稀宇 MiniMax M2.5 レビュー
稀宇 MiniMax M2.5 レビュー
短い結論:下へ根を張り、上へ成長する
基本状況
稀宇の前世代M2.1は、技術的な問題により、プログラミング面では著しい進歩があったものの、論理能力はM2に劣っていました。幸いなことに、M2.5は基本的に技術的な問題を解決し、能力は正常な軌道に戻りました。M2と比較して、M2.5の進歩は約17%です。
ただし、一部の進歩は、より長い思考連鎖、より深い解空間探索によって得られたものであり、M2.5の平均Token消費量は、テスト中のすべてのモデルの中で6番目に高く、競合のSonnetのほぼ2倍です。幸いなことに、稀宇の計算能力は保証されており、コストも高くありません。プログラミングはSonnetを完全に代替することはできませんが、日常的な使用には完全に利用可能です。M2.5は最終的にM2.1が達成したかった目標を実現しました。
論理成績
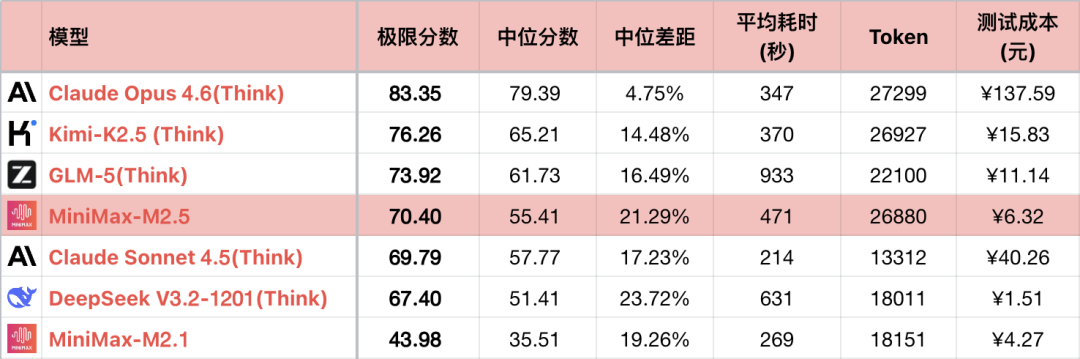
*1 表は対比関係を強調するため、一部の比較可能なモデルのみを表示しており、完全な順位ではありません。
*2 問題とテスト方法については、以下を参照してください:大言語モデル-論理能力横評価 26-01 月ランキング。#56問を追加。
*3 完全なランキングは https://llm2014.github.io/llm_benchmark/ で更新されます。
*4 赤色は春節期間限定であり、お祝いの意味を表し、他の意味はありません。
M2.1はバグがあり、論理能力が異常に低いバージョンであるため、以下ではM2とM2.5の世代間比較のみを行います。
改善点
- 安定した推論:M2.5は、より長い推論プロセスで初期制約とコンテキストの詳細を維持できるため、難易度は高くないものの、「集中」が必要な問題で、M2.5のスコアが大幅に向上しました。たとえば、#4のルービックキューブ回転では、M2.5は世界で8番目に満点を獲得したモデルです。ただし、この種の問題では、北米の御三家はすべて安定して満点を獲得できますが、M2.5はわずかな確率で1回成功するだけであり、差は明らかです。
- プログラミング:前述したように、M2.5はSonnetを全方位的に置き換えることはできません。主な理由は、プログラミングの知識量に制限があり、経験、スキル、バージョンAPIの差異などが必要な場合、M2.5はヒントなしに問題を自分で発見することが難しく、通常は複数回繰り返して徐々に問題を絞り込む必要があります。しかし、これはM2よりも大幅な進歩です。Cプロジェクトのテストでは、ほとんどの国内モデルが最初の2ラウンドで止まりますが、M2.5は最初に8ラウンドに到達した国内モデルになりました。M2.5はOpenGLの使用と空間的想像力に明らかな弱点がありますが、最適化されたAgent能力と組み合わせることで、試行錯誤を繰り返し、正しい解に収束できます。また、M2.5はプログラミング作業時に「話」が少なく、ほとんどの場合、最終的に作業を完了した後に簡単なまとめを出力するだけで、途中でアイデアを出力しないことに注意してください。他のプロジェクトはまだテスト中であり、後で更新されます。
- 計算能力:M2の計算能力は優れているとは言えず、M2.1はさらに後退しましたが、M2.5は低い起点から効果的な改善を加えました。ほとんどの簡単な計算では、M2.5は低い確率で高精度ですが、多くの場合、計算ミス、大きな誤差、および公式を理解できないという問題が依然として存在し、この分野のトレーニングはまだ不十分です。Agent駆動モデルとして、計算能力は必須ではなく、Claudeシリーズの計算も長期間遅れています。
不足点
- 指示遵守:M2と比較して、指示遵守の改善幅は大きくなく、いくつかの簡単な問題で満点を獲得する確率が高くなりましたが、安定させることはできません。ランダムに指示を破棄したり、指示を改ざんしたりする場合がありますが、思考連鎖の内容を観察すると、モデルはすべての指示に気付いていますが、最終的な出力に問題が発生しています。全体的なパフォーマンスは、第一線グループの他のモデルに劣ります。プログラミングでも、コーディング要件やプロジェクト仕様を無視する場合があります。たとえば、Cプロジェクトでは、座標Z軸が上向きに規定されていますが、M2.5は別のバグを修正するために、勝手にY軸を上向きに変更しました。日常的な使用では、追加の注意が必要です。
- 幻覚:M2.5の幻覚レベルは、M2と比べて大きな変化はありません。ほとんどのコンテキスト関連の問題では、両者の限界スコアは一致します。#43の目標数計算問題では、M2.5は第二線グループのモデルで発生するような、数字の繰り返し使用や数字の抜けなどの初歩的なミスを犯すことさえあります。
サイバース史官曰く
国内メーカーは半年以上の時間をかけて、プログラミングモデルをどのように作成すべきかを模索してきました。最初にSonnetの代替品と称されたモデルのほとんどは、「一言」生成の効果だけで、見た目は近いものでした。その内部のコード編成、エンジニアリング、そしてより重要な複数回の反復能力は、はるかに劣っています。そのため、国内のプログラマーは一般的に国内モデルを信用せず、アカウントが停止されるリスクを冒してでもClaudeを使用することを好みます。
しかし、MiniMax M2、M2.1が世評を覆し始めたことで、M2.5の世代は国内モデルのプログラミングの可用性を大きく前進させました。確かにM2.5は、公式に発表されているOpusのレベルとはあらゆる面で差がありますが、誰かが信頼し、使用する意思がある限り、事態は良い方向に進むでしょう。このことから、M2.5は確かに稀宇が勝利目標に向けて踏み出した確かな一歩であると言えます。





