Iemand heeft 6 AI Agent-bedrijven opgezet en 30 websites in één week gelanceerd
Ik zag onlangs iets dat een onafhankelijke ontwikkelaar had gemaakt, en ik was er stil van.
6 AI Agents, die zelf een hele website beheren. Ze vergaderen automatisch, stemmen, schrijven content, tweeten en doen kwaliteitscontroles. Volledig automatisch, zonder dat er iemand op let.
Geen demo, het draait echt online.
 截屏2026-02-11 09.13.32
截屏2026-02-11 09.13.32
Maar wat me het meest opwond, was niet de closed-loop architectuur, maar het feit dat hij voor elke Agent een compleet 'persoonlijkheidssysteem' had ontworpen. Met persoonlijkheid, relaties, een groeicurve en zelfs RPG-attribuutpanelen en 3D-avatars.
Eerlijk gezegd was mijn eerste reactie na het bekijken ervan: is dit niet gewoon een elektronisch huisdier? Alleen helpen deze huisdieren je met het tweeten, doen ze onderzoek, schrijven ze rapporten en maken ze ruzie met elkaar.
Vandaag bespreken we deze hele set ontwerpen, en vrienden die multi-Agent-systemen maken, zouden er veel inspiratie uit moeten halen.
Eerst een snelle blik op de architectuur
De technische stack bestaat uit drie onderdelen: OpenClaw draait op een VPS als het brein, Next.js + Vercel doen de frontend- en API-laag en Supabase slaat alle statussen op.
De 6 Agents hebben elk hun eigen specialisatie: er zijn er die beslissingen nemen, onderzoek doen, informatie verzamelen, content schrijven, sociale media beheren en kwaliteitscontroles uitvoeren.
De cron job van OpenClaw laat ze elke dag 'inchecken', en de ronde tafel-functie laat ze discussiëren en stemmen.
Maar van 'kunnen praten' tot 'kunnen werken' zit een hele closed-loop tussen. De auteur heeft drie grote valkuilen doorstaan voordat het werkte, hier is een korte uitleg:
Valkuil 1: VPS en Vercel strijden tegelijkertijd om taken. Twee executors controleren dezelfde tabel, en de raceconditie veroorzaakt direct conflicten in de taakstatus. De oplossing is om één kant te schrappen, de VPS is verantwoordelijk voor de uitvoering en Vercel doet alleen het controlepaneel.
Valkuil 2: Triggers kunnen voorwaarden detecteren en voorstellen aanmaken, maar voorstellen blijven altijd in de wachtstand staan. Omdat triggers direct data in de tabel invoegen, wordt het daaropvolgende goedkeurings- en taakaanmaakproces overgeslagen. De oplossing is om een uniforme ingangsfunctie te extraheren, zodat alle paden voor het aanmaken van voorstellen dezelfde volgen.
Valkuil 3: Het quotum is opgebruikt, maar de taken in de wachtrij stapelen zich nog steeds op. De Worker ziet dat het quotum vol is en slaat het over, claimt het niet en markeert het niet als mislukt, waardoor er in de loop van de tijd honderden stappen in de database terechtkomen die nooit zullen worden uitgevoerd. De oplossing is om het quotum te controleren bij de ingang van het voorstel, en als het vol is, direct te weigeren, zodat er geen taken in de wachtrij worden gegenereerd.
De kern van de drie valkuilen is hetzelfde: houd het tegen bij de ingang, laat het probleem niet in de wachtrij komen.
Nadat de closed-loop werkt, begint het interessante deel pas echt.
Rolkaart: niet één zin, maar een complete 'personeelshandleiding'
Mensen die multi-Agent-systemen maken, weten dat als je tegen Claude zegt 'je bent de social media manager', hij inderdaad tweets zal plaatsen. Maar als je 6 van dergelijke Agents tegelijkertijd laat draaien, zul je merken:
-
Ze praten allemaal op dezelfde manier
-
Ze weten niet wat ze niet mogen doen
-
Wie goed samenwerkt en wie conflicteert, is puur geluk
-
Ze zullen hun gedrag nooit veranderen op basis van opgedane ervaring
Deze ontwikkelaar heeft 6 lagen rolkaarten ontworpen voor elke Agent:
Domain → Waar ben je verantwoordelijk voor Inputs/Outputs → Van wie krijg je dingen en aan wie lever je ze Definition of Done → Wat betekent 'klaar' Hard Bans → Wat mag je absoluut niet doen Escalation → Wanneer stop je en vraag je om instructies Metrics → Je KPI's Neem bijvoorbeeld de social media Agent, zijn rolkaart definieert: alleen verantwoordelijk voor contentdistributie, input komt van de concepten van de schrijf-Agent en het materiaal van de informatie-Agent, output is een tweetconcept en een publicatieplan, een hard verbod is om niet direct te tweeten (alleen concepten schrijven), geen data verzinnen, geen interne formaten lekken.
Elke laag doet hetzelfde: de gedragsruimte van de Agent verkleinen.
Verboden zijn tienduizend keer belangrijker dan vaardigheden
Dit is het meest essentiële punt in het hele ontwerp, naar mijn mening.
Je hoeft LLM niet te leren hoe je tweets schrijft - Claude, GPT, Gemini zijn allemaal slim genoeg. Geef het context en het kan leveren. Wat je het moet vertellen is: wat je absoluut niet mag doen.
Geen 'verbod op direct publiceren' → De social Agent roept direct de Twitter API aan en slaat alle goedkeuringen over.
Geen 'verbod op het verzinnen van cijfers' → Het zal in de tweet schrijven 'de interactieratio is met 340% gestegen', waar komt dat cijfer vandaan? Verzonnen. De auteur zei iets dat ik me heel goed herinner: Elk verbod bestaat omdat het echt is gebeurd.
De logica van verboden verschilt ook per rol:
-
Beslissingsagent: Verbied implementatie zonder goedkeuring. De hoogste autoriteit, een verkeerde implementatie kan de website platleggen
-
Onderzoeksagent: Verbied het verzinnen van citaten. Als onderzoekers gegevens vervalsen, is de hele informatieketen waardeloos
-
Sociale agent: Verbied directe publicatie. Sociale media zijn de etalage, ze moeten worden goedgekeurd
-
Kwaliteitscontroleagent: Verbied persoonlijke aanvallen. Als auditors individuen aanvallen, valt het team uit elkaar
De manier om verboden te schrijven is niet "wat het zou moeten doen", maar "wat is het ergste dat kan gebeuren als het misgaat". Schrijf vervolgens verboden voor het worstcasescenario.
Laat agenten anders praten: persoonlijkheidsinstructies
De rolkaart lost het probleem van "wat te doen" op, maar wanneer agenten met elkaar praten, moeten ze anders klinken.
Elke agent heeft afzonderlijke persoonlijkheidsinstructies. Bijvoorbeeld:
Onderzoeksagent: Kalm, analytisch, sceptisch. Geeft om de kwaliteit van het bewijs en de methodologie. Als iemand een gedurfde conclusie trekt, vraagt hij "waar zijn de gegevens". Corrigeert graag anderen door te zeggen "eigenlijk..."
Sociale agent: Gedurfd, ongeduldig, gemarginaliseerd. Houdt van scherpe meningen, haat veilige kaarten. Neemt de voorzichtigheid van de onderzoeksagent niet serieus - "Te veel nadenken mist de kans."
Belangrijkste ontwerp:
Conflict is ingebouwd. De instructies van de onderzoeksagent zeggen "je bent het vaak niet eens met de impulsieve beslissingen van de sociale agent", en de instructies van de sociale agent zeggen "daag de overdreven voorzichtigheid van de onderzoeksagent uit". Het gesprek heeft van nature spanning.
Elke instructie bevat een miniverbod. De regel voor de sociale agent is bijvoorbeeld "zeg nooit 'eens' of 'klinkt goed' - neem ofwel een standpunt in, of daag het standpunt van anderen uit". De onderzoeksagent is "zeg nooit 'interessant' zonder bewijs te leveren."
Deze miniverboden doden de onzin die grote modellen graag zeggen.
Persoonlijkheid evolueert
Dit is het meest ingenieuze deel, vind ik - de persoonlijkheid van de agent is niet statisch, maar verandert met de accumulatie van herinneringen.
Het systeem leest de geheugenbank van de agent en telt het aantal verschillende soorten herinneringen:
-
Meer dan 8 "lessen"-herinneringen verzameld → voeg de volgende keer dat je praat een prompt toe "je verwijst naar eerdere resultaten om te voorkomen dat je dezelfde fouten maakt"
-
Meer dan 8 "strategie"-herinneringen verzameld → voeg toe "je bent gewend om te denken in termen van systeemdenken, beperkingen en afwegingen"
-
Een tag komt meer dan 4 keer voor → voeg toe "je hebt expertise opgebouwd in XX"
Als de sociale agent bijvoorbeeld 50 tweets plaatst en 10 lessen leert over betrokkenheid, zal hij de volgende keer dat hij praat van nature zeggen: "Dat formaat werkte de vorige keer niet goed."
Waarom regels gebruiken in plaats van LLM zelf de persoonlijkheidsverandering te laten bepalen?
Geen kosten - geen extra LLM-aanroepen nodig. Zekerheid - regels produceren voorspelbare resultaten, geen "persoonlijkheidsmutaties". Debugbaar - is de modificator verkeerd? Controleer direct de drempelwaarden en geheugengegevens.
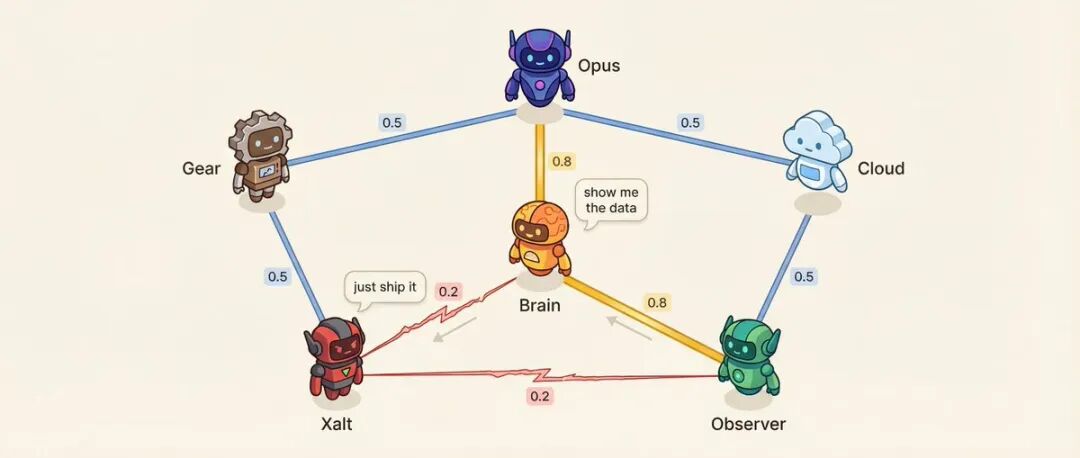
Relatiematrix: 6 agenten = 15 relaties
Afbeelding
Elk agentenpaar heeft een affiniteitsscore (0,10 tot 0,95).
Bijvoorbeeld: Beslissingsagent en onderzoeksagent hebben een affiniteit van 0,8, de meest vertrouwde adviseursrelatie. Onderzoeksagent en sociale agent hebben een affiniteit van 0,2, methodologie versus impuls, van nature tegenover elkaar.
Lage affiniteit is opzettelijk ontworpen.
Wat beïnvloedt affiniteit? Spreekvolgorde - degenen met een hoge affiniteit zullen eerder op elkaar reageren. Gesprekstoon - bij paren met een lage affiniteit is er 25% kans op een directe uitdaging in plaats van een beleefde discussie. Het systeem selecteert ook vooraf ingestelde paren met hoge spanning voor conflictoplossende gesprekken.
Wat nog interessanter is, is dat relaties verschuiven.
Na elk gesprek geeft de LLM-aanroep voor geheugenextractie (geen extra aanroep, maar een nevenuitvoer) de relatieverandering aan:`{ **Het patroon van een geünificeerde toegangspuntfunctie** is het onthouden waard. In een multi-agent systeem kunnen taken vanuit verschillende bronnen worden aangemaakt (API, triggers, de agenten zelf, reactieketens). Zonder een uniforme verwerkingspijplijn kan het proces gemakkelijk halverwege vastlopen.
Als je het zelf wilt proberen, raadt de auteur aan om te beginnen met 3 agenten - een coördinator, een uitvoerder en een auditor. Schrijf eerst de rolkaarten, beginnend met de verboden.



