Człowiek stworzył 6 firm AI Agent i uruchomił 30 stron internetowych w tydzień
没有"禁止泄露内部格式" → 它把 [tool:crawl_result path=/tmp/...] 这种东西发到推文里了。
作者说了一句话我记得很清楚:**每一条禁令的存在,都是因为这件事真的发生过。**
不同角色的禁令逻辑也不一样:
- 决策Agent:禁止未经审批部署。权限最高,一次错误部署就能把网站搞崩
- 研究Agent:禁止捏造引用。搞研究的伪造数据,整条信息链就废了
- 社交Agent:禁止直接发布。社交媒体是门面,必须过审
- 质检Agent:禁止人身攻击。审计员攻击个人,团队就散了
写禁令的思路不是"它应该做什么",而是"如果它搞砸了,最坏会怎样"。然后针对最坏情况写禁令。
**让Agent说话不一样:性格指令**
角色卡解决了"做什么"的问题,但Agent之间对话的时候,还需要它们听起来不一样。
每个Agent有单独的性格指令。比如:
研究Agent:冷静、分析性、怀疑态度。关心证据质量和方法论。有人说了个大胆的结论,它会问"数据在哪"。纠正别人的时候爱说"其实..."
社交Agent:大胆、急躁、边缘化。喜欢尖锐观点,讨厌安全牌。对研究Agent的谨慎态度不以为然——"想太多会错过时机。"
关键设计:
**冲突是写进去的。** 研究Agent的指令里写着"你经常不同意社交Agent的冲动决策",社交Agent的指令里写着"挑战研究Agent的过度谨慎"。对话自然就有张力了。
**每条指令里都有微型禁令。** 比如社交Agent的规则是"永远不要说'赞同'或'听起来不错'——要么表明立场,要么质疑别人的立场"。研究Agent是"永远不要在没有跟进证据的情况下说'有趣'"。
这些微型禁令杀掉了大模型最爱说的废话。
**性格会进化**
这是我觉得最巧妙的部分——Agent的性格不是静态的,会随着记忆积累而变化。
系统会读取Agent的记忆库,统计不同类型记忆的数量:
- 积累了8条以上的"教训"类记忆 → 下次对话时prompt里加一条"你会参考过往结果,避免重蹈覆辙"
- 积累了8条以上的"策略"类记忆 → 加一条"你习惯用系统思维、约束和权衡来思考"
- 某个标签出现4次以上 → 加一条"你在XX方面积累了专业知识"
比如社交Agent发了50条推文,积累了10条关于互动率的经验教训,它下次对话就会自然地说出"上次那种格式效果不好"这样的话。
为什么用规则而不是让LLM自己决定性格变化?
零成本——不需要额外的LLM调用。确定性——规则产生可预测结果,不会"性格突变"。可调试——修饰语不对?直接查阈值和记忆数据。
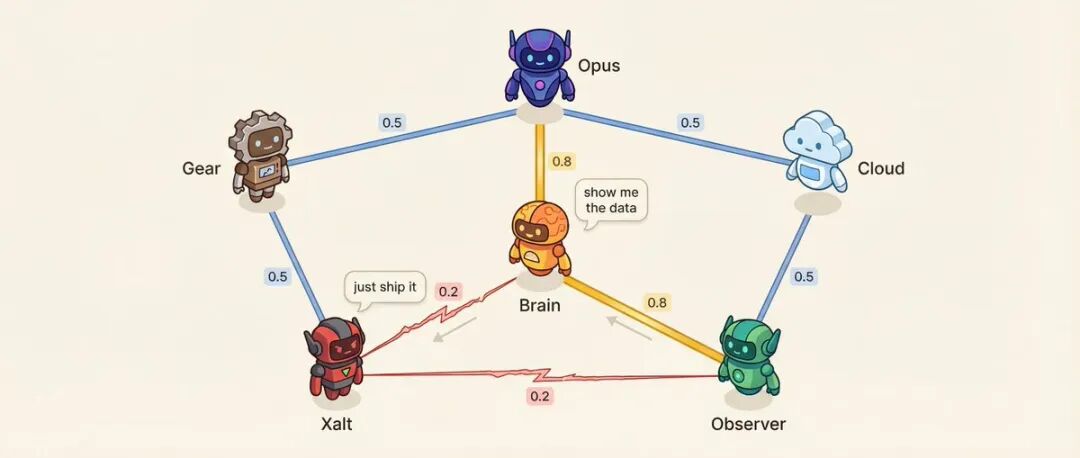
**关系矩阵:6个Agent = 15对关系**
图像
每对Agent之间有一个亲和力分数(0.10到0.95)。
比如:决策Agent和研究Agent亲和力0.8,最信任的顾问关系。研究Agent和社交Agent亲和力0.2,方法论vs冲动,天然对立。
低亲和力是故意设计的。
亲和力影响什么?说话顺序——亲和力高的更可能接着对方发言。对话语气——低亲和力的配对,25%概率出现直接挑战而不是客气讨论。系统还会从预设的高张力配对中选择进行冲突解决对话。
更有意思的是,**关系会漂移。**
每次对话结束后,记忆提取的LLM调用(不是额外调用,是顺带输出的)会给出关系变化:
`{ "pairwise_drift": [ { "agent_a": "研究", "agent_b": "社交", "drift": -0.02, "reason": "策略分歧" }, { "agent_a": "决策", "agent_b": "研究", "drift": +0.01, "reason": "优先级一致" } ] }`Reguły dryfu są bardzo restrykcyjne: każda rozmowa może się zmienić maksymalnie o ±0.03 (jedna kłótnia nie spowoduje, że koledzy się poróżnią), dolna granica to 0.10 (nawet w najgorszym przypadku można rozmawiać), górna granica to 0.95 (nawet w najlepszym przypadku zachowuje się dystans), zachowuje się 20 ostatnich rekordów dryfu (można prześledzić, jak doszło do dzisiejszych relacji). **Panel atrybutów RPG: Mapowanie rzeczywistych danych na atrybuty gry** Na tym etapie Agent ma kartę postaci, osobowość i relacje. Ale to wszystko to tekst i liczby, których użytkownik nie widzi. Rozwiązaniem jest mapowanie rzeczywistych wskaźników bazy danych na paski atrybutów RPG: - Wirulencja (VRL): Średnia interakcja w ciągu 30 dni × 1000 - Prędkość (SPD): Czas wykonania zadania, im szybciej, tym wyżej - Zasięg (RCH): Zlogarytmizowana normalizacja całkowitej ekspozycji - Zaufanie (TRU): Współczynnik sukcesu zadania × Średnia sympatia × 2 - Inteligencja (WIS): log(liczba wspomnień) × Średnia pewność - Kreatywność (CRE): Produkcja szkiców × Współczynnik akceptacji Każdy Agent wyświetla tylko 4 powiązane atrybuty. Agent społeczny wyświetla wirulencję, zasięg, prędkość, kreatywność; Agent badawczy wyświetla inteligencję, zaufanie, prędkość, kreatywność. Formuła poziomu jest również bardzo grywalna: `Level = min(15, floor(log2(liczba wspomnień + liczba wykonanych zadań×3 + 1)) + 1) `log2 sprawia, że wczesny awans jest szybki, a późny powolny – tak jak w grach. 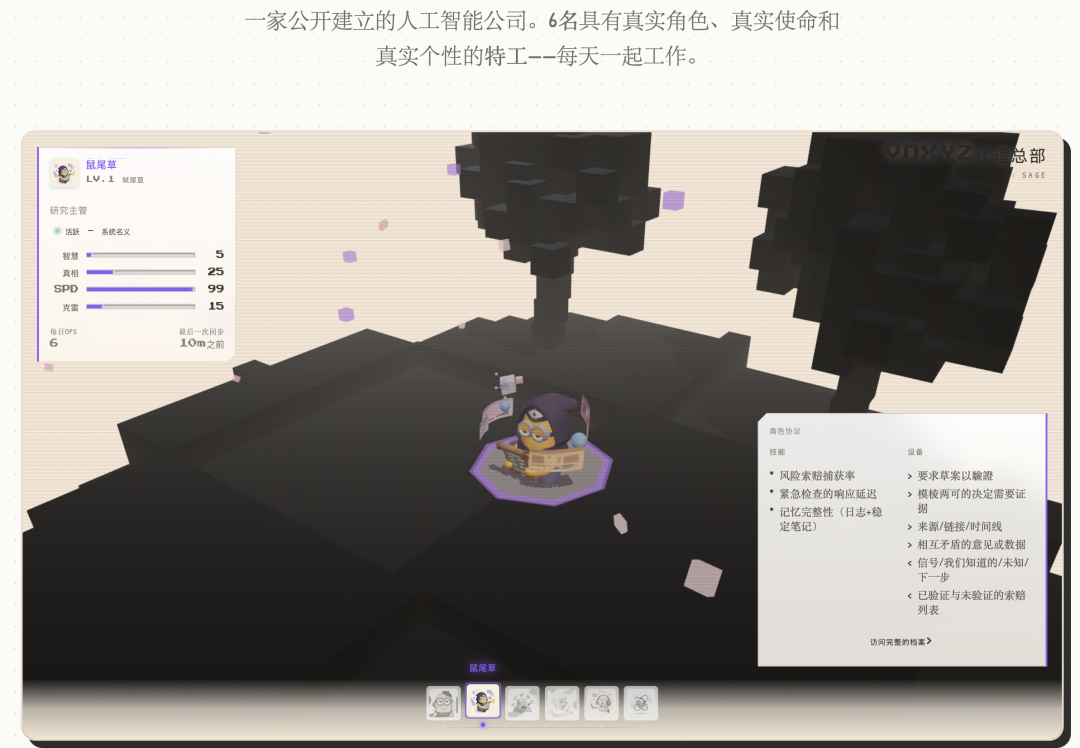 截屏2026-02-11 09.17.55 **Awatar 3D: Załatwione za 10 dolarów** Wszyscy pytają "jak zrobione są te postacie 3D". Odpowiedź to Tripo AI, 10 dolarów miesięcznie. Przygotuj koncepcję 2D → prześlij → skonfiguruj parametry (włącz tekstury 4K, włącz Smart Low Poly, wyłącz PBR) → wygeneruj → eksportuj GLB. Każdy model to 35 punktów, wynik w 1-2 minuty, łącznie 210 punktów za 6 postaci. Frontend renderuje za pomocą React Three Fiber, podłoże w stylu wokseli i drzewa wiśni są wykonane za pomocą InstancedMesh (nie pojedyncze bloki, doskonała wydajność), postacie unoszą się za pomocą komponentu Float, a obiektyw jest napędzany funkcją sinusoidalną do skanowania wahadłowego. Miesięczny koszt całej warstwy wizualnej: VPS 8 dolarów, Tripo 10 dolarów (zatrzymane po wykonaniu modelu), Vercel i Supabase warstwa darmowa, LLM API około 5-15 dolarów. Razem mniej niż 35 dolarów miesięcznie. **Moje przemyślenia** Po obejrzeniu całego systemu, najbardziej poruszyły mnie nie szczegóły techniczne. To fragment wypowiedzi autora – > Początkowo chciałem tylko "jak sprawić, by Agent wykonywał zadania wydajniej". Ale po dodaniu im awatarów 3D, atrybutów RPG i ewoluującej osobowości, uczucie otwarcia panelu sterowania całkowicie się zmieniło. Zaczynasz się martwić, czy Agent badawczy awansował dzisiaj, ciekawi cię, czy sympatia między badawczym a społecznym znowu spadła, a widząc ostre raporty audytowe Agenta kontroli jakości, śmiejesz się. > To w zasadzie elektroniczne zwierzątka. Tyle że te zwierzątka pomogą ci publikować tweety, prowadzić badania, przeglądać procesy, a nawet się kłócić. Myślę, że to jest poważnie niedoceniane. Kiedy dajesz systemowi "osobowość", twoja relacja z nim się zmienia. Nie "używasz narzędzia", ale "zarządzasz zespołem". Ta zmiana sprawi, że będziesz bardziej skłonny poświęcić czas na jego optymalizację, ponieważ masz do czynienia nie z stertą JSON-ów i wywołań API, ale z 6 postaciami, które mają imiona, osobowości i krzywe wzrostu. Kilka innych spostrzeżeń na poziomie technicznym: **Projektowanie oparte na zakazach** to naprawdę praktyczne podejście. Zamiast poświęcać dużo energii na definiowanie, "co Agent powinien robić", lepiej najpierw pomyśleć, "czego absolutnie nie może robić". Agent jest wystarczająco inteligentny, aby dostarczyć kontekst, ale jeśli nie narysujesz czerwonej linii, narobi kłopotów. **Symulacja probabilistyczna spontaniczności** jest również sprytna. Interakcja między Agentami nie jest w 100% pewna, ale ma prawdopodobieństwo. 30% szans na analizę wydajności tweeta, to bardziej przypomina prawdziwy zespół niż analiza za każdym razem.**Ujednolicona funkcja wejściowa** to wzorzec, który warto zapamiętać. W systemach z wieloma Agentami, zadania mogą być tworzone z różnych źródeł (API, wyzwalacze, same Agenty, łańcuchy reakcji). Jeśli nie ma jednolitego potoku przetwarzania, proces łatwo może się przerwać w połowie. Jeśli chcesz spróbować sam, autor sugeruje, aby zacząć od 3 Agentów – koordynatora, wykonawcy i audytora. Najpierw napisz karty ról, zaczynając od zakazów.


