MiniMax M2.5 Review
MiniMax M2.5 Review
Short Conclusion: Rooted Down, Growing Upward
Basic Information
Due to technical issues, the previous generation of MiniMax, M2.1, made significant progress in programming but lagged behind M2 in logical reasoning. Fortunately, M2.5 has largely resolved the technical problems, and its capabilities are back on track. Compared to M2, M2.5 has improved by approximately 17%.
However, some of the improvement comes from longer reasoning chains and deeper exploration of the solution space. The average token consumption of M2.5 ranks 6th highest among all models tested, almost twice that of its competitor, Sonnet. Fortunately, MiniMax's computing power is guaranteed, and the cost is not high. Although it cannot completely replace Sonnet in programming without any blind spots, it is fully usable for daily use. M2.5 finally achieved the goals that M2.1 aimed for.
Logic Performance
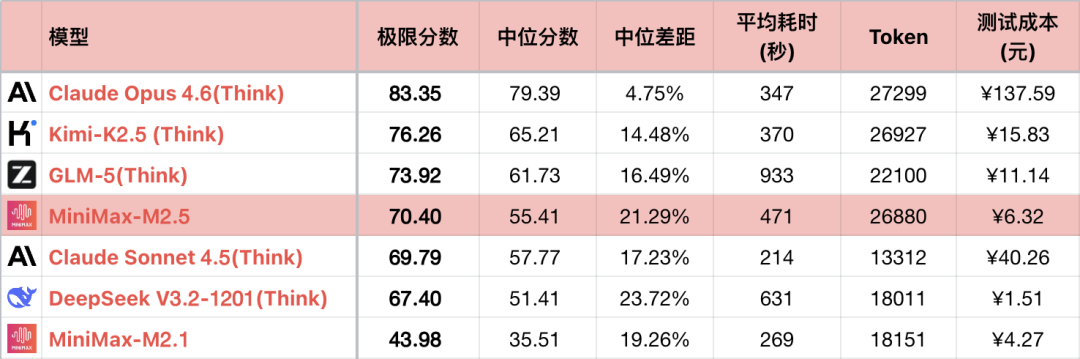
*1 The table only shows some comparable models to highlight the comparison, not a complete ranking.
*2 For questions and testing methods, see: Large Language Model - Logic Ability Horizontal Evaluation, January 2026 Ranking. Added #56 question.
*3 The complete list is updated at https://llm2014.github.io/llm_benchmark/
*4 Red is limited to the Spring Festival period, indicating festivity and has no other meaning.
Since M2.1 is a buggy version with abnormally low logical reasoning ability, the following only compares M2 and M2.5 across generations.
Improvements
- Stable Reasoning: M2.5 can maintain initial constraints and contextual details during longer reasoning processes. Therefore, M2.5 scores significantly higher on some problems that are not very difficult but require "focus." For example, on #4 Rubik's Cube rotation, M2.5 is the 8th model in the world to achieve a perfect score. However, the top three North American models can consistently achieve perfect scores on this type of problem, while M2.5 can only get it right with a small probability, showing a significant gap.
- Programming: As mentioned earlier, M2.5 cannot completely replace Sonnet in all aspects, mainly due to the limited amount of programming knowledge. In situations that require experience, skills, and API version differences, M2.5 has difficulty identifying problems on its own without prompts and usually needs to spend multiple rounds gradually narrowing down the problem. However, this is a huge improvement compared to M2. In C project testing, most domestic models get stuck in the first two rounds, while M2.5 became the first domestic model to break through to the 8th round. Although M2.5 has obvious shortcomings in OpenGL usage and spatial imagination, it can continuously try and converge to the correct solution with optimized Agent capabilities. It is also worth noting that M2.5 "talks" less when working on programming tasks, outputting only a brief summary after the work is finally completed, without outputting its thinking process in the middle. Other projects are still being tested and will be updated later.
- Calculation Ability: M2's calculation ability was not excellent, and M2.1 was even worse. M2.5 has made effective improvements from a low starting point. On most simple calculations, M2.5 has a small probability of high precision, but in most cases, it still makes mistakes, has large errors, and does not understand the formulas. Training in this area is still insufficient. As an Agent-driven model, calculation ability is not a rigid requirement; Claude series' calculation has also lagged behind for a long time.
Shortcomings
- Instruction Following: Compared to M2, the improvement in instruction following is not significant. It has a higher probability of getting perfect scores on some simple problems, but it is still not stable. There are cases of randomly discarding or tampering with instructions, but observing the chain of thought content, the model has noticed all the instructions, and the final output has problems. The overall performance lags behind other models in the first tier. It also ignores coding requirements and project specifications in programming, such as in the C project, where the Z-axis is specified to be upward, but M2.5 changed it to the Y-axis without authorization in order to fix another bug. Extra attention needs to be paid to control in daily use.
- Hallucinations: The level of hallucinations in M2.5 has not changed significantly compared to M2. For most context-related problems, the extreme scores of the two are the same. Even on #43 target number calculation problems, M2.5 still makes some low-level mistakes that only second-tier models would make, such as repeatedly using numbers or missing numbers.
Cyber Historian Says
Domestic manufacturers have spent more than half a year exploring how to make programming models. The earliest models, claiming to be replacements for Sonnet, mostly only looked close in terms of "one-sentence" generation effect. Their internal code organization, engineering, and, more importantly, multi-round iteration capabilities are far inferior. This has made domestic programmers generally distrust domestic models, preferring to use Claude even at the risk of having their accounts banned.
With MiniMax M2 and M2.1 initially reversing the reputation, the M2.5 generation has taken a big step forward in the usability of domestic model programming. Indeed, M2.5 still has comprehensive gaps compared to the officially claimed Opus level, but as long as someone is willing to trust and use it, things will develop in a positive direction. From this perspective, M2.5 is indeed a solid step taken by MiniMax towards the goal of victory.



