Zhipu GLM-5's Open Source Release: Are Senior Programmers Now in Danger?
Seriously, AI in 2026 is much crazier than in 2025.
Recently, even I, who spends 16 hours a day immersed in AI, am finding it hard to keep up with the pace of AI evolution. It feels like the world changes every time I open my eyes.
Just last night, Zhipu dropped another bombshell, directly open-sourcing their current strongest flagship model: GLM-5.
In the globally recognized Artificial Analysis ranking, GLM-5 surpassed Gemini to become fourth globally and first among open-source models!
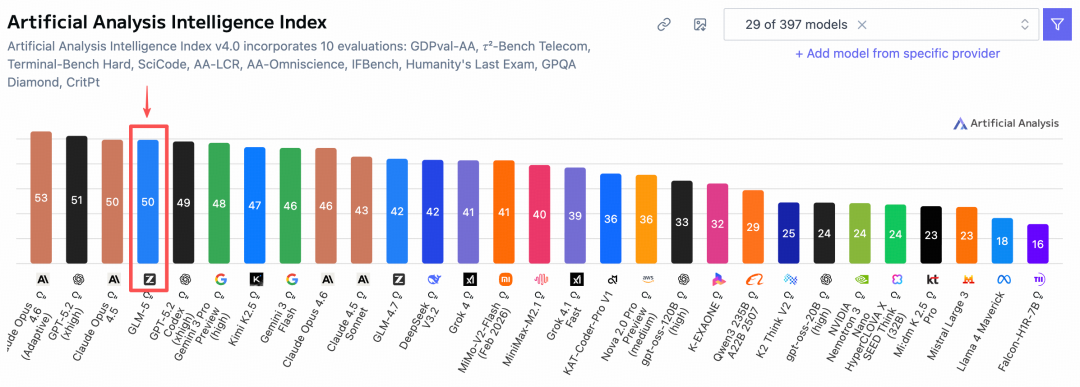
It's just as I expected! I remember when GLM-4.7 was released, I predicted in my article that GLM-4.8 or GLM-5 would be released before the Spring Festival. I didn't expect it to actually happen, haha 😄
And this time, the version number isn't like the previous incremental updates of 4.5, 4.6, and 4.7. This time, it jumps directly to 5.0.
This indicates that it's not just a minor fix, but a significant leap in the underlying capabilities.
Let me introduce what GLM-5 has updated this time:
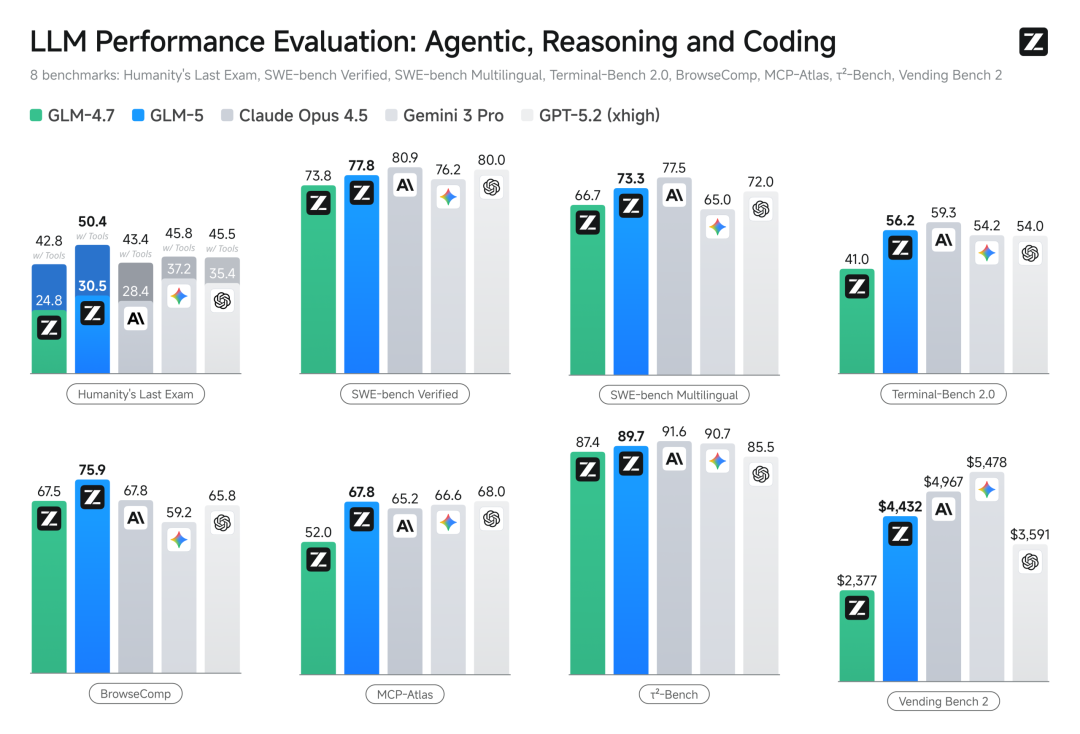
In short, previous models were generally focused on Vibe Coding, which is the so-called one-sentence generation, seeing who can generate more dazzling web effects, or who can create a cool game with one sentence.
But GLM-5 is not competing in this area this time (finally!). It has elevated the capabilities of large models from writing code to building systems.
What does this mean? Its focus is no longer on writing beautiful front-end pages, but on evolving into a system architect who can handle dirty work, hard work, and long tasks.
The emphasis is on Agentic Engineering, which is the capability of intelligent agent engineering.
I looked at the official data, the parameter scale has increased from 355B to 744B (activation 40), and the pre-training data has increased from 23T to 28.5T.
In the recognized programming benchmark test, SWE-bench-Verified, it scored 77.8, directly leaving Gemini 3 Pro behind, and is comparable to the currently recognized strongest closed-source model, Claude Opus 4.5.
Currently, it can be used for free on z.ai:
Open Source Address:
GitHub: https://github.com/zai-org/GLM-5
Hugging Face: https://huggingface.co/zai-org/GLM-5
ModelScope: https://modelscope.cn/models/ZhipuAI/GLM-5
In fact, a few days ago, a mysterious model called Pony suddenly appeared on X.
At that time, many friends were guessing, who is this Pony? There were many opinions.
In fact, the model codenamed Pony is GLM-5. As for why it's called Pony, it's probably because the Year of the Horse is coming soon 🤔.
I also immediately connected Pony from OpenRouter to Claude Code for a trial. To be honest, it's really strong (it's also very popular on X).
It only took 7 minutes to generate an API relay station in one go!
Although it's still an MVP Demo, the page functions are already very complete, and it includes back-end logic and a database. The data is dynamic, and it's small but complete.
 After a deep experience, I found that GLM-5's planning style is very similar to Claude Opus.
After a deep experience, I found that GLM-5's planning style is very similar to Claude Opus.
Friends who are familiar with Claude Opus know that before starting work, it can give you a very detailed and logically rigorous plan.
GLM-5 now has this capability as well.
For example, I have something I've always wanted to do, but I've been too lazy to do it.
I have a bunch of membership accounts for Gemini, ChatGPT, Kimi, Zhipu, etc.
When writing articles or researching information, I often want to hear the opinions of multiple AIs and compare them comprehensively. Then I would have to open multiple browser windows, copy and switch between different windows to paste and send multiple times, and then switch windows in turn to view the results.
Although it's not a big deal, it's really annoying when it happens often.
I was wondering, can I make a browser plugin that can send the same question to the web interfaces of these four AIs in one window, and then receive the replies uniformly in the plugin?
But this thing is quite troublesome, because the structure of each AI website is different, and there are various protection mechanisms, so I need to analyze their DOM structure.
So, I handed over this complex task to GLM-5.
I enabled Claude Code's Plan Mode to let it make a plan first.
Then it will also interact with me and ask for my opinion:
The final plan is very detailed, really too long, with 633 lines..
Then I started to execute it according to the plan, but I didn't expect the first step of initializing the project to take more than 50 minutes..
In this process, it automatically called the Playwright MCP tool, opened the browser by itself, and visited the websites of those AIs.
It's like a real programmer, checking elements, analyzing where the input box is, what the Class of the send button is, how to get the returned text stream... the whole process is automatic, I didn't write a single line of code.
PS: I forgot to record the screen, because I was running another task in other windows at the same time.
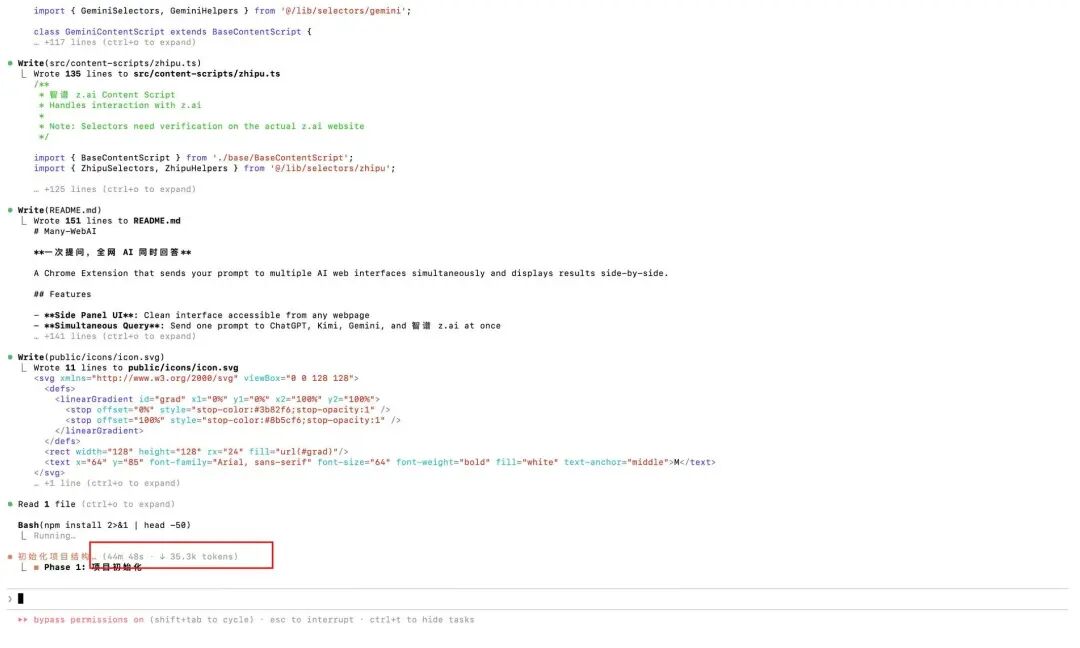 Waiting is worth it, the plugin I wanted, which allows me to ask a question once and get answers from all AIs on the network at the same time, was freshly baked.
Waiting is worth it, the plugin I wanted, which allows me to ask a question once and get answers from all AIs on the network at the same time, was freshly baked.
This is exactly what I need~
In addition, I made a digital human marketing video one-click generation platform before.
Later, in order to pursue a better experience, I refactored the front end. This refactoring was a big deal, and the whole project can be said to be a mess: the front and back end interfaces didn't match, some old logic in the back end couldn't run in front of the new front end, there were many bugs, and it was very troublesome to fix.
This time, I turned on plan mode in Claude Code, and then directly threw the task of finding and fixing bugs in the main process to GLM-5.
First, a detailed plan came out:
After confirming that the plan was correct, I let it start executing it (the browser mcp was used to control it in the process).
Its execution speed is not fast.
But it's not that the model is slow. Many times, I see the consumption speed of that Token, and it visibly jumps to thousands in a second.
But because the task is too complex, it needs to constantly self-reflect, call tools, and run tests.
Some time is also spent on dependency downloads or command execution.
This repair task also took more than 40 minutes.
Some friends may say, 40 minutes? I've already finished writing it.
Emmm, but in these 40 minutes, I turned on the screen recording, watched videos, and even walked the dog.
And it was concentrating on helping me with my work, and it was doing the kind of work that makes people's heads bald, finding bugs and refactoring.
Don't look at its slow execution, but the final effect is very significant.
As soon as I ran it, wow, the problems were basically solved.
Please watch the VCR:
There are also some effects that I found small bugs when I tested it myself later, and then asked it to fix and optimize them.
But in terms of fixing bugs and optimizing functions, I am really relieved to hand it over to it.
In the past, when using other AIs to fix bugs, I was often worried that the more bugs were fixed, the more chaotic the project would become, and the typical case of robbing Peter to pay Paul..
In order to avoid this problem before, I had to use various engineering methods to constrain the AI.
For example, emphasize the scope of each modification, or write these into the rules, or only change one bug at a time, and test other functions after each change... anyway, it's very troublesome.
But using GLM-5 to fix bugs, the experience has completely changed.
I only need to describe the current situation, throw the error log to it, and tell it what I expect the effect to be.
It can almost fix it successfully at once, and it will not affect other functions at all.
Even, in one conversation, I directly threw all four different bugs found in the entire process to it, and it can fix them one by one in a clear and organized manner.
This stable feeling is really comfortable.
I can now safely hand over any complex development tasks to GLM-5 to complete, and it will basically not make mistakes.
Even if there is a problem occasionally, I can just execute the rollback command in Claude Code and go back and start over.
After optimizing the entire project with GLM-5, all the processes are basically completed."Finally"
After experiencing GLM-5, my biggest feeling is: Domestic AI has truly stood up.
The other day, ByteDance's Seedance 2.0 was released, proving that Chinese domestic models have reached the world's top level in the field of video generation, directly surpassing Sora2 and Veo3.1.
And this time, the release of Zhipu GLM-5 has delivered an unexpected answer in another hardcore track, AI Coding.
We used to say that domestic models still have a gap with GPT, Claude Opus, and Gemini in logical reasoning and writing code.
But today, GLM-5 tells us with solid performance: This gap is being narrowed.
GLM-5 is not just a toy that can only be used for demos; it is a productivity tool that can truly help you work, build systems, solve long tasks, and complex problems.
Most importantly, it is open source.
This means that every developer and every enterprise can have a top-notch AI architect at a lower cost.
Moreover, GLM's Coding Plan is already selling like crazy. The official announcement says that they are urgently expanding capacity, and the key point is that this time it is connected to a cluster of ten thousand cards using domestic chips.
However, due to the increased investment in computing power, the price has increased somewhat. Fortunately, I got the Max package before.
From this, we can also see that from chips to models, from underlying computing power to upper-level applications, we are building a completely our own, world-class AI technology stack.
2026 is destined to be a year of explosive growth in AI applications, and an even crazier year.
If you also want to experience the feeling of having a top-notch AI architect, go and try GLM-5.The prerequisite is that you have to grab the Max package, haha.



