稀宇 MiniMax M2.5 İncelemesi
稀宇 MiniMax M2.5 İncelemesi
Kısa Sonuç: Aşağıya Kök Sal, Yukarıya Büyü
Temel Durum
稀宇'nun önceki nesli M2.1, teknik sorunlar nedeniyle programlama konusunda önemli ölçüde ilerleme kaydetmesine rağmen, mantık yeteneği M2'nin gerisinde kaldı. Neyse ki M2.5, teknik sorunları temel olarak çözdü ve yetenekleri normal seyrine döndü. M2 ile karşılaştırıldığında, M2.5'in gelişimi yaklaşık %17.
Ancak bu gelişimin bir kısmı, daha uzun düşünce zincirleri ve daha derin çözüm uzayı keşfi ile elde edildi. M2.5'in ortalama Token tüketimi, test edilen tüm modeller arasında 6. sırada yer alıyor ve rakibi Sonnet'in neredeyse 2 katı. Neyse ki 稀宇'nun işlem gücü garanti altında ve maliyeti de yüksek değil. Programlama konusunda Sonnet'in yerini tamamen tutamasa da, günlük kullanım için tamamen uygun. M2.5 sonunda M2.1'in ulaşmak istediği hedefe ulaştı.
Mantık Sonuçları
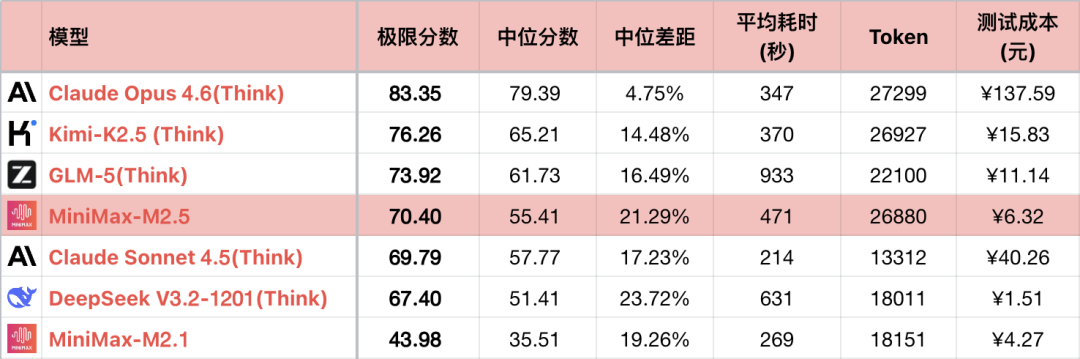
*1 Tablo, karşılaştırma ilişkisini vurgulamak için yalnızca bazı karşılaştırılabilir modelleri göstermektedir, tam sıralama değildir.
*2 Sorular ve test yöntemi için bkz.: Büyük Dil Modeli - Mantık Yeteneği Karşılaştırması 26-01 Aylık Sıralaması. #56 soru eklendi.
*3 Tam sıralama https://llm2014.github.io/llm_benchmark/ adresinde güncellenmektedir.
*4 Kırmızı, Çin Yeni Yılı dönemiyle sınırlıdır, şenliği ifade eder, başka bir anlamı yoktur.
M2.1, hatalı ve mantık yeteneği olağan dışı derecede düşük bir sürüm olduğundan, aşağıda yalnızca M2 ve M2.5'in nesiller arası karşılaştırması yapılacaktır.
İyileştirmeler
- Kararlı Çıkarım: M2.5, daha uzun çıkarım süreçlerinde ilk kısıtlamaları ve bağlam ayrıntılarını koruyabilir, bu nedenle zorluğu yüksek olmayan ancak "odaklanma" gerektiren bazı sorularda M2.5'in puanı önemli ölçüde arttı. Örneğin, #4 Küp Döndürme'de M2.5, dünya çapında tam puan alan 8. model oldu. Ancak bu tür sorunlarda, Kuzey Amerika'nın önde gelen üç modeli genellikle istikrarlı bir şekilde tam puan alabilirken, M2.5 yalnızca küçük bir olasılıkla bir kez doğru cevap verebiliyor, aradaki fark açık.
- Programlama: Daha önce belirtildiği gibi, M2.5, Sonnet'in yerini her açıdan tutamaz, bunun temel nedeni programlama bilgi birikimiyle sınırlı olmasıdır. Deneyim, beceri, sürüm API farklılıkları vb. gerektiren durumlarda, M2.5, ipucu olmadan sorunu kendi başına bulmakta zorlanır ve genellikle sorunu kademeli olarak daraltmak için birden fazla tur harcaması gerekir. Ancak bu, M2'ye kıyasla büyük bir gelişmedir. C projesi testinde, çoğu yerli model ilk 2 turda takılırken, M2.5 8. tura ulaşan ilk yerli model oldu. M2.5'in OpenGL kullanımı ve uzamsal hayal gücünde belirgin eksiklikleri olmasına rağmen, optimize edilmiş Agent yeteneği ile sürekli deneme yanılma yoluyla doğru çözüme yakınsayabilir. Ayrıca, M2.5'in programlama yaparken daha az "konuştuğu", neredeyse yalnızca işi tamamladıktan sonra kısa bir özet verdiği, ara aşamalarda düşüncelerini paylaşmadığı da dikkat çekicidir. Diğer projeler hala test aşamasındadır ve daha sonra güncellenecektir.
- Hesaplama Yeteneği: M2'nin hesaplama yeteneği mükemmel sayılmazken, M2.1 daha da geriledi. M2.5, düşük bir başlangıç noktasından etkili iyileştirmeler yaptı. Basit hesaplamaların çoğunda, M2.5 küçük bir olasılıkla yüksek hassasiyet gösterirken, çoğu durumda hala yanlış hesaplama, büyük hata ve formülleri anlamama sorunları yaşanmaktadır. Bu alandaki eğitim hala yetersizdir. Agent güdümlü bir model olarak, hesaplama yeteneği bir zorunluluk değildir, Claude serisinin hesaplama yeteneği de uzun süredir geridedir.
Eksiklikler
- Talimatlara Uyma: M2'ye kıyasla, talimatlara uymadaki iyileşme önemli değil. Bazı basit sorunlarda tam puan alma olasılığı daha yüksek olsa da, bu da istikrarlı değil. Talimatları rastgele atma veya değiştirme durumları var, ancak düşünce zinciri içeriği incelendiğinde, modelin tüm talimatları fark ettiği, ancak nihai çıktıda sorun çıktığı görülüyor. Genel performans, ilk kademedeki diğer modellerin gerisinde. Programlamada da kodlama gereksinimlerini ve proje standartlarını göz ardı etme durumları ortaya çıkabiliyor. Örneğin, C projesinde Z ekseninin yukarı bakması gerektiği belirtilmiş olsa da, M2.5 başka bir hatayı düzeltmek için kendi başına Y eksenini yukarı bakacak şekilde değiştirmiş. Günlük kullanımda ek kontrol gereklidir.
- Halüsinasyon: M2.5'in halüsinasyon seviyesi, M2'ye göre önemli bir değişiklik göstermedi. Bağlama dayalı sorunların çoğunda, her ikisinin de maksimum puanı aynı. Hatta #43 Hedef Sayı Hesaplama sorununda, M2.5, ikinci kademe modellerin bile yapabileceği sayıları tekrar kullanma, sayıları atlama gibi basit hatalar yapabiliyor.
Siber Tarihçi Der ki
Yerli üreticiler, programlama modellerinin nasıl yapılması gerektiğini keşfetmek için yarım yıldan fazla zaman harcadılar. İlk başta Sonnet'e alternatif olduğunu iddia eden modellerin çoğu, yalnızca "tek cümlelik" oluşturma efektinde yakın görünüyordu. İçsel kod organizasyonu, mühendislik ve daha da önemlisi çok turlu yineleme yeteneği çok daha gerideydi. Bu da yerli programcıların genellikle yerli modellere güvenmemesine ve hesaplarının kapatılma riskine rağmen Claude'u kullanmayı tercih etmesine neden oldu.
MiniMax M2, M2.1 ile rüzgarı tersine çevirmeye başlamasıyla, M2.5 nesli yerli model programlama kullanılabilirliğini bir adım daha ileri taşıdı. Gerçekten de M2.5 ile resmi olarak ilan edilen Opus seviyesi arasında her açıdan fark var, ancak birileri güvenmeye ve kullanmaya istekli olduğu sürece, işler iyiye doğru gidecektir. Bu açıdan bakıldığında, M2.5, 稀宇'nun zafere giden yolda attığı sağlam bir adımdır.





