. Avec une personnalité, des relations, une courbe de croissance, et même un panneau d'attributs RPG et un avatar 3D.
Honnêtement, ma première réaction après avoir vu ça a été : n'est-ce pas juste un animal de compagnie électronique ? Sauf que ces animaux de compagnie vous aident à tweeter, à faire des recherches, à rédiger des rapports et même à se disputer entre eux.
Aujourd'hui, je vais décortiquer cette conception. Les personnes qui travaillent sur des systèmes multi-agents devraient y trouver beaucoup d'inspiration.
Passons rapidement en revue l'architecture
La pile technologique comprend trois éléments : OpenClaw s'exécute sur un VPS en tant que cerveau, Next.js + Vercel gèrent le frontend et la couche API, et Supabase stocke tous les états.
Les 6 agents ont chacun une spécialisation : prise de décision, recherche, renseignement, rédaction de contenu, gestion des médias sociaux et contrôle qualité.
Le cron job d'OpenClaw leur permet de "pointer" chaque jour, et la fonction de table ronde leur permet de discuter et de voter.
Mais entre "être capable de parler" et "être capable de travailler", il y a tout un cycle complet. L'auteur a rencontré trois gros problèmes avant de pouvoir le faire fonctionner. Voici un bref aperçu :
Problème n° 1 : VPS et Vercel se disputent les tâches. Deux exécutants interrogent la même table, et les conditions de concurrence entraînent directement des conflits d'état des tâches. La solution consiste à supprimer un côté : le VPS est responsable de l'exécution, et Vercel ne fait que contrôler.
Problème n° 2 : Les déclencheurs peuvent détecter les conditions et créer des propositions, mais les propositions restent toujours en attente. En effet, les déclencheurs insèrent directement des données dans la table, en sautant les processus d'approbation et de création de tâches ultérieurs. La solution consiste à extraire une fonction d'entrée unifiée, et tous les chemins de création de propositions passent par la même fonction.
Problème n° 3 : Le quota est épuisé, mais les tâches en attente continuent de s'accumuler. Le Worker voit que le quota est atteint et saute la tâche, sans la revendiquer ni la marquer comme échouée. Au fil du temps, des centaines d'étapes qui ne seront jamais exécutées s'accumulent dans la base de données. La solution consiste à vérifier le quota à l'entrée de la proposition. S'il est atteint, la proposition est directement rejetée, ce qui empêche la création de tâches en attente.
Le cœur de ces trois problèmes est le même : bloquer les problèmes à l'entrée, ne pas les laisser entrer dans la file d'attente.
Une fois la boucle fermée opérationnelle, la partie intéressante commence vraiment.
Fiche de rôle : pas une simple phrase, mais un "manuel de l'employé" complet
Les personnes qui travaillent sur des systèmes multi-agents savent que si vous dites à Claude "vous êtes le responsable des médias sociaux", il publiera effectivement des tweets. Mais si vous exécutez 6 agents de ce type en même temps, vous constaterez que :
-
Ils parlent tous de la même manière
-
Ils ne savent pas ce qu'ils ne devraient pas faire
-
La collaboration et les conflits sont purement aléatoires
-
Leur comportement ne change jamais en fonction de l'expérience accumulée
Ce développeur a conçu 6 couches de fiches de rôle pour chaque agent :
Domain → De quoi êtes-vous responsable Inputs/Outputs → De qui recevez-vous des informations et à qui les livrez-vous Definition of Done → Qu'est-ce qui est considéré comme "terminé" Hard Bans → Ce que vous ne devez absolument pas faire Escalation → Quand devez-vous vous arrêter et demander des instructions Metrics → Vos KPI Prenons l'exemple de l'agent des médias sociaux. Sa fiche de rôle définit : qu'il est uniquement responsable de la distribution du contenu, que les entrées proviennent des brouillons de l'agent de rédaction et du matériel de l'agent de renseignement, que les sorties sont des brouillons de tweets et des plans de publication, qu'il est strictement interdit de publier directement des tweets (uniquement d'écrire des brouillons), d'inventer des données et de divulguer des formats internes.
Chaque couche fait la même chose : réduire l'espace comportemental de l'agent.
Les interdictions sont un million de fois plus importantes que les capacités
C'est le point de vue le plus essentiel de toute la conception, selon moi.
Vous n'avez pas besoin d'apprendre à LLM comment écrire des tweets : Claude, GPT et Gemini sont suffisamment intelligents. Donnez-lui le contexte et il peut livrer. Ce que vous devez lui dire, c'est : ce qu'il ne faut absolument pas faire.
Pas d'"interdiction de publier directement" → L'agent des médias sociaux appelle directement l'API Twitter, en sautant toutes les approbations.
Pas d'"interdiction d'inventer des chiffres" → Il écrira dans le tweet "augmentation du taux d'engagement de 340 %", d'où viennent ces chiffres ? Inventés.Pas d'interdiction de divulguer le format interne → Il a publié des choses comme [tool:crawl_result path=/tmp/...] dans un tweet.
L'auteur a dit une phrase dont je me souviens très bien : Chaque interdiction existe parce que cet événement s'est réellement produit.
La logique des interdictions est également différente selon les rôles :
-
Agent de décision : Interdiction de déploiement sans approbation. Autorisation maximale, un seul déploiement erroné peut faire planter le site web.
-
Agent de recherche : Interdiction d'inventer des citations. Si un chercheur falsifie des données, toute la chaîne d'information est ruinée.
-
Agent social : Interdiction de publication directe. Les médias sociaux sont une vitrine, ils doivent être approuvés.
-
Agent de contrôle qualité : Interdiction d'attaques personnelles. Si un auditeur attaque une personne, l'équipe se désagrège.
L'idée derrière l'écriture des interdictions n'est pas "ce qu'il devrait faire", mais "quel est le pire qui puisse arriver s'il se trompe". Ensuite, écrivez des interdictions pour le pire des cas.
Faire parler les Agents différemment : Instructions de personnalité
La carte de rôle résout le problème de "quoi faire", mais lors des conversations entre Agents, il faut aussi qu'ils aient l'air différents.
Chaque Agent a des instructions de personnalité distinctes. Par exemple :
Agent de recherche : Calme, analytique, sceptique. Se soucie de la qualité des preuves et de la méthodologie. Si quelqu'un fait une conclusion audacieuse, il demandera "Où sont les données". Aime dire "En fait..." lorsqu'il corrige les autres.
Agent social : Audacieux, impatient, marginal. Aime les points de vue tranchants, déteste les solutions de sécurité. Ne tient pas compte de l'attitude prudente de l'Agent de recherche - "Trop réfléchir fait rater des occasions."
Conception clé :
Le conflit est intégré. Les instructions de l'Agent de recherche indiquent "Vous êtes souvent en désaccord avec les décisions impulsives de l'Agent social", et les instructions de l'Agent social indiquent "Remettez en question la prudence excessive de l'Agent de recherche". La conversation a naturellement de la tension.
Chaque instruction contient une micro-interdiction. Par exemple, la règle de l'Agent social est "Ne jamais dire 'D'accord' ou 'Ça a l'air bien' - soit prendre position, soit remettre en question la position des autres". L'Agent de recherche est "Ne jamais dire 'Intéressant' sans donner suite avec des preuves".
Ces micro-interdictions tuent les bêtises que les grands modèles aiment le plus dire.
La personnalité évolue
C'est la partie que je trouve la plus ingénieuse : la personnalité de l'Agent n'est pas statique, elle change avec l'accumulation de souvenirs.
Le système lit la base de données de mémoire de l'Agent et compte le nombre de différents types de souvenirs :
-
Accumulation de plus de 8 souvenirs de type "leçon" → La prochaine fois qu'il y aura une conversation, ajoutez une ligne dans l'invite "Vous vous référerez aux résultats passés pour éviter de répéter les mêmes erreurs"
-
Accumulation de plus de 8 souvenirs de type "stratégie" → Ajoutez une ligne "Vous êtes habitué à penser avec une pensée systémique, des contraintes et des compromis"
-
Une étiquette apparaît plus de 4 fois → Ajoutez une ligne "Vous avez accumulé une expertise dans XX"
Par exemple, si l'Agent social publie 50 tweets et accumule 10 leçons sur les taux d'engagement, il dira naturellement la prochaine fois "Ce type de format n'a pas bien fonctionné la dernière fois".
Pourquoi utiliser des règles au lieu de laisser le LLM décider lui-même des changements de personnalité ?
Coût nul - pas besoin d'appels LLM supplémentaires. Déterminisme - les règles produisent des résultats prévisibles, pas de "changement de personnalité soudain". Débogable - le modificateur est incorrect ? Vérifiez directement les seuils et les données de mémoire.
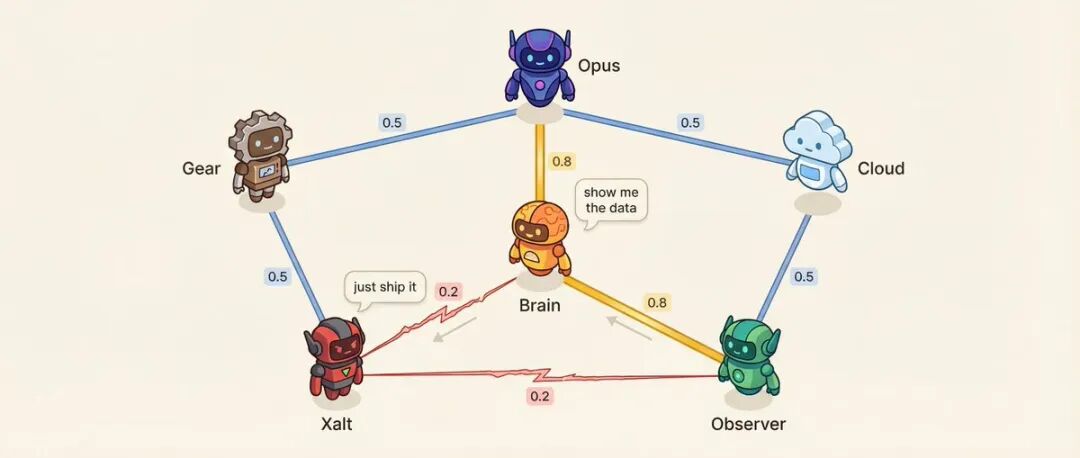
Matrice de relations : 6 Agents = 15 paires de relations
Image
Chaque paire d'Agents a un score d'affinité (0,10 à 0,95).
Par exemple : L'Agent de décision et l'Agent de recherche ont une affinité de 0,8, la relation de conseiller la plus fiable. L'Agent de recherche et l'Agent social ont une affinité de 0,2, méthodologie vs impulsion, naturellement opposés.
Une faible affinité est intentionnellement conçue.
Qu'est-ce que l'affinité affecte ? Ordre de prise de parole - ceux qui ont une affinité élevée sont plus susceptibles de prendre la parole après l'autre. Ton de la conversation - pour les paires à faible affinité, il y a 25 % de chances qu'il y ait un défi direct au lieu d'une discussion polie. Le système choisira également des paires préréglées à haute tension pour mener des conversations de résolution de conflits.
Plus intéressant encore, les relations dérivent.
Après chaque conversation, l'appel LLM d'extraction de mémoire (pas un appel supplémentaire, c'est une sortie accessoire) donnera des changements de relation : `{ **Fonction d'entrée unifiée**, ce modèle mérite d'être retenu. Dans un système multi-agents, diverses sources peuvent créer des tâches (API, déclencheurs, l'Agent lui-même, chaînes de réaction). S'il n'y a pas de pipeline de traitement unifié, le processus peut facilement s'interrompre à mi-chemin.
Si vous voulez essayer vous-même, l'auteur suggère de commencer avec 3 Agents, c'est suffisant : un coordinateur, un exécuteur et un auditeur. Commencez par écrire les fiches de rôle, en commençant par les interdictions.



