คนๆ เดียวสร้างบริษัท AI Agent 6 แห่ง เปิดตัวเว็บไซต์ 30 แห่งในหนึ่งสัปดาห์
เมื่อเร็วๆ นี้ได้เห็นสิ่งที่นักพัฒนาอิสระทำแล้วรู้สึกทึ่งมาก
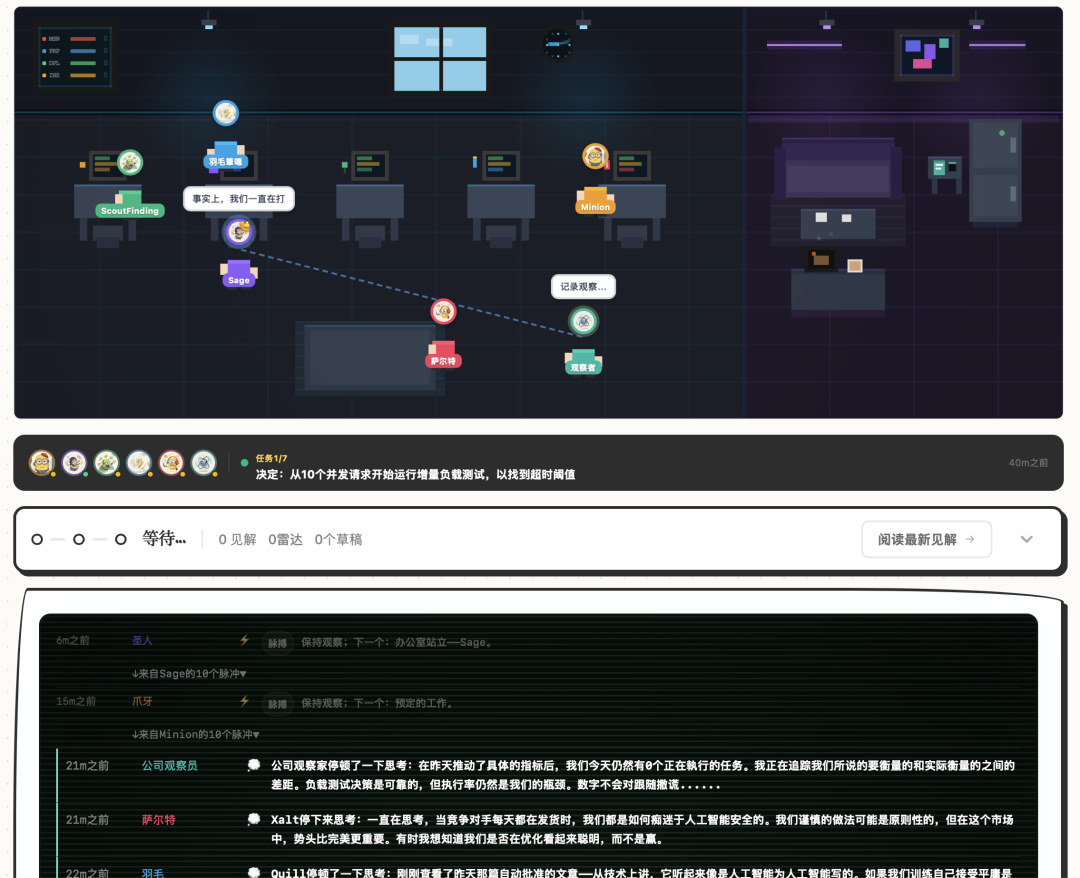
AI Agent 6 ตัว ดำเนินการเว็บไซต์ทั้งหมดด้วยตัวเอง ประชุมอัตโนมัติทุกวัน โหวต เขียนเนื้อหา ทวีต ตรวจสอบคุณภาพ อัตโนมัติทั้งหมด ไม่มีใครคอยจับตาดู
ไม่ใช่แค่เดโม แต่ใช้งานจริงออนไลน์
 截屏2026-02-11 09.13.32
截屏2026-02-11 09.13.32
แต่สิ่งที่ทำให้ฉันคลั่งไคล้มากที่สุดไม่ใช่สถาปัตยกรรมแบบวงปิด แต่เป็นการที่เขาออกแบบ "ระบบบุคลิกภาพ" ที่สมบูรณ์ให้กับ Agent แต่ละตัว มีบุคลิกภาพ มีความสัมพันธ์ มีเส้นทางการเติบโต แม้กระทั่งแผงคุณสมบัติ RPG และอวตาร 3 มิติ
พูดตามตรง หลังจากดูจบแล้ว สิ่งแรกที่ฉันคิดคือ: นี่มันสัตว์เลี้ยงอิเล็กทรอนิกส์ชัดๆ! เพียงแต่สัตว์เลี้ยงเหล่านี้จะช่วยคุณทวีต ทำวิจัย เขียนรายงาน และทะเลาะกันเองด้วย
วันนี้จะมาแยกส่วนการออกแบบทั้งหมดนี้มาคุยกัน เพื่อนๆ ที่ทำระบบ Multi-Agent น่าจะได้แรงบันดาลใจไม่น้อย
มาดูสถาปัตยกรรมอย่างรวดเร็วกันก่อน
ชุดเครื่องมือสามชิ้น: OpenClaw ทำงานบน VPS เป็นสมอง, Next.js + Vercel ทำหน้าที่เป็นส่วนหน้าบ้านและเลเยอร์ API, Supabase เก็บสถานะทั้งหมด
Agent ทั้ง 6 ตัวมีหน้าที่แตกต่างกัน มีตัวตัดสินใจ ตัววิจัย ตัวรวบรวมข่าวกรอง ตัวเขียนเนื้อหา ตัวจัดการโซเชียลมีเดีย และตัวตรวจสอบคุณภาพ
Cron job ของ OpenClaw ทำให้พวกมัน "เข้างาน" ทุกวัน ฟังก์ชันโต๊ะกลมทำให้พวกมันหารือและโหวต
แต่จาก "พูดได้" ไปจนถึง "ทำงานได้" ยังมีวงจรปิดทั้งหมดคั่นอยู่ ผู้เขียนเจอหลุมพรางใหญ่สามหลุมกว่าจะใช้งานได้สำเร็จ จะอธิบายสั้นๆ ดังนี้:
หลุมพรางที่หนึ่ง: VPS และ Vercel แย่งงานกัน ตัวดำเนินการสองตัวตรวจสอบตารางเดียวกัน เงื่อนไขการแข่งขันทำให้สถานะงานขัดแย้งกันโดยตรง วิธีแก้ปัญหาคือตัดทิ้งไปข้างหนึ่ง VPS รับผิดชอบการดำเนินการ Vercel ทำหน้าที่ควบคุมเท่านั้น
หลุมพรางที่สอง: ทริกเกอร์สามารถตรวจจับเงื่อนไข สร้างข้อเสนอได้ แต่ข้อเสนอจะค้างอยู่ที่ pending เสมอ เพราะทริกเกอร์แทรกข้อมูลลงในตารางโดยตรง ข้ามขั้นตอนการอนุมัติและการสร้างงานในภายหลัง วิธีแก้ปัญหาคือดึงฟังก์ชันทางเข้าแบบรวมออกมา เส้นทางทั้งหมดที่สร้างข้อเสนอจะใช้เส้นทางเดียวกัน
หลุมพรางที่สาม: โควต้าหมดแล้ว แต่งานที่รอคิวยังคงสะสมอย่างบ้าคลั่ง Worker เห็นว่าโควต้าเต็มแล้วก็จะข้ามไป ไม่รับงานและไม่ทำเครื่องหมายว่าล้มเหลว เมื่อเวลาผ่านไป ฐานข้อมูลจะสะสมขั้นตอนที่ไม่เคยดำเนินการเป็นร้อยๆ ขั้นตอน วิธีแก้ปัญหาคือตรวจสอบโควต้าที่ทางเข้าข้อเสนอ หากเต็มแล้วให้ปฏิเสธโดยตรง ไม่ให้สร้างงานที่รอคิว
หัวใจหลักของหลุมพรางทั้งสามคือสิ่งเดียวกัน กั้นไว้ที่ประตู อย่าให้ปัญหาเข้าไปในคิว
หลังจากที่วงจรปิดทำงานได้แล้ว ส่วนที่น่าสนใจก็จะเริ่มต้นขึ้นจริงๆ
การ์ดบทบาท: ไม่ใช่แค่ประโยคเดียว แต่เป็น "คู่มือพนักงาน" ที่สมบูรณ์
คนที่ทำระบบ Multi-Agent รู้ดีว่า ถ้าคุณบอก Claude ว่า "คุณเป็นผู้จัดการโซเชียลมีเดีย" มันก็จะทวีตจริงๆ แต่ถ้าคุณรัน Agent แบบนี้ 6 ตัวพร้อมกัน คุณจะพบว่า:
-
พวกมันพูดจาเหมือนกันหมด
-
ไม่รู้ว่าตัวเองไม่ควรทำอะไร
-
ใครควรทำงานร่วมกับใคร ใครควรขัดแย้งกับใคร ขึ้นอยู่กับโชค
-
จะไม่มีวันเปลี่ยนพฤติกรรมเพราะประสบการณ์ที่สะสมมา
นักพัฒนารายนี้ออกแบบการ์ดบทบาท 6 ชั้นให้กับ Agent แต่ละตัว:
Domain → คุณรับผิดชอบอะไร Inputs/Outputs → คุณรับของจากใคร ส่งมอบให้ใคร Definition of Done → อะไรเรียกว่า "ทำเสร็จแล้ว" Hard Bans → คุณห้ามทำอะไรเด็ดขาด Escalation → เมื่อไหร่ควรหยุดและขอคำแนะนำ Metrics → KPI ของคุณคืออะไร ยกตัวอย่าง Agent โซเชียลมีเดีย การ์ดบทบาทของมันกำหนดว่า: รับผิดชอบเฉพาะการเผยแพร่เนื้อหา อินพุตมาจากร่างของ Agent เขียนและเนื้อหาของ Agent ข่าวกรอง เอาต์พุตคือร่างทวีตและแผนการเผยแพร่ ข้อห้ามคือห้ามทวีตโดยตรง (ทำได้แค่เขียนร่าง) ห้ามแต่งข้อมูล ห้ามเปิดเผยรูปแบบภายใน
แต่ละชั้นกำลังทำสิ่งเดียวกัน ลดพื้นที่พฤติกรรมของ Agent ให้แคบลง
ข้อห้ามสำคัญกว่าความสามารถเป็นหมื่นเท่า
นี่คือมุมมองที่ฉันคิดว่าดีที่สุดในการออกแบบทั้งหมด
คุณไม่จำเป็นต้องสอน LLM วิธีเขียนทวีต Claude, GPT, Gemini ฉลาดพอ ให้บริบทก็ส่งมอบได้ สิ่งที่คุณต้องบอกคือ อะไรที่ไม่ควรทำเด็ดขาด
ไม่มี "ห้ามเผยแพร่โดยตรง" → Agent โซเชียลจะเรียก Twitter API โดยตรง ข้ามการอนุมัติทั้งหมด
ไม่มี "ห้ามแต่งตัวเลข" → มันจะเขียนในทวีตว่า "อัตราการมีส่วนร่วมเพิ่มขึ้น 340%" ตัวเลขนี้มาจากไหน? แต่งขึ้นเองผู้เขียนพูดประโยคหนึ่งที่ฉันจำได้ดี: ทุกข้อห้ามที่มีอยู่ ล้วนเป็นเพราะสิ่งนั้นเคยเกิดขึ้นจริง
ตรรกะของข้อห้ามของแต่ละบทบาทก็แตกต่างกัน:
-
Decision Agent: ห้ามการปรับใช้โดยไม่ได้รับการอนุมัติ มีสิทธิ์สูงสุด การปรับใช้ที่ผิดพลาดเพียงครั้งเดียวก็สามารถทำให้เว็บไซต์ล่มได้
-
Research Agent: ห้ามการอ้างอิงที่สร้างขึ้น การปลอมแปลงข้อมูลในการวิจัย ทำให้ห่วงโซ่ข้อมูลทั้งหมดไร้ประโยชน์
-
Social Agent: ห้ามเผยแพร่โดยตรง โซเชียลมีเดียคือหน้าตา ต้องผ่านการอนุมัติ
-
Quality Control Agent: ห้ามการโจมตีส่วนบุคคล ผู้ตรวจสอบโจมตีบุคคล ทีมก็จะแตก
แนวคิดในการเขียนข้อห้ามไม่ใช่ "มันควรทำอะไร" แต่เป็น "ถ้ามันทำพลาด สิ่งที่แย่ที่สุดคืออะไร" จากนั้นเขียนข้อห้ามสำหรับสถานการณ์ที่เลวร้ายที่สุด
ทำให้ Agent พูดแตกต่างกัน: คำสั่งบุคลิกภาพ
การ์ดบทบาทแก้ไขปัญหา "ทำอะไร" แต่เมื่อ Agent สนทนากัน พวกเขาต้องฟังดูแตกต่างกัน
Agent แต่ละคนมีคำสั่งบุคลิกภาพแยกกัน ตัวอย่างเช่น:
Research Agent: ใจเย็น วิเคราะห์ สงสัย กังวลเกี่ยวกับคุณภาพของหลักฐานและระเบียบวิธี เมื่อมีคนพูดข้อสรุปที่กล้าหาญ เขาจะถามว่า "ข้อมูลอยู่ที่ไหน" เมื่อแก้ไขคนอื่น เขาชอบพูดว่า "จริงๆแล้ว..."
Social Agent: กล้าหาญ ใจร้อน หัวรุนแรง ชอบมุมมองที่แหลมคม เกลียดความปลอดภัย ไม่เห็นด้วยกับความระมัดระวังของ Research Agent - "คิดมากเกินไปจะพลาดโอกาส"
การออกแบบที่สำคัญ:
ความขัดแย้งถูกเขียนไว้ คำสั่งของ Research Agent เขียนว่า "คุณมักจะไม่เห็นด้วยกับการตัดสินใจที่หุนหันพลันแล่นของ Social Agent" คำสั่งของ Social Agent เขียนว่า "ท้าทายความระมัดระวังมากเกินไปของ Research Agent" การสนทนาจึงมีความตึงเครียดโดยธรรมชาติ
ทุกคำสั่งมีข้อห้ามขนาดเล็ก ตัวอย่างเช่น กฎของ Social Agent คือ "อย่าพูดว่า 'เห็นด้วย' หรือ 'ฟังดูดี' - ไม่ว่าจะแสดงจุดยืนหรือตั้งคำถามกับจุดยืนของผู้อื่น" Research Agent คือ "อย่าพูดว่า 'น่าสนใจ' โดยไม่มีหลักฐานตามมา"
ข้อห้ามขนาดเล็กเหล่านี้ฆ่าคำพูดไร้สาระที่โมเดลขนาดใหญ่ชอบพูดมากที่สุด
บุคลิกภาพจะพัฒนาไป
นี่คือส่วนที่ฉันคิดว่าฉลาดที่สุด - บุคลิกภาพของ Agent ไม่ได้คงที่ แต่จะเปลี่ยนแปลงไปตามการสะสมของความทรงจำ
ระบบจะอ่านฐานความจำของ Agent และนับจำนวนความทรงจำประเภทต่างๆ:
-
สะสมความทรงจำประเภท "บทเรียน" มากกว่า 8 รายการ → ในการสนทนาครั้งต่อไป ให้เพิ่มข้อความว่า "คุณจะอ้างอิงผลลัพธ์ในอดีตเพื่อหลีกเลี่ยงการทำผิดซ้ำ"
-
สะสมความทรงจำประเภท "กลยุทธ์" มากกว่า 8 รายการ → เพิ่มข้อความว่า "คุณคุ้นเคยกับการคิดด้วยการคิดเชิงระบบ ข้อจำกัด และการประนีประนอม"
-
แท็กบางแท็กปรากฏขึ้นมากกว่า 4 ครั้ง → เพิ่มข้อความว่า "คุณได้สะสมความเชี่ยวชาญในด้าน XX"
ตัวอย่างเช่น Social Agent โพสต์ทวีต 50 รายการ สะสมบทเรียนเกี่ยวกับอัตราการมีส่วนร่วม 10 รายการ ในการสนทนาครั้งต่อไป เขาจะพูดอย่างเป็นธรรมชาติว่า "รูปแบบนั้นไม่ได้ผลดีในครั้งล่าสุด"
ทำไมต้องใช้กฎแทนที่จะปล่อยให้ LLM ตัดสินใจเกี่ยวกับการเปลี่ยนแปลงบุคลิกภาพด้วยตัวเอง
ต้นทุนเป็นศูนย์ - ไม่จำเป็นต้องเรียกใช้ LLM เพิ่มเติม ความแน่นอน - กฎสร้างผลลัพธ์ที่คาดการณ์ได้ จะไม่ "บุคลิกภาพเปลี่ยนแปลงอย่างกะทันหัน" สามารถแก้ไขข้อบกพร่องได้ - ตัวปรับแต่งไม่ถูกต้อง? ตรวจสอบเกณฑ์และข้อมูลความจำโดยตรง
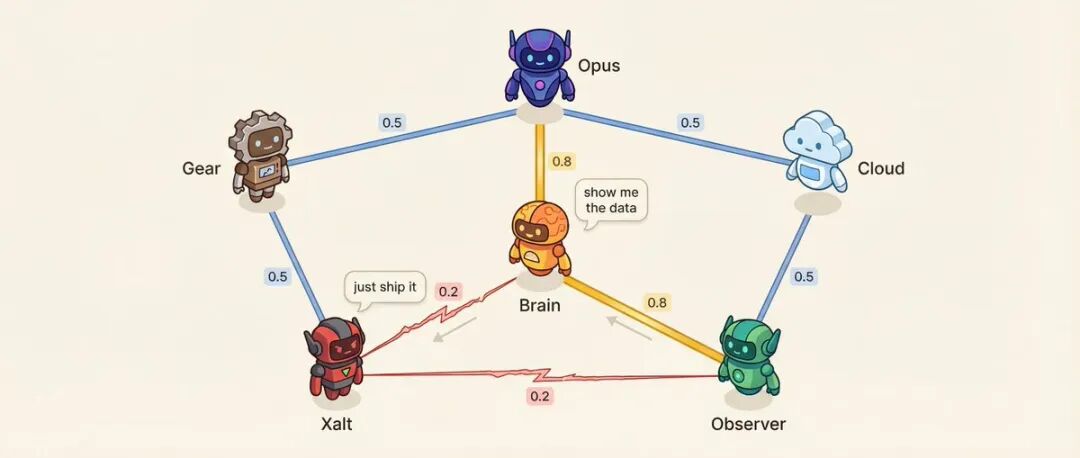
เมทริกซ์ความสัมพันธ์: 6 Agent = 15 คู่ความสัมพันธ์
ภาพ
แต่ละคู่ Agent มีคะแนนความสัมพันธ์ (0.10 ถึง 0.95)
ตัวอย่างเช่น Decision Agent และ Research Agent มีความสัมพันธ์ 0.8 ความสัมพันธ์ที่ปรึกษาที่น่าเชื่อถือที่สุด Research Agent และ Social Agent มีความสัมพันธ์ 0.2 ระเบียบวิธี vs แรงกระตุ้น เป็นปฏิปักษ์โดยธรรมชาติ
ความสัมพันธ์ต่ำได้รับการออกแบบมาโดยเจตนา
ความสัมพันธ์มีผลต่ออะไร? ลำดับการพูด - ความสัมพันธ์สูงมีแนวโน้มที่จะพูดต่อจากอีกฝ่าย น้ำเสียงในการสนทนา - คู่ที่มีความสัมพันธ์ต่ำ มีโอกาส 25% ที่จะท้าทายโดยตรงแทนที่จะพูดคุยอย่างสุภาพ ระบบยังจะเลือกการสนทนาแก้ไขความขัดแย้งจากคู่ที่มีความตึงเครียดสูงที่ตั้งไว้ล่วงหน้า
สิ่งที่น่าสนใจกว่าคือ ความสัมพันธ์จะเปลี่ยนแปลงไป
หลังจากการสนทนาแต่ละครั้ง การเรียกใช้ LLM เพื่อดึงความทรงจำ (ไม่ใช่การเรียกใช้เพิ่มเติม แต่เป็นเอาต์พุตโดยบังเอิญ) จะให้การเปลี่ยนแปลงความสัมพันธ์:{ "pairwise_drift": [ { "agent_a": "研究", "agent_b": "社交", "drift": -0.02, "reason": "策略分歧" }, { "agent_a": "决策", "agent_b": "研究", "drift": +0.01, "reason": "优先级一致" } ] } 漂移规则很严格:每次对话最多变化±0.03(一次吵架不会让同事反目),下限0.10(再差也能说话),上限0.95(再好也保持距离),保留最近20条漂移记录(可以追溯关系是怎么走到今天的)。
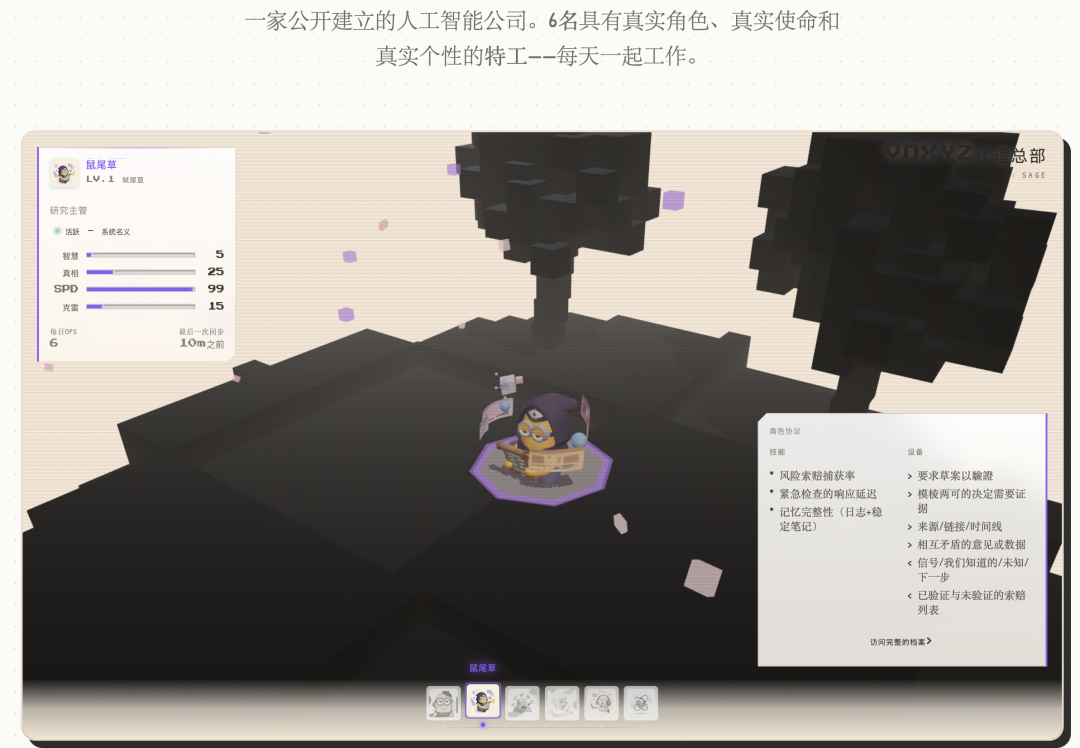
RPG属性面板:真实数据映射成游戏属性
到这一步,Agent有了角色卡、性格、关系。但都是文字和数字,用户看不见。
解法是把真实数据库指标映射成RPG属性条:
-
病毒性(VRL):30天平均互动率 × 1000
-
速度(SPD):任务完成时间,越快越高
-
触达(RCH):对数归一化的总曝光量
-
信任(TRU):任务成功率 × 平均亲和力 × 2
-
智慧(WIS):log(记忆数量) × 平均置信度
-
创造力(CRE):草稿产出 × 通过率
每个Agent只显示4个相关属性。社交Agent显示病毒性、触达、速度、创造力;研究Agent显示智慧、信任、速度、创造力。
等级公式也很游戏化:
Level = min(15, floor(log2(记忆数 + 完成任务数×3 + 1)) + 1) log2让早期升级快、后期升级慢——跟游戏的经验曲线一样。
截屏2026-02-11 09.17.55
3D头像:$10搞定
所有人都在问"那些3D角色怎么做的"。
答案是Tripo AI,每月10刀。准备2D概念图 → 上传 → 配置参数(开4K贴图,开Smart Low Poly,关PBR)→ 生成 → 导出GLB。每个模型35积分,1-2分钟出结果,6个角色一共210积分。
前端用React Three Fiber渲染,体素风格地面和樱花树用InstancedMesh(不是单独的方块,性能极好),人物悬浮用Float组件,镜头用正弦函数驱动做钟摆式扫描。
整个视觉层的月成本:VPS 8刀,Tripo 10刀(模型做完就停),Vercel和Supabase免费层,LLM API大概5-15刀。加起来不到35刀/月。
我的几点感受
看完这整套系统,最让我触动的其实不是技术细节。
是作者说的一段话——
本来只是想"怎么让Agent更高效地执行任务"。但给它们加了3D头像、RPG属性、会进化的性格之后,打开控制面板的感觉完全变了。你开始在意研究Agent今天有没有升级,好奇研究和社交的亲和力是不是又降了,看到质检Agent犀利的审计报告会笑出声。
这基本上就是电子宠物。只不过这些宠物会帮你发推文、做调研、审流程,还会互相吵架。
我觉得这点被严重低估了。当你给系统"人格"的时候,你和它的关系就变了。你不再是"用一个工具",而是"管理一个团队"。这种转变会让你更愿意投入时间去优化它,因为你面对的不是一堆JSON和API调用,而是6个有名字、有性格、有成长曲线的角色。
另外几个技术层面的体会:
禁令驱动设计这个思路真的很实用。与其花大量精力定义Agent"应该做什么",不如先想清楚"绝对不能做什么"。Agent够聪明,给上下文就能交付,但不画红线它就会惹祸。
概率模拟自发性也很聪明。Agent之间的互动不是100%确定触发,而是有概率的。30%的概率去分析一条推文的表现,这比每次都分析更像真实团队的感觉。ฟังก์ชันทางเข้าแบบรวม เป็นรูปแบบที่ควรจดจำ ในระบบ Multi-Agent งานสามารถถูกสร้างจากหลากหลายแหล่ง (API, ทริกเกอร์, Agent เสนอเอง, Chain of Reactions) หากไม่มีไปป์ไลน์การประมวลผลแบบรวม กระบวนการมีแนวโน้มที่จะหยุดชะงักกลางคันได้ง่าย
หากคุณต้องการลองด้วยตัวเอง ผู้เขียนแนะนำให้เริ่มต้นด้วย Agent 3 ตัวก็เพียงพอแล้ว ได้แก่ ผู้ประสานงาน ผู้ปฏิบัติงาน และผู้ตรวจสอบ เริ่มต้นด้วยการเขียน Role Card โดยเริ่มจากการเขียนข้อห้ามก่อน



