Want to Understand the Codex Agent? Don't Miss This In-Depth Analysis!
Want to Understand the Codex Agent? Don't Miss This In-Depth Analysis!
OpenAI just did something "unusual."
Usually, OpenAI releases stronger models (like o1), but this time, they released an in-depth technical blog post, "Unrolling the Codex agent loop," which not only open-sourced the core logic of the Codex CLI but also meticulously dissected how a mature Coding Agent actually runs.

In the current environment where Claude Code and Cursor are wildly popular, this article from OpenAI is not just flexing its muscles but also a "pitfall avoidance guide for Agent architects." Whether you want to use AI programming tools effectively or develop your own Agent, this article is worth reading word by word.
The full text is over 8300 words and takes about 20 minutes to read.
First, what is Codex CLI?
Codex CLI is an open-source coding Agent tool produced by OpenAI that can be run on a local computer or installed in a code editor. It supports VS Code, Cursor, Windsurf, etc.
Open source address: https://github.com/openai/codex
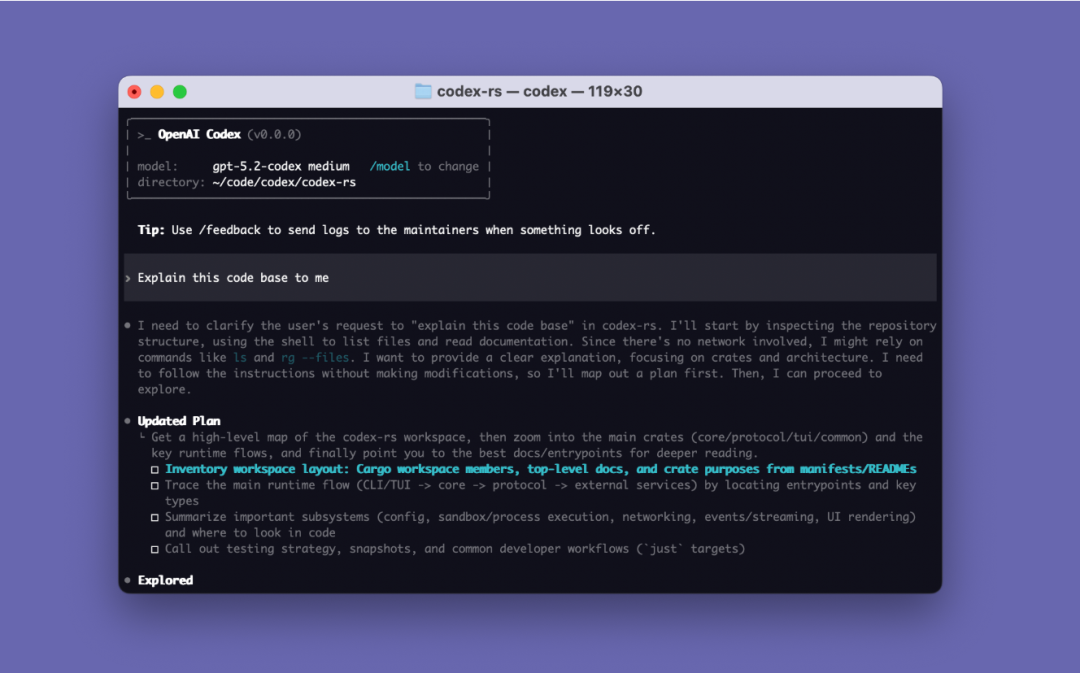
The Agent Loop, which will be introduced this time, is the core logic of Codex CLI: it is responsible for coordinating users, models, and model calls to execute valuable interactions between tools.
Agent Loop
Models are just components; only Agents can constitute products.
The core of every AI Agent is the so-called "Agent Loop." A schematic diagram of the agent loop is shown below:
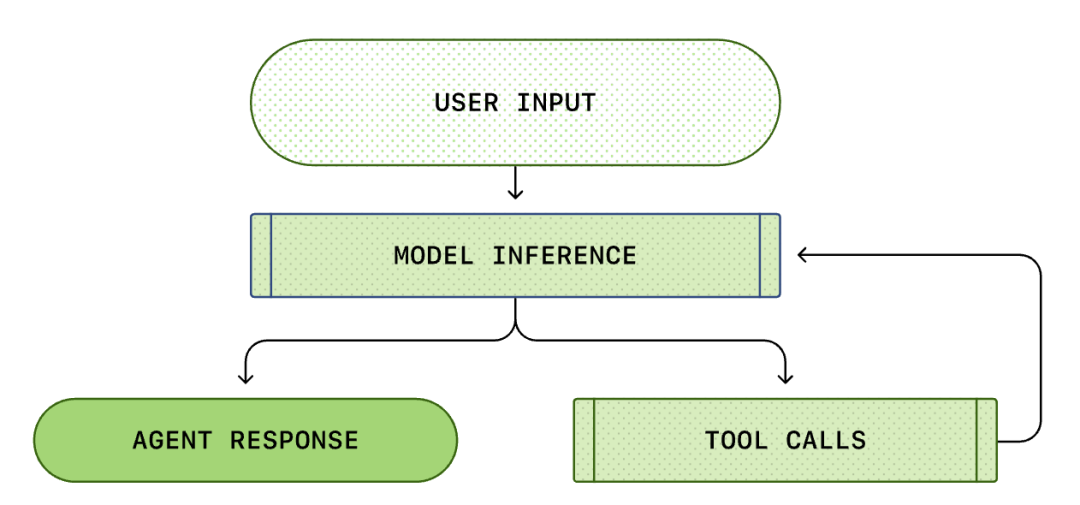
We usually think of AI programming as: "I ask, it answers." But within Codex CLI, this is a complex, infinite loop process...
A standard Agent Loop includes the following steps:
- User Instructions: A set of text instructions entered by the user (e.g., "refactor this function").
- Model Inference: The model decides whether to answer directly or call a tool (Tool Call).
- Tool Call: If the model decides to call list files or run shell, the CLI executes these commands locally.
- Observation: The results of the tool execution (code, errors, file lists) are captured.
- Loop: These results are appended to the conversation history and fed back to the model. After seeing the results, the model decides on the next step.
- Termination: The model outputs the final response when it believes the task is complete.
The entire process from "user input" to "agent response" is called a turn of the conversation (called a thread in Codex).
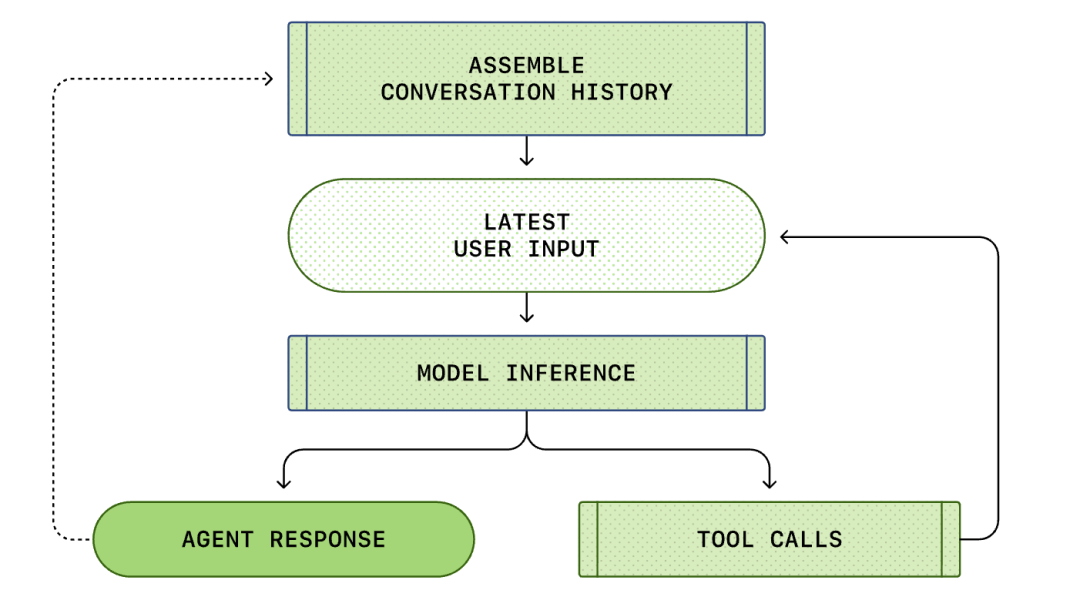
As the conversation progresses, the length of the Prompt used to reason about the model also increases. This length is important because each model has a context window, which represents the maximum number of tokens the model can use in a single inference call.
Model Inference
Codex CLI sends HTTP requests to the Responses API for model inference. Codex uses the Responses API to drive the agent loop.
What is the Responses API?
The Responses API is a new generation of agent development interface launched by OpenAI in March 2025, designed to unify dialogue, tool calling, and multi-modal processing capabilities, providing developers with a more flexible and powerful AI application building experience.
The Responses API endpoint used by Codex CLI is configurable and can be used with any endpoint that implements the Responses API.
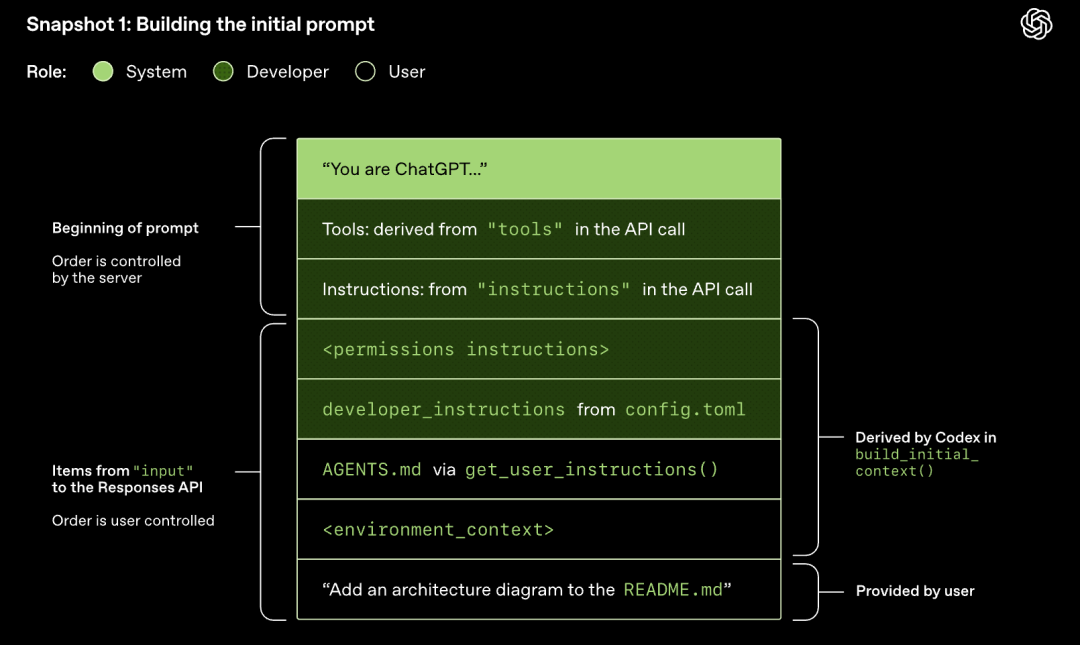
Model Sampling (Generating Responses)
The HTTP request initiated to the Responses API starts the first "turn" in the Codex conversation. The server streams the response back via Server-Sent Events (SSE).
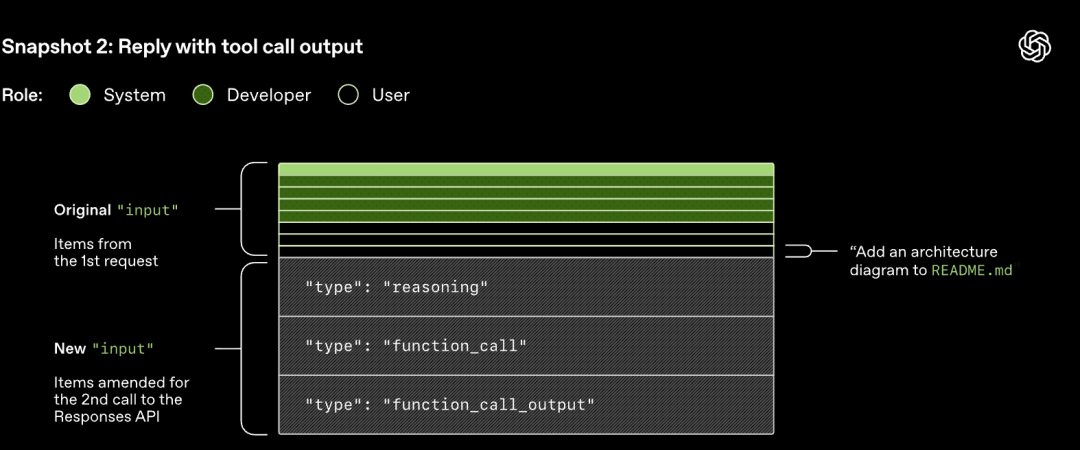
Note that the prompt from the previous round is an exact prefix of the new prompt. This design can significantly improve the efficiency of subsequent requests - the prompt caching mechanism can be utilized.

Impact of Prompt Continuously Lengthening with Increasing Turns
1. Performance Aspects
- Increased Model Sampling Cost: The continuous lengthening of prompts increases the cost of model sampling because the sampling process needs to process more data, leading to an increase in computation.
- Reduced Caching Benefits: As prompts continuously lengthen with increasing turns, the difficulty of exact prefix matching increases, and the likelihood of cache hits decreases.
2. Context Window Management Aspects
- Context Window Easily Exhausted: The continuous lengthening of prompts causes the number of tokens in the conversation to increase rapidly, and once the threshold of the context window is exceeded, it may lead to context window exhaustion.
- Increased Necessity of Compression Operations: To avoid context window exhaustion, it is necessary to compress the conversation when the number of tokens exceeds the threshold.
3. Cache Miss Risk Aspects
- Multiple Operations Easily Trigger Cache Misses: If operations such as changing the model's available tools, target model, or sandbox configuration are involved due to prompt lengthening, the risk of cache misses will further increase.
- MCP Tools Increase Complexity: MCP servers can dynamically change the list of provided tools, and responding to relevant notifications in long conversations can lead to cache misses.
Reference Information: "Unrolling the Codex agent loop" Source: OpenAI



