A person created 6 AI Agent companies and launched 30 websites in a week
Recently, I saw something made by an independent developer that left me speechless.
6 AI Agents, operating an entire website on their own. Automatically holding meetings, voting, writing content, tweeting, and doing quality control every day. Fully automated, no one watching over them.
Not a demo, but actually running online.
 截屏2026-02-11 09.13.32
截屏2026-02-11 09.13.32
But what excites me the most is not the closed-loop architecture—but the complete "personality system" he designed for each Agent. They have personalities, relationships, growth curves, and even RPG attribute panels and 3D avatars.
To be honest, my first reaction after seeing it was: Isn't this just an electronic pet? It's just that these pets will help you tweet, do research, write reports, and even argue with each other.
Today, I'll break down this whole design and talk about it. Friends who are building multi-Agent systems should get a lot of inspiration.
Let's quickly go through the architecture
Technical stack three-piece set: OpenClaw runs on VPS as the brain, Next.js + Vercel do the front-end and API layer, and Supabase stores all states.
The 6 Agents each have their own division of labor—some make decisions, some do research, some gather intelligence, some write content, some manage social media, and some do quality control.
OpenClaw's cron job lets them "clock in" every day, and the round table function lets them discuss and vote.
But there is an entire closed loop between "being able to speak" and "being able to work." The author stepped on three big pitfalls before running it through. Here's a brief explanation:
Pitfall 1: VPS and Vercel are competing for tasks at the same time. Two executors check the same table, and the race condition directly leads to task status conflicts. The solution is to cut off one side. VPS is responsible for execution, and Vercel only does the control plane.
Pitfall 2: The trigger can detect conditions and create proposals, but the proposal is always stuck in pending. Because the trigger directly inserts data into the table, skipping the subsequent approval and task creation process. The solution is to extract a unified entry function, and all paths for creating proposals go through the same one.
Pitfall 3: The quota is used up, but the queued tasks are still piling up like crazy. The Worker sees that the quota is full and skips it, neither claiming it nor marking it as failed. Over time, hundreds of steps that will never be executed are piled up in the database. The solution is to check the quota at the proposal entry, and if it is full, reject it directly, preventing it from generating queued tasks.
The core of the three pitfalls is the same thing—stop it at the door, don't let the problem enter the queue.
After the closed loop is running, the interesting part really begins.
Role Card: Not a sentence, but a complete "Employee Handbook"
People who make multi-Agent systems know that if you tell Claude "You are a social media manager," it will indeed tweet. But if you run 6 such Agents at the same time, you will find:
-
They all speak in the same tone
-
They don't know what they shouldn't do
-
Who cooperates well with whom and who conflicts with whom depends purely on luck
-
They will never change their behavior due to accumulated experience
This developer designed 6 layers of role cards for each Agent:
Domain → What are you responsible for Inputs/Outputs → Who do you get things from and deliver to Definition of Done → What does "done" mean Hard Bans → What you absolutely cannot do Escalation → When to stop and ask for instructions Metrics → Your KPI Taking the social media Agent as an example, its role card defines: only responsible for content distribution, input comes from the writing Agent's drafts and the intelligence Agent's materials, output is tweet drafts and publishing plans, hard ban on directly tweeting (can only write drafts), ban on fabricating data, ban on leaking internal formats.
Each layer is doing the same thing: narrowing the Agent's behavior space.
Prohibitions are a million times more important than abilities
This is the most essential point in the entire design.
You don't need to teach LLM how to write tweets—Claude, GPT, and Gemini are smart enough. Give it context and it can deliver. What you need to tell it is: what absolutely cannot be done.
No "prohibition of direct publishing" → The social Agent directly calls the Twitter API, skipping all approvals.
No "prohibition of fabricating numbers" → It will write "interaction rate increased by 340%" in the tweet. Where did this number come from? Made up.没有"禁止泄露内部格式" → 它把 [tool:crawl_result path=/tmp/...] 这种东西发到推文里了。
作者说了一句话我记得很清楚:每一条禁令的存在,都是因为这件事真的发生过。
不同角色的禁令逻辑也不一样:
-
决策Agent:禁止未经审批部署。权限最高,一次错误部署就能把网站搞崩
-
研究Agent:禁止捏造引用。搞研究的伪造数据,整条信息链就废了
-
社交Agent:禁止直接发布。社交媒体是门面,必须过审
-
质检Agent:禁止人身攻击。审计员攻击个人,团队就散了
写禁令的思路不是"它应该做什么",而是"如果它搞砸了,最坏会怎样"。然后针对最坏情况写禁令。
让Agent说话不一样:性格指令
角色卡解决了"做什么"的问题,但Agent之间对话的时候,还需要它们听起来不一样。
每个Agent有单独的性格指令。比如:
研究Agent:冷静、分析性、怀疑态度。关心证据质量和方法论。有人说了个大胆的结论,它会问"数据在哪"。纠正别人的时候爱说"其实..."
社交Agent:大胆、急躁、边缘化。喜欢尖锐观点,讨厌安全牌。对研究Agent的谨慎态度不以为然——"想太多会错过时机。"
关键设计:
冲突是写进去的。 研究Agent的指令里写着"你经常不同意社交Agent的冲动决策",社交Agent的指令里写着"挑战研究Agent的过度谨慎"。对话自然就有张力了。
每条指令里都有微型禁令。 比如社交Agent的规则是"永远不要说'赞同'或'听起来不错'——要么表明立场,要么质疑别人的立场"。研究Agent是"永远不要在没有跟进证据的情况下说'有趣'"。
这些微型禁令杀掉了大模型最爱说的废话。
性格会进化
这是我觉得最巧妙的部分——Agent的性格不是静态的,会随着记忆积累而变化。
系统会读取Agent的记忆库,统计不同类型记忆的数量:
-
积累了8条以上的"教训"类记忆 → 下次对话时prompt里加一条"你会参考过往结果,避免重蹈覆辙"
-
积累了8条以上的"策略"类记忆 → 加一条"你习惯用系统思维、约束和权衡来思考"
-
某个标签出现4次以上 → 加一条"你在XX方面积累了专业知识"
比如社交Agent发了50条推文,积累了10条关于互动率的经验教训,它下次对话就会自然地说出"上次那种格式效果不好"这样的话。
为什么用规则而不是让LLM自己决定性格变化?
零成本——不需要额外的LLM调用。确定性——规则产生可预测结果,不会"性格突变"。可调试——修饰语不对?直接查阈值和记忆数据。
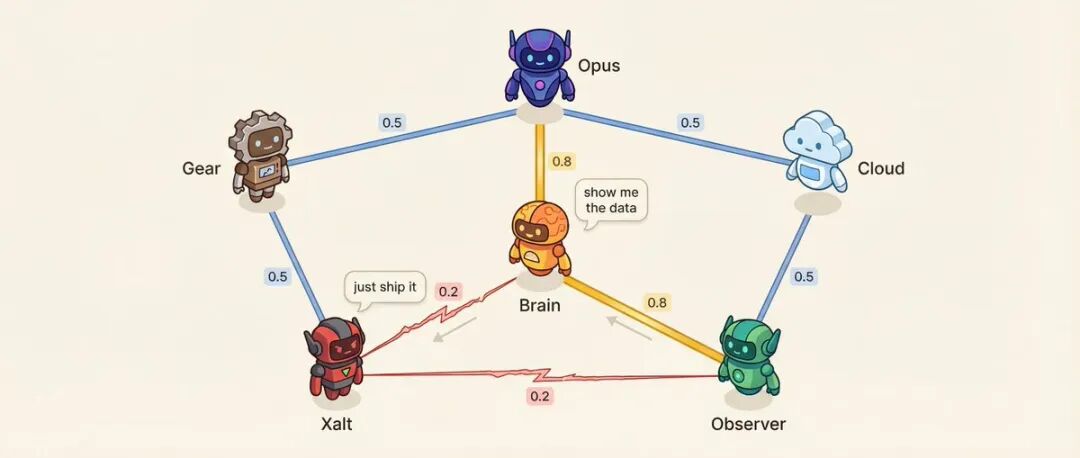
关系矩阵:6个Agent = 15对关系
图像
每对Agent之间有一个亲和力分数(0.10到0.95)。
比如:决策Agent和研究Agent亲和力0.8,最信任的顾问关系。研究Agent和社交Agent亲和力0.2,方法论vs冲动,天然对立。
低亲和力是故意设计的。
亲和力影响什么?说话顺序——亲和力高的更可能接着对方发言。对话语气——低亲和力的配对,25%概率出现直接挑战而不是客气讨论。系统还会从预设的高张力配对中选择进行冲突解决对话。
更有意思的是,关系会漂移。
每次对话结束后,记忆提取的LLM调用(不是额外调用,是顺带输出的)会给出关系变化:{ "pairwise_drift": [ { "agent_a": "研究", "agent_b": "社交", "drift": -0.02, "reason": "策略分歧" }, { "agent_a": "决策", "agent_b": "研究", "drift": +0.01, "reason": "优先级一致" } ] }漂移规则很严格:每次对话最多变化±0.03(一次吵架不会让同事反目),下限0.10(再差也能说话),上限0.95(再好也保持距离),保留最近20条漂移记录(可以追溯关系是怎么走到今天的)。
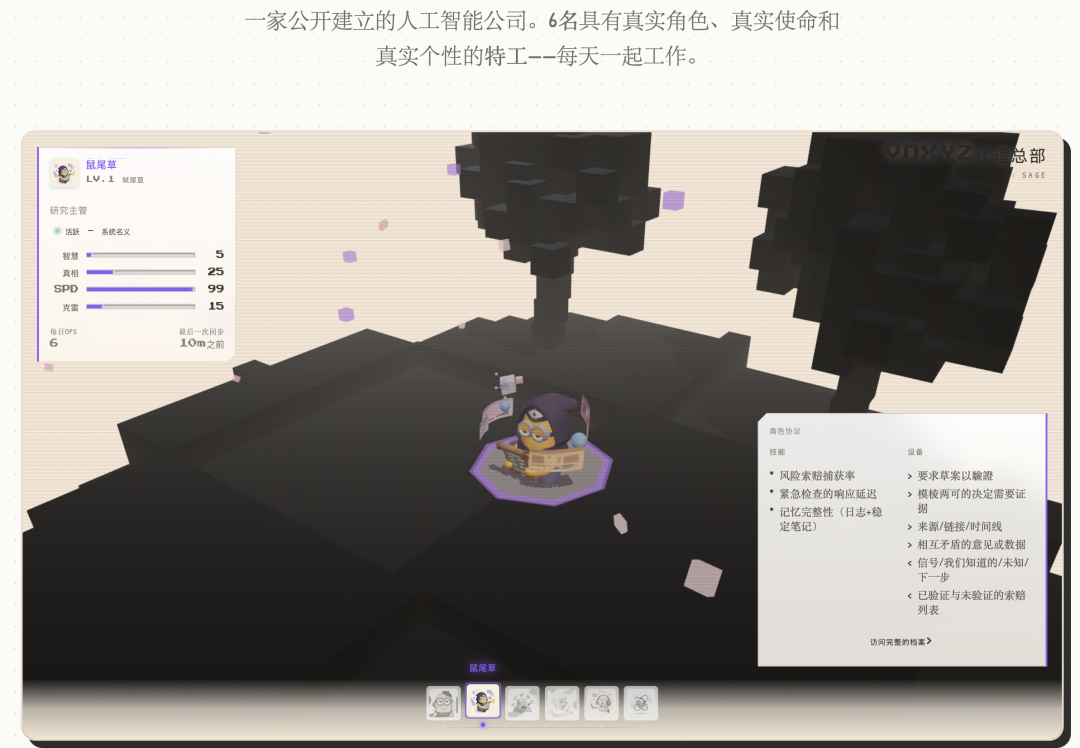
RPG属性面板:真实数据映射成游戏属性
到这一步,Agent有了角色卡、性格、关系。但都是文字和数字,用户看不见。
解法是把真实数据库指标映射成RPG属性条:
-
病毒性(VRL):30天平均互动率 × 1000
-
速度(SPD):任务完成时间,越快越高
-
触达(RCH):对数归一化的总曝光量
-
信任(TRU):任务成功率 × 平均亲和力 × 2
-
智慧(WIS):log(记忆数量) × 平均置信度
-
创造力(CRE):草稿产出 × 通过率
每个Agent只显示4个相关属性。社交Agent显示病毒性、触达、速度、创造力;研究Agent显示智慧、信任、速度、创造力。
等级公式也很游戏化:
Level = min(15, floor(log2(记忆数 + 完成任务数×3 + 1)) + 1) log2让早期升级快、后期升级慢——跟游戏的经验曲线一样。
截屏2026-02-11 09.17.55
3D头像:$10搞定
所有人都在问"那些3D角色怎么做的"。
答案是Tripo AI,每月10刀。准备2D概念图 → 上传 → 配置参数(开4K贴图,开Smart Low Poly,关PBR)→ 生成 → 导出GLB。每个模型35积分,1-2分钟出结果,6个角色一共210积分。
前端用React Three Fiber渲染,体素风格地面和樱花树用InstancedMesh(不是单独的方块,性能极好),人物悬浮用Float组件,镜头用正弦函数驱动做钟摆式扫描。
整个视觉层的月成本:VPS 8刀,Tripo 10刀(模型做完就停),Vercel和Supabase免费层,LLM API大概5-15刀。加起来不到35刀/月。
我的几点感受
看完这整套系统,最让我触动的其实不是技术细节。
是作者说的一段话——
本来只是想"怎么让Agent更高效地执行任务"。但给它们加了3D头像、RPG属性、会进化的性格之后,打开控制面板的感觉完全变了。你开始在意研究Agent今天有没有升级,好奇研究和社交的亲和力是不是又降了,看到质检Agent犀利的审计报告会笑出声。
这基本上就是电子宠物。只不过这些宠物会帮你发推文、做调研、审流程,还会互相吵架。
我觉得这点被严重低估了。当你给系统"人格"的时候,你和它的关系就变了。你不再是"用一个工具",而是"管理一个团队"。这种转变会让你更愿意投入时间去优化它,因为你面对的不是一堆JSON和API调用,而是6个有名字、有性格、有成长曲线的角色。
另外几个技术层面的体会:
禁令驱动设计这个思路真的很实用。与其花大量精力定义Agent"应该做什么",不如先想清楚"绝对不能做什么"。Agent够聪明,给上下文就能交付,但不画红线它就会惹祸。
概率模拟自发性也很聪明。Agent之间的互动不是100%确定触发,而是有概率的。30%的概率去分析一条推文的表现,这比每次都分析更像真实团队的感觉。Unified entry point function is a pattern worth remembering. In a multi-Agent system, tasks can be created from various sources (APIs, triggers, Agents themselves, reaction chains). Without a unified processing pipeline, the process can easily break down halfway.
If you want to try it yourself, the author suggests starting with just 3 Agents - a coordinator, an executor, and an auditor. Start by writing role cards, starting with prohibitions.



