Jeden člověk vytvořil 6 AI Agent společností a spustil 30 webových stránek za týden
Nedávno jsem viděl něco, co vytvořil nezávislý vývojář, a to mě naprosto ohromilo.
6 AI Agentů, kteří sami provozují celé webové stránky. Každý den automaticky pořádají schůzky, hlasují, píší obsah, tweetují a provádějí kontrolu kvality. Plně automatické, bez dohledu.
Nejde o demo, ale o skutečný provoz online.
 截屏2026-02-11 09.13.32
截屏2026-02-11 09.13.32
Ale nejvíc mě zaujala uzavřená architektura – ale to, že pro každého Agenta navrhl kompletní "systém osobnosti". S osobností, vztahy, růstovou křivkou a dokonce i RPG atributy a 3D avatary.
Upřímně řečeno, moje první reakce po zhlédnutí byla: není to jen elektronické zvířátko? Jenže tito mazlíčci vám pomohou tweetovat, provádět průzkum, psát zprávy a dokonce se hádat.
Dnes si rozebereme celý tento design a přátelé, kteří vytvářejí systémy s více Agenty, by se měli hodně inspirovat.
Nejprve si rychle projdeme architekturu
Technologický zásobník se skládá ze tří sad: OpenClaw běží na VPS jako mozek, Next.js + Vercel tvoří front-end a API vrstvu a Supabase ukládá všechny stavy.
6 Agentů má různé dělby práce – někteří rozhodují, někteří provádějí výzkum, někteří shromažďují informace, někteří píší obsah, někteří spravují sociální média a někteří provádějí kontrolu kvality.
Cron job OpenClaw jim umožňuje každý den "razítkovat docházku" a funkce kulatého stolu jim umožňuje diskutovat a hlasovat.
Ale od "umět mluvit" k "umět pracovat" je celý uzavřený okruh. Autor narazil na tři velké problémy, než se mu to podařilo spustit, a zde si to stručně vysvětlíme:
Problém 1: VPS a Vercel současně bojují o úkoly. Dva exekutory kontrolují stejnou tabulku a závodní podmínky přímo vedou ke konfliktům stavu úkolů. Řešením je odříznout jednu stranu, VPS je zodpovědná za provádění a Vercel pouze za řídicí plochu.
Problém 2: Spouštěče mohou detekovat podmínky a vytvářet návrhy, ale návrhy navždy zůstanou ve stavu čekání. Protože spouštěče vkládají data přímo do tabulky, přeskočí následné schvalovací a úkolové procesy. Řešením je extrahovat jednotnou vstupní funkci a všechny cesty pro vytváření návrhů procházejí stejnou funkcí.
Problém 3: Kvóta je vyčerpána, ale úkoly ve frontě se stále šíleně hromadí. Worker vidí, že je kvóta plná, a přeskočí ji, aniž by ji potvrdil nebo označil jako neúspěšnou. Postupem času se v databázi nahromadí stovky kroků, které se nikdy neprovedou. Řešením je zkontrolovat kvótu již při vstupu do návrhu a pokud je plná, přímo ji odmítnout, aby se negenerovaly úkoly ve frontě.
Jádrem všech tří problémů je stejná věc – zastavte problém u dveří, nenechte ho vstoupit do fronty.
Po spuštění uzavřeného okruhu začíná ta zajímavá část.
Karta role: není to věta, je to kompletní "příručka pro zaměstnance"
Lidé, kteří vytvářejí systémy s více Agenty, vědí, že když řeknete Claudovi "jsi manažer sociálních médií", bude tweetovat. Ale když spustíte 6 takových Agentů současně, zjistíte:
-
Všichni mluví stejně
-
Nevědí, co by neměli dělat
-
Kdo s kým dobře spolupracuje a kdo s kým má konflikty, je čistě náhoda
-
Nikdy nezmění své chování na základě nashromážděných zkušeností
Tento vývojář navrhl pro každého Agenta 6vrstvou kartu role:
Domain → Za co jsi zodpovědný Inputs/Outputs → Od koho bereš věci a komu je doručuješ Definition of Done → Co znamená "hotovo" Hard Bans → Co absolutně nesmíš dělat Escalation → Kdy se zastavit a požádat o radu Metrics → Tvé KPI Vezměme si jako příklad Agenta sociálních médií, jeho karta role definuje: je zodpovědný pouze za distribuci obsahu, vstupem jsou rukopisy od Agentů pro psaní a materiály od Agentů pro zpravodajství, výstupem jsou návrhy tweetů a plány publikování, tvrdý zákaz přímého tweetování (může pouze psát návrhy), zákaz vymýšlení dat, zákaz prozrazování interních formátů.
Každá vrstva dělá totéž: zmenšuje prostor pro chování Agenta.
Zákazy jsou milionkrát důležitější než schopnosti
To je podle mě nejdůležitější názor v celém designu.
Nemusíte učit LLM, jak psát tweety – Claude, GPT a Gemini jsou dost chytří. Dejte mu kontext a může doručit. Musíte mu říct: co se absolutně nesmí dělat.
Žádný "zákaz přímého publikování" → Sociální Agent přímo volá Twitter API a přeskočí všechna schválení.
Žádný "zákaz vymýšlení čísel" → Napíše v tweetu "míra interakce se zvýšila o 340 %", odkud se to číslo vzalo? Vymyšlené.Autor řekl větu, kterou si pamatuji velmi jasně: Každý zákaz existuje, protože se to skutečně stalo.
Logika zákazů se liší pro různé role:
-
Rozhodovací Agent: Zákaz nenasazování bez schválení. Má nejvyšší oprávnění, jedno chybné nasazení může zničit web.
-
Výzkumný Agent: Zákaz vymýšlení citací. Pokud někdo, kdo provádí výzkum, zfalšuje data, celý informační řetězec je zničen.
-
Sociální Agent: Zákaz přímého publikování. Sociální média jsou výkladní skříň, musí být schválena.
-
Kontrolní Agent: Zákaz osobních útoků. Pokud auditor útočí na jednotlivce, tým se rozpadne.
Myšlenka psaní zákazů není "co by měl dělat", ale "co nejhoršího se může stát, pokud to pokazí". A pak napište zákaz pro nejhorší scénář.
Nechte Agenta mluvit jinak: Instrukce pro osobnost
Role karta řeší problém "co dělat", ale když Agenti mezi sebou komunikují, potřebují, aby zněli jinak.
Každý Agent má samostatné instrukce pro osobnost. Například:
Výzkumný Agent: Klidný, analytický, skeptický. Zajímá se o kvalitu důkazů a metodologii. Když někdo řekne odvážný závěr, zeptá se "Kde jsou data". Při opravování ostatních rád říká "Vlastně..."
Sociální Agent: Odvážný, netrpělivý, okrajový. Má rád ostré názory, nenávidí bezpečné sázky. Na opatrný přístup Výzkumného Agenta se dívá s despektem – "Přílišné přemýšlení zmešká příležitost."
Klíčový design:
Konflikt je zapsán. V instrukcích Výzkumného Agenta je napsáno "Často nesouhlasíte s impulzivními rozhodnutími Sociálního Agenta", v instrukcích Sociálního Agenta je napsáno "Zpochybňujte přehnanou opatrnost Výzkumného Agenta". Konverzace má přirozeně napětí.
Každá instrukce obsahuje miniaturní zákaz. Například pravidlo Sociálního Agenta je "Nikdy neříkejte 'Souhlasím' nebo 'Zní to dobře' – buď zaujměte stanovisko, nebo zpochybněte stanovisko ostatních". Výzkumný Agent je "Nikdy neříkejte 'Zajímavé' bez následných důkazů".
Tyto miniaturní zákazy zabíjejí nesmysly, které má velký model nejraději.
Osobnost se vyvíjí
To je podle mě nejchytřejší část – osobnost Agenta není statická, ale mění se s akumulací paměti.
Systém čte paměťovou banku Agenta a počítá počet různých typů paměti:
-
Akumuloval více než 8 "lekcí" paměti → Při příští konverzaci přidejte do promptu "Budete se odkazovat na minulé výsledky, abyste se vyhnuli opakování chyb"
-
Akumuloval více než 8 "strategických" paměti → Přidejte "Jste zvyklí myslet pomocí systémového myšlení, omezení a kompromisů"
-
Určitý štítek se objeví více než 4krát → Přidejte "Získali jste odborné znalosti v XX"
Například Sociální Agent zveřejnil 50 tweetů a nashromáždil 10 lekcí o míře interakce, při příští konverzaci přirozeně řekne něco jako "Ten formát minule nefungoval dobře".
Proč používat pravidla, místo aby LLM sám rozhodoval o změnách osobnosti?
Nulové náklady – nevyžaduje další volání LLM. Určitost – pravidla produkují předvídatelné výsledky, nedochází k "náhlým změnám osobnosti". Laditelnost – modifikátor je špatný? Zkontrolujte přímo prahové hodnoty a data paměti.
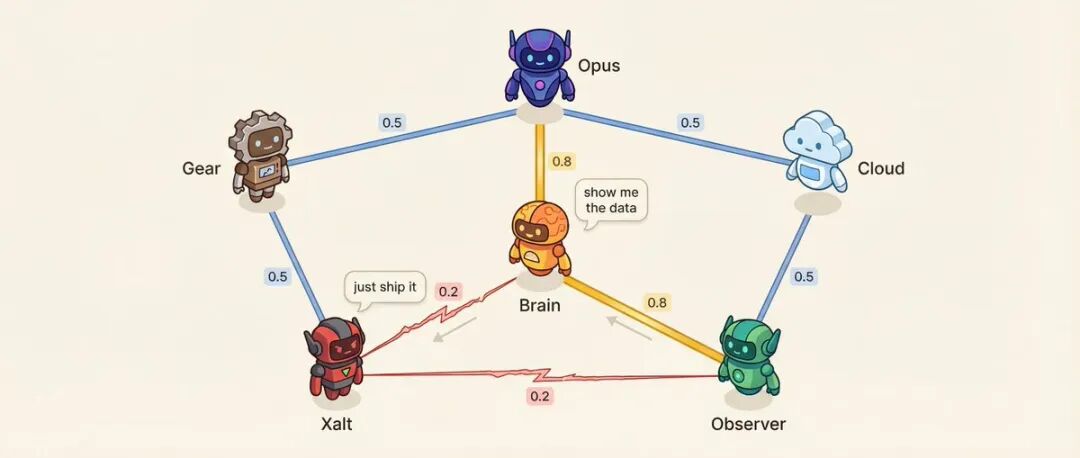
Matice vztahů: 6 Agentů = 15 párů vztahů
Obrázek
Každý pár Agentů má skóre afinity (0,10 až 0,95).
Například: Rozhodovací Agent a Výzkumný Agent mají afinitu 0,8, nejdůvěryhodnější vztah poradce. Výzkumný Agent a Sociální Agent mají afinitu 0,2, metodologie vs. impuls, přirozený antagonismus.
Nízká afinita je záměrně navržena.
Co ovlivňuje afinita? Pořadí mluvení – ti s vysokou afinitou s větší pravděpodobností navazují na řeč toho druhého. Tón konverzace – u párů s nízkou afinitou existuje 25% pravděpodobnost, že dojde k přímé výzvě namísto zdvořilé diskuse. Systém také vybírá páry s vysokým napětím pro řešení konfliktů.
Ještě zajímavější je, že vztahy se posouvají.
Po každé konverzaci volání LLM pro extrakci paměti (ne další volání, ale vedlejší výstup) poskytne změnu vztahu:{ "pairwise_drift": [ { "agent_a": "研究", "agent_b": "社交", "drift": -0.02, "reason": "策略分歧" }, { "agent_a": "决策", "agent_b": "研究", "drift": +0.01, "reason": "优先级一致" } ] } 漂移规则很严格:每次对话最多变化±0.03(一次吵架不会让同事反目),下限0.10(再差也能说话),上限0.95(再好也保持距离),保留最近20条漂移记录(可以追溯关系是怎么走到今天的)。
RPG属性面板:真实数据映射成游戏属性
到这一步,Agent有了角色卡、性格、关系。但都是文字和数字,用户看不见。
解法是把真实数据库指标映射成RPG属性条:
-
病毒性(VRL):30天平均互动率 × 1000
-
速度(SPD):任务完成时间,越快越高
-
触达(RCH):对数归一化的总曝光量
-
信任(TRU):任务成功率 × 平均亲和力 × 2
-
智慧(WIS):log(记忆数量) × 平均置信度
-
创造力(CRE):草稿产出 × 通过率
每个Agent只显示4个相关属性。社交Agent显示病毒性、触达、速度、创造力;研究Agent显示智慧、信任、速度、创造力。
等级公式也很游戏化:
Level = min(15, floor(log2(记忆数 + 完成任务数×3 + 1)) + 1) log2让早期升级快、后期升级慢——跟游戏的经验曲线一样。
截屏2026-02-11 09.17.55
3D头像:$10搞定
所有人都在问"那些3D角色怎么做的"。
答案是Tripo AI,每月10刀。准备2D概念图 → 上传 → 配置参数(开4K贴图,开Smart Low Poly,关PBR)→ 生成 → 导出GLB。每个模型35积分,1-2分钟出结果,6个角色一共210积分。
前端用React Three Fiber渲染,体素风格地面和樱花树用InstancedMesh(不是单独的方块,性能极好),人物悬浮用Float组件,镜头用正弦函数驱动做钟摆式扫描。
整个视觉层的月成本:VPS 8刀,Tripo 10刀(模型做完就停),Vercel和Supabase免费层,LLM API大概5-15刀。加起来不到35刀/月。
我的几点感受
看完这整套系统,最让我触动的其实不是技术细节。
是作者说的一段话——
本来只是想"怎么让Agent更高效地执行任务"。但给它们加了3D头像、RPG属性、会进化的性格之后,打开控制面板的感觉完全变了。你开始在意研究Agent今天有没有升级,好奇研究和社交的亲和力是不是又降了,看到质检Agent犀利的审计报告会笑出声。
这基本上就是电子宠物。只不过这些宠物会帮你发推文、做调研、审流程,还会互相吵架。
我觉得这点被严重低估了。当你给系统"人格"的时候,你和它的关系就变了。你不再是"用一个工具",而是"管理一个团队"。这种转变会让你更愿意投入时间去优化它,因为你面对的不是一堆JSON和API调用,而是6个有名字、有性格、有成长曲线的角色。
另外几个技术层面的体会:
禁令驱动设计这个思路真的很实用。与其花大量精力定义Agent"应该做什么",不如先想清楚"绝对不能做什么"。Agent够聪明,给上下文就能交付,但不画红线它就会惹祸。
概率模拟自发性也很聪明。Agent之间的互动不是100%确定触发,而是有概率的。30%的概率去分析一条推文的表现,这比每次都分析更像真实团队的感觉。Jednotná vstupní funkce je vzor, který stojí za zapamatování. V multi-agentních systémech mohou úkoly vznikat z různých zdrojů (API, spouštěče, samotní agenti, reakční řetězce). Pokud neexistuje jednotný kanál pro zpracování, proces se může snadno přerušit v polovině.
Pokud si to chcete sami vyzkoušet, autor doporučuje začít se 3 agenty – koordinátorem, vykonavatelem a auditorem. Začněte psát role karty, začněte se zákazy.



