107ページのRAGとAgent&LLMの記憶に関する包括的なレビュー
2/15/2026
2 min read
本日は、中国人民大学、復旦大学、北京大学などが共同で発表した107ページにわたる技術レビュー「Memory in the Age of AI Agents: A Survey Forms, Functions and Dynamics」をご紹介します。
プロジェクトのURL:https://github.com/Shichun-Liu/Agent-Memory-Paper-List
論文のURL:https://arxiv.org/pdf/2512.13564
 過去2年間で、大規模言語モデル(LLM)からAIエージェント(AI Agents)への驚くべき進化が見られました。Deep Researchからソフトウェアエンジニアリング、科学的発見からマルチエージェントコラボレーションまで、これらの基盤モデルに基づくエージェントは、人工汎用知能(AGI)の境界を押し広げています。
しかし、中心的な問題が浮上しています。**静的なLLMパラメータは迅速に更新できず、エージェントに継続的な学習と適応能力をどのように持たせるか?**
その答えは——**記憶(Memory)**です。
> "記憶は、静的なLLMを、環境とのインタラクションを通じて継続的に適応できるインテリジェントなエージェントに変えるための重要な能力です。"
過去2年間で、大規模言語モデル(LLM)からAIエージェント(AI Agents)への驚くべき進化が見られました。Deep Researchからソフトウェアエンジニアリング、科学的発見からマルチエージェントコラボレーションまで、これらの基盤モデルに基づくエージェントは、人工汎用知能(AGI)の境界を押し広げています。
しかし、中心的な問題が浮上しています。**静的なLLMパラメータは迅速に更新できず、エージェントに継続的な学習と適応能力をどのように持たせるか?**
その答えは——**記憶(Memory)**です。
> "記憶は、静的なLLMを、環境とのインタラクションを通じて継続的に適応できるインテリジェントなエージェントに変えるための重要な能力です。"
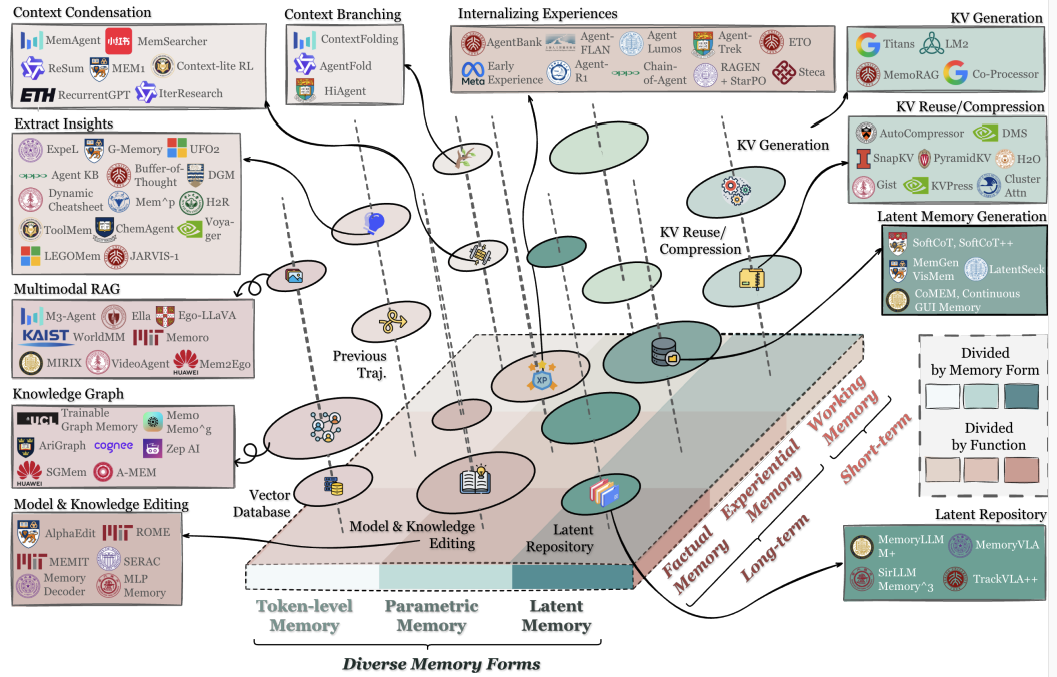 **Figure 1** は、論文で提案されている統一された分類フレームワークを示しており、エージェントの記憶を**形式(Forms)**、**機能(Functions)**、**動態(Dynamics)**の3つの次元で整理し、代表的なシステムをこの分類体系にマッピングしています。
**Figure 1** は、論文で提案されている統一された分類フレームワークを示しており、エージェントの記憶を**形式(Forms)**、**機能(Functions)**、**動態(Dynamics)**の3つの次元で整理し、代表的なシステムをこの分類体系にマッピングしています。
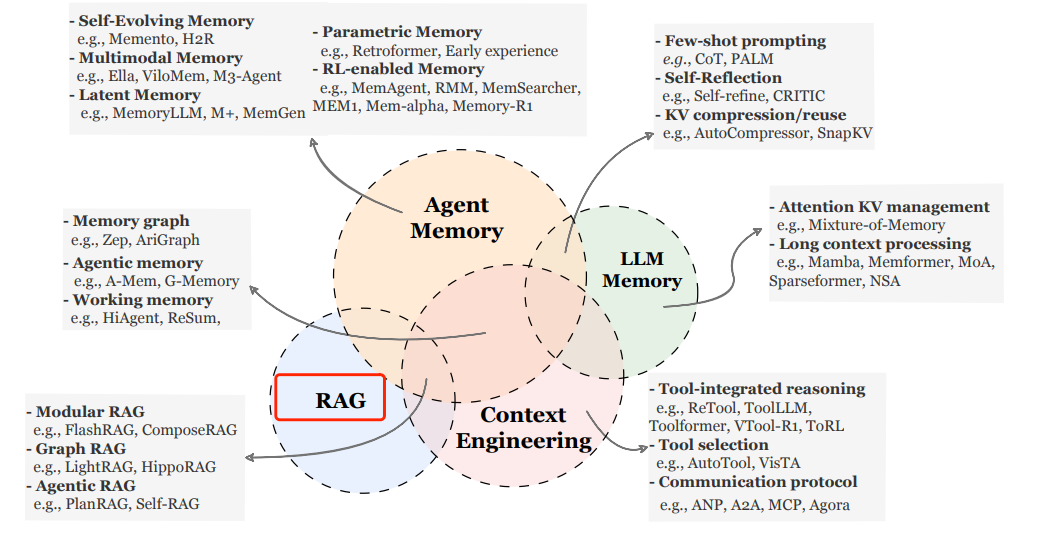 論文では、Agent Memoryと、密接に関連しているものの本質的に異なる概念である**LLM記憶**、**検索拡張生成(RAG)**、**コンテキストエンジニアリング**との明確な区別も行っています。これらはすべて情報の保存と利用に関連していますが、目標、メカニズム、およびアプリケーションシナリオに重要な違いがあります。
## エージェント記憶技術
- **Self-Evolving Memory**:Memento, H2R
- **Multimodal Memory**:Ella, ViloMem, M3-Agent
- **Latent Memory**:MemoryLLM, M+, MemGen
- **Parametric Memory**:Retroformer, Early experience
- **RL-enabled Memory**:MemAgent, RMM, MemSearcher, MEM1, Mem-alpha, Memory-R1
## エージェント記憶 vs. RAG
RAG関連技術:
- **Modular RAG**:FlashRAG, ComposeRAG
- **Graph RAG**:LightRAG, HippoRAG
- **Agentic RAG**:PlanRAG, Self-RAG
RAGとエージェント記憶はどちらも、外部ストレージから情報を検索してモデルの能力を強化することを含みますが、両者の設計哲学には本質的な違いがあります。
特徴 | RAG | エージェント記憶
---|---|---
コア目標 | 現在のクエリに関連する背景知識のサポート | 時間を超えた継続的な学習と適応行動
情報源 | 通常は静的な、事前に構築された知識ベース | 動的に生成された、エージェント自身のインタラクション経験からのパーソナライズされた情報
検索トリガー | ユーザーのクエリによって受動的にトリガーされる | エージェントがいつ、何を検索するかを積極的に決定する
情報更新 | 知識ベースは通常オフラインで更新される | オンラインで、継続的に、選択的に更新される
フィードバックループ | 直接的なフィードバックメカニズムなし | 環境とのインタラクションで閉ループを形成する
**重要な違い**:RAGは**知識拡張ツール**であり、エージェント記憶は**学習メカニズム**です。RAGは「私は何を知っているか」に答え、エージェント記憶は「私は何を学んだか」に答えます。
## エージェント記憶 vs. LLM記憶
LLM記憶関連技術:
- **Attention KV management**:Mixture-of-Memory
- **Long context processing**:Mamba, Memformer, MoA, Sparseformer, NSA
次元 | LLM記憶 | エージェント記憶
---|---|---
定義 | モデルパラメータに内包された知識、またはコンテキストウィンドウ内の一時的な情報 | エージェントが環境と継続的にインタラクションし、タスクを越えて学習し、長期的に適応するための外部システム
時間スケール | プリトレーニングデータまたは現在の対話コンテキストに限定される | 複数のタスク、セッションにまたがり、生涯学習をサポートする
更新可能性 | パラメータの更新コストが高い、コンテキスト情報は失われやすい | 効率的で、選択的な動的更新と進化をサポートする
積極性 | クエリに受動的に応答する | どのような情報を保存、更新、検索するかを積極的に決定する
環境との結合 | 環境との直接的なインタラクションなし | 環境フィードバックを深く統合し、インタラクティブな学習をサポートする
**重要な違い**:LLM記憶は本質的に**静的**(パラメータ固定)または**一時的**(コンテキスト制限)ですが、エージェント記憶は**動的、永続的、環境結合的**です。
## エージェント記憶 vs. コンテキストエンジニアリング
コンテキストエンジニアリング関連技術:
- **Tool-integrated reasoning**:ReTool, ToolLLM, Toolformer, VTool-R1, ToRL
- **Tool selection**:AutoTool, VisTA
- **Communication protocol**:ANP, A2A, MCP, Agora
側面 | コンテキストエンジニアリング | エージェント記憶
---|---|---
焦点 | 単一ラウンドまたは現在のタスクの入力最適化 | 複数ラウンド、複数タスクにわたる情報の永続化と利用
時間次元 | 現在のセッション | 長期的な履歴
情報選択 | 人工的な設計またはヒューリスティックルール | 自動化された形成、進化、検索メカニズム
状態管理 | 永続的な状態なし | 進化可能な記憶状態を明示的に維持する
**重要な違い**:コンテキストエンジニアリングは**プロンプト最適化技術**であり、エージェント記憶は**状態管理システム**です。前者は「今、何を入力するか」に焦点を当て、後者は「過去に何を記憶し、それが現在と未来にどのように影響するか」に焦点を当てます。
論文では、Agent Memoryと、密接に関連しているものの本質的に異なる概念である**LLM記憶**、**検索拡張生成(RAG)**、**コンテキストエンジニアリング**との明確な区別も行っています。これらはすべて情報の保存と利用に関連していますが、目標、メカニズム、およびアプリケーションシナリオに重要な違いがあります。
## エージェント記憶技術
- **Self-Evolving Memory**:Memento, H2R
- **Multimodal Memory**:Ella, ViloMem, M3-Agent
- **Latent Memory**:MemoryLLM, M+, MemGen
- **Parametric Memory**:Retroformer, Early experience
- **RL-enabled Memory**:MemAgent, RMM, MemSearcher, MEM1, Mem-alpha, Memory-R1
## エージェント記憶 vs. RAG
RAG関連技術:
- **Modular RAG**:FlashRAG, ComposeRAG
- **Graph RAG**:LightRAG, HippoRAG
- **Agentic RAG**:PlanRAG, Self-RAG
RAGとエージェント記憶はどちらも、外部ストレージから情報を検索してモデルの能力を強化することを含みますが、両者の設計哲学には本質的な違いがあります。
特徴 | RAG | エージェント記憶
---|---|---
コア目標 | 現在のクエリに関連する背景知識のサポート | 時間を超えた継続的な学習と適応行動
情報源 | 通常は静的な、事前に構築された知識ベース | 動的に生成された、エージェント自身のインタラクション経験からのパーソナライズされた情報
検索トリガー | ユーザーのクエリによって受動的にトリガーされる | エージェントがいつ、何を検索するかを積極的に決定する
情報更新 | 知識ベースは通常オフラインで更新される | オンラインで、継続的に、選択的に更新される
フィードバックループ | 直接的なフィードバックメカニズムなし | 環境とのインタラクションで閉ループを形成する
**重要な違い**:RAGは**知識拡張ツール**であり、エージェント記憶は**学習メカニズム**です。RAGは「私は何を知っているか」に答え、エージェント記憶は「私は何を学んだか」に答えます。
## エージェント記憶 vs. LLM記憶
LLM記憶関連技術:
- **Attention KV management**:Mixture-of-Memory
- **Long context processing**:Mamba, Memformer, MoA, Sparseformer, NSA
次元 | LLM記憶 | エージェント記憶
---|---|---
定義 | モデルパラメータに内包された知識、またはコンテキストウィンドウ内の一時的な情報 | エージェントが環境と継続的にインタラクションし、タスクを越えて学習し、長期的に適応するための外部システム
時間スケール | プリトレーニングデータまたは現在の対話コンテキストに限定される | 複数のタスク、セッションにまたがり、生涯学習をサポートする
更新可能性 | パラメータの更新コストが高い、コンテキスト情報は失われやすい | 効率的で、選択的な動的更新と進化をサポートする
積極性 | クエリに受動的に応答する | どのような情報を保存、更新、検索するかを積極的に決定する
環境との結合 | 環境との直接的なインタラクションなし | 環境フィードバックを深く統合し、インタラクティブな学習をサポートする
**重要な違い**:LLM記憶は本質的に**静的**(パラメータ固定)または**一時的**(コンテキスト制限)ですが、エージェント記憶は**動的、永続的、環境結合的**です。
## エージェント記憶 vs. コンテキストエンジニアリング
コンテキストエンジニアリング関連技術:
- **Tool-integrated reasoning**:ReTool, ToolLLM, Toolformer, VTool-R1, ToRL
- **Tool selection**:AutoTool, VisTA
- **Communication protocol**:ANP, A2A, MCP, Agora
側面 | コンテキストエンジニアリング | エージェント記憶
---|---|---
焦点 | 単一ラウンドまたは現在のタスクの入力最適化 | 複数ラウンド、複数タスクにわたる情報の永続化と利用
時間次元 | 現在のセッション | 長期的な履歴
情報選択 | 人工的な設計またはヒューリスティックルール | 自動化された形成、進化、検索メカニズム
状態管理 | 永続的な状態なし | 進化可能な記憶状態を明示的に維持する
**重要な違い**:コンテキストエンジニアリングは**プロンプト最適化技術**であり、エージェント記憶は**状態管理システム**です。前者は「今、何を入力するか」に焦点を当て、後者は「過去に何を記憶し、それが現在と未来にどのように影響するか」に焦点を当てます。
過去2年間で、大規模言語モデル(LLM)からAIエージェント(AI Agents)への驚くべき進化が見られました。Deep Researchからソフトウェアエンジニアリング、科学的発見からマルチエージェントコラボレーションまで、これらの基盤モデルに基づくエージェントは、人工汎用知能(AGI)の境界を押し広げています。
しかし、中心的な問題が浮上しています。**静的なLLMパラメータは迅速に更新できず、エージェントに継続的な学習と適応能力をどのように持たせるか?**
その答えは——**記憶(Memory)**です。
> "記憶は、静的なLLMを、環境とのインタラクションを通じて継続的に適応できるインテリジェントなエージェントに変えるための重要な能力です。"
**Figure 1** は、論文で提案されている統一された分類フレームワークを示しており、エージェントの記憶を**形式(Forms)**、**機能(Functions)**、**動態(Dynamics)**の3つの次元で整理し、代表的なシステムをこの分類体系にマッピングしています。
論文では、Agent Memoryと、密接に関連しているものの本質的に異なる概念である**LLM記憶**、**検索拡張生成(RAG)**、**コンテキストエンジニアリング**との明確な区別も行っています。これらはすべて情報の保存と利用に関連していますが、目標、メカニズム、およびアプリケーションシナリオに重要な違いがあります。
## エージェント記憶技術
- **Self-Evolving Memory**:Memento, H2R
- **Multimodal Memory**:Ella, ViloMem, M3-Agent
- **Latent Memory**:MemoryLLM, M+, MemGen
- **Parametric Memory**:Retroformer, Early experience
- **RL-enabled Memory**:MemAgent, RMM, MemSearcher, MEM1, Mem-alpha, Memory-R1
## エージェント記憶 vs. RAG
RAG関連技術:
- **Modular RAG**:FlashRAG, ComposeRAG
- **Graph RAG**:LightRAG, HippoRAG
- **Agentic RAG**:PlanRAG, Self-RAG
RAGとエージェント記憶はどちらも、外部ストレージから情報を検索してモデルの能力を強化することを含みますが、両者の設計哲学には本質的な違いがあります。
特徴 | RAG | エージェント記憶
---|---|---
コア目標 | 現在のクエリに関連する背景知識のサポート | 時間を超えた継続的な学習と適応行動
情報源 | 通常は静的な、事前に構築された知識ベース | 動的に生成された、エージェント自身のインタラクション経験からのパーソナライズされた情報
検索トリガー | ユーザーのクエリによって受動的にトリガーされる | エージェントがいつ、何を検索するかを積極的に決定する
情報更新 | 知識ベースは通常オフラインで更新される | オンラインで、継続的に、選択的に更新される
フィードバックループ | 直接的なフィードバックメカニズムなし | 環境とのインタラクションで閉ループを形成する
**重要な違い**:RAGは**知識拡張ツール**であり、エージェント記憶は**学習メカニズム**です。RAGは「私は何を知っているか」に答え、エージェント記憶は「私は何を学んだか」に答えます。
## エージェント記憶 vs. LLM記憶
LLM記憶関連技術:
- **Attention KV management**:Mixture-of-Memory
- **Long context processing**:Mamba, Memformer, MoA, Sparseformer, NSA
次元 | LLM記憶 | エージェント記憶
---|---|---
定義 | モデルパラメータに内包された知識、またはコンテキストウィンドウ内の一時的な情報 | エージェントが環境と継続的にインタラクションし、タスクを越えて学習し、長期的に適応するための外部システム
時間スケール | プリトレーニングデータまたは現在の対話コンテキストに限定される | 複数のタスク、セッションにまたがり、生涯学習をサポートする
更新可能性 | パラメータの更新コストが高い、コンテキスト情報は失われやすい | 効率的で、選択的な動的更新と進化をサポートする
積極性 | クエリに受動的に応答する | どのような情報を保存、更新、検索するかを積極的に決定する
環境との結合 | 環境との直接的なインタラクションなし | 環境フィードバックを深く統合し、インタラクティブな学習をサポートする
**重要な違い**:LLM記憶は本質的に**静的**(パラメータ固定)または**一時的**(コンテキスト制限)ですが、エージェント記憶は**動的、永続的、環境結合的**です。
## エージェント記憶 vs. コンテキストエンジニアリング
コンテキストエンジニアリング関連技術:
- **Tool-integrated reasoning**:ReTool, ToolLLM, Toolformer, VTool-R1, ToRL
- **Tool selection**:AutoTool, VisTA
- **Communication protocol**:ANP, A2A, MCP, Agora
側面 | コンテキストエンジニアリング | エージェント記憶
---|---|---
焦点 | 単一ラウンドまたは現在のタスクの入力最適化 | 複数ラウンド、複数タスクにわたる情報の永続化と利用
時間次元 | 現在のセッション | 長期的な履歴
情報選択 | 人工的な設計またはヒューリスティックルール | 自動化された形成、進化、検索メカニズム
状態管理 | 永続的な状態なし | 進化可能な記憶状態を明示的に維持する
**重要な違い**:コンテキストエンジニアリングは**プロンプト最適化技術**であり、エージェント記憶は**状態管理システム**です。前者は「今、何を入力するか」に焦点を当て、後者は「過去に何を記憶し、それが現在と未来にどのように影響するか」に焦点を当てます。Published in Technology



