Github أفضل ما في اليوم: تطوير وكيل ذكاء اصطناعي صوتي في الوقت الفعلي، صندوق أدوات شامل
Github أفضل ما في اليوم: تطوير وكيل ذكاء اصطناعي صوتي في الوقت الفعلي، صندوق أدوات شامل
هل شعرت يومًا بهذا الشعور، أنك تريد إنشاء وكيل ذكاء اصطناعي صوتي بسيط، ولكنك عالق في مشاكل مختلفة، على سبيل المثال، بعض الأشخاص في الفريق بارعون في Python، والبعض الآخر يتقنون C++. الأجزاء التي تم تطويرها بشكل منفصل تسبب مشاكل عند تجميعها معًا، ويمكن أن يستغرق تكوين البيئة نصف يوم، وتصبح وظائف التوسيع أكثر فوضوية كلما تم تعديلها، وفي النهاية يتم استهلاك الحماس.
اليوم، سأقدم لكم صندوق أدوات تطوير شامل وسهل الاستخدام للغاية TEN-Framework.

عنوان المصدر المفتوح: https://github.com/TEN-framework/ten-framework
TEN Framework يشبه تجميع كل هذه الأشياء المعقدة لك. إنه في الواقع إطار عمل مصمم خصيصًا لبناء الذكاء الاصطناعي الحواري متعدد الوسائط في الوقت الفعلي. يمكنك اعتباره خط إنتاج مساعد صوتي للذكاء الاصطناعي جاهزًا. وحدة التعرف على الصوت، ووحدة النموذج الكبيرة، ووحدة توليف الكلام، كلها جاهزة لك. ما عليك فعله هو تجميعها وفقًا لاحتياجاتك الخاصة. هذا يوفر لك الكثير من المتاعب مقارنة ببدء كل شيء من الصفر.
بالحديث عن ما يمكن أن يفعله على وجه التحديد، سأختار أولاً بعض الأشياء التي أجدها عملية نسبيًا. الأول هو مساعد صوتي متعدد الأغراض، يدعم طريقتي اتصال RTC و WebSocket، مع زمن انتقال منخفض وجودة صوت جيدة. سواء كنت ترغب في إنشاء خدمة عملاء ذكية أو مساعد صوتي شخصي، يمكن لهذه الوظيفة تلبية الاحتياجات الأساسية. الشيء المثير للاهتمام هو أنه يحتوي أيضًا على مولد رسومات الشعار المبتكرة، فإنه يرسم ما تقوله، وينتج رسومات الشعار المبتكرة بأسلوب مرسومة باليد. يجب أن تكون هذه الوظيفة شائعة جدًا في العروض التوضيحية أو السيناريوهات الترفيهية.

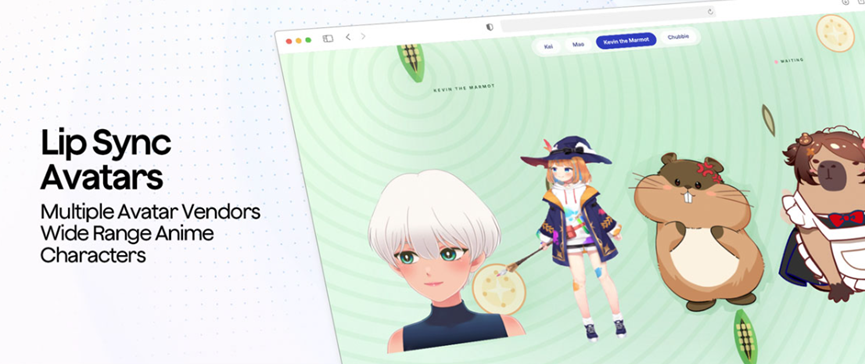
هناك أيضًا حلول مقابلة لسيناريوهات المحادثة متعددة الأطراف. لديها وظيفة التعرف على المتحدث في الوقت الفعلي، والتي يمكنها التمييز تلقائيًا بين من يتحدث، بحيث لا داعي للقلق بشأن الارتباك عند تسجيل محاضر الاجتماعات أو نسخ المقابلات. في قسم الشخصية الافتراضية، عندما يتحدث مساعد الذكاء الاصطناعي، يمكن أن تتزامن حركة فم الشخصية تمامًا مع الصوت. سواء كانت شخصية أنيمي ثنائية الأبعاد أو شخص افتراضي ثلاثي الأبعاد واقعي، يمكن أن تتطابق حركة الفم. هذا مناسب جدًا للمطورين الذين يصنعون مذيعين افتراضيين أو مساعدين شخصيين.
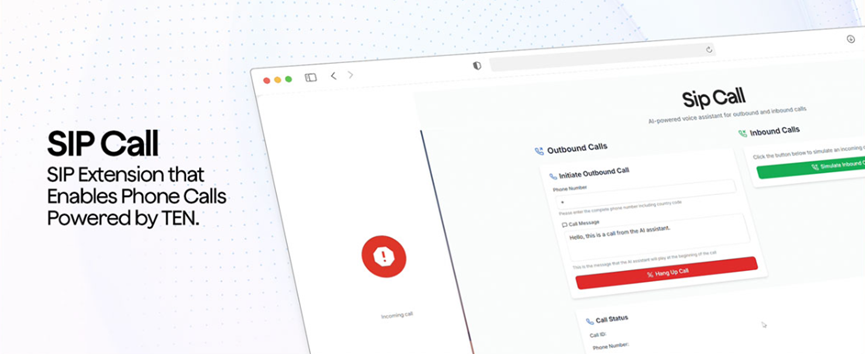
إذا كنت تريد أن يجيب على الهاتف، فإنه يدعم أيضًا بروتوكول SIP، ويمكن لمساعد الذكاء الاصطناعي الرد على المكالمات مباشرة. هذه الوظيفة عملية جدًا لمستخدمي المؤسسات، حيث يمكنها توصيل خدمة العملاء الذكية بنظام الهاتف، مما يوفر الكثير من تكاليف العمالة. بالطبع، لديه أيضًا وظيفة تحويل الصوت إلى نص الأساسية، وتحويل الصوت إلى نص في الوقت الفعلي، ويمكن استخدامها في سيناريوهات مثل محاضر الاجتماعات وإنشاء الترجمة.
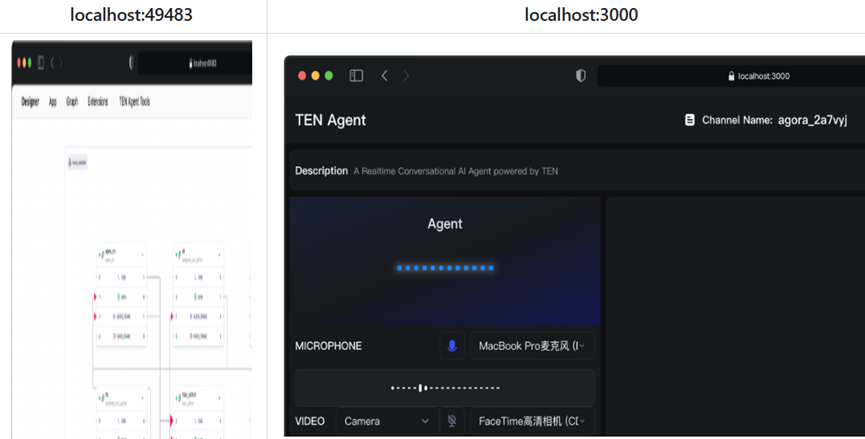
بالإضافة إلى العمليات الموحدة، فإنه يحتوي أيضًا على العديد من قوالب المشاريع الجاهزة، سواء كانت قوالب AI Agent أو قوالب مختلفة للتوسعات والتطبيقات. على سبيل المثال، قوالب توسعة LLM و TTS، بالإضافة إلى العديد من قوالب التطبيقات الافتراضية للغات السائدة، يمكن استخدامها مباشرة. من إنشاء مشروع جديد إلى تشغيل أول عرض توضيحي، يستغرق الأمر بضع دقائق فقط، مما يوفر الكثير من الوقت.
إذا كنت مطورًا متمرسًا، فهناك أيضًا طرق لعب متقدمة، على سبيل المثال، يمكنك إنشاء مساعد صوتي عالي الأداء في الوقت الفعلي، واستخدام C++ لمعالجة الصوت والفيديو في الوقت الفعلي لضمان زمن انتقال منخفض، واستخدام Python لاستنتاج LLM، بحيث يمكن للمساعد فهم والتفكير. ثم استخدم Node.js للتفاعل الأمامي، بحيث يمكن للمستخدمين التشغيل بسهولة، وسرعة التطوير بأكملها أسرع بثلاث مرات من التطوير التقليدي بلغة واحدة.
أو قم بدمج توسعة TEN للكشف عن نشاط الصوت VAD وتوسعة تحويل النص إلى كلام TTS وتوسعة LLM، ويمكنك إعداد روبوت محادثة ذكي تلقائي بالكامل، ويمكن أن تتصل التوسعات ببعضها البعض بسلاسة، دون الحاجة إلى كتابة تعليمات برمجية تكامل معقدة بنفسك.
حاليًا، هذا الإطار على وشك تجاوز 10000 نجمة، إذا كنت مهتمًا، يمكنك تجربته.



