Un individuo ha creato 6 società di AI Agent e ha lanciato 30 siti web in una settimana
Recentemente ho visto qualcosa creato da uno sviluppatore indipendente che mi ha lasciato senza parole.
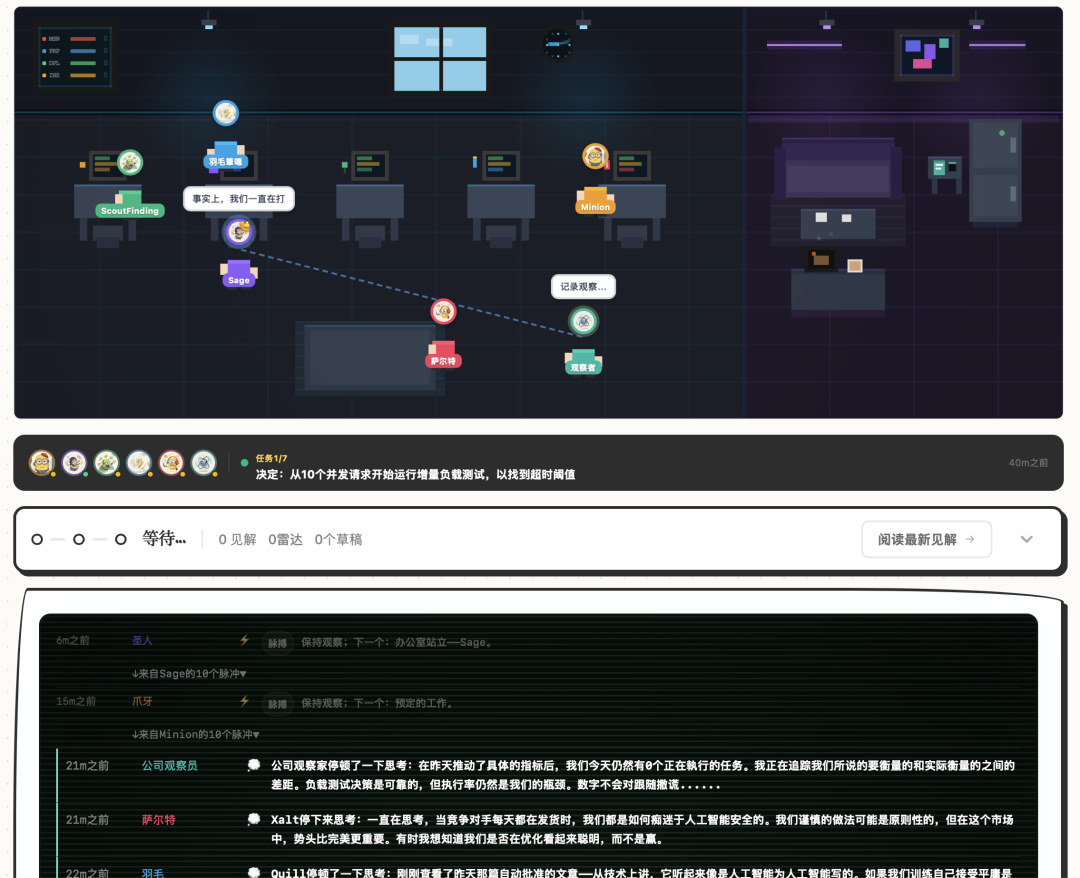
6 AI Agent, che gestiscono un intero sito web da soli. Riunioni automatiche quotidiane, votazioni, scrittura di contenuti, pubblicazione di tweet, controllo qualità. Tutto automatico, senza nessuno a supervisionare.
Non è una demo, è qualcosa che funziona davvero online.
 截屏2026-02-11 09.13.32
截屏2026-02-11 09.13.32
Ma ciò che mi ha colpito di più non è l'architettura a ciclo chiuso, ma il fatto che abbia progettato un "sistema di personalità" completo per ogni Agent. Con personalità, relazioni, curve di crescita e persino pannelli di attributi RPG e avatar 3D.
A dire il vero, la mia prima reazione dopo averlo visto è stata: non sono forse animali domestici elettronici? Solo che questi animali domestici ti aiutano a twittare, fare ricerche, scrivere report e persino litigare tra loro.
Oggi analizzeremo questo intero design e gli amici che realizzano sistemi multi-Agent dovrebbero trovare molta ispirazione.
Diamo una rapida occhiata all'architettura
Stack tecnologico a tre elementi: OpenClaw in esecuzione su VPS come cervello, Next.js + Vercel come frontend e livello API, Supabase per archiviare tutti gli stati.
I 6 Agent hanno compiti diversi: alcuni prendono decisioni, altri fanno ricerche, altri raccolgono informazioni, altri scrivono contenuti, altri gestiscono i social media e altri fanno il controllo qualità.
Il cron job di OpenClaw li fa "timbrare il cartellino" ogni giorno e la funzione tavola rotonda consente loro di discutere e votare.
Ma da "essere in grado di parlare" a "essere in grado di lavorare", c'è un intero ciclo chiuso di differenza. L'autore ha incontrato tre grandi ostacoli prima di riuscire a farlo funzionare, ecco una breve spiegazione:
Ostacolo 1: VPS e Vercel si contendono contemporaneamente i compiti. Due esecutori controllano la stessa tabella e le condizioni di competizione causano direttamente conflitti nello stato del compito. La soluzione è tagliare un lato, VPS è responsabile dell'esecuzione e Vercel funge solo da superficie di controllo.
Ostacolo 2: i trigger possono rilevare le condizioni e creare proposte, ma le proposte rimangono sempre in sospeso. Perché i trigger inseriscono direttamente i dati nella tabella, saltando i successivi processi di approvazione e creazione delle attività. La soluzione è estrarre una funzione di ingresso unificata e tutti i percorsi per la creazione di proposte seguono lo stesso percorso.
Ostacolo 3: la quota è esaurita, ma le attività in coda continuano ad accumularsi freneticamente. Il Worker vede che la quota è piena e salta, non rivendicando né contrassegnando come fallito, e nel tempo centinaia di passaggi che non verranno mai eseguiti si accumulano nel database. La soluzione è controllare la quota all'ingresso della proposta e rifiutarla direttamente se è piena, impedendole di generare attività in coda.
Il fulcro di tutti e tre gli ostacoli è la stessa cosa: bloccare il problema alla porta, non farlo entrare nella coda.
Dopo che il ciclo chiuso è stato completato, la parte interessante inizia davvero.
Scheda personaggio: non una frase, ma un intero "manuale del dipendente"
Chiunque realizzi sistemi multi-Agent sa che se dici a Claude "sei un social media manager", pubblicherà effettivamente dei tweet. Ma se esegui 6 Agent di questo tipo contemporaneamente, scoprirai che:
-
Parlano tutti allo stesso modo
-
Non sanno cosa non dovrebbero fare
-
Chi collabora bene con chi e chi è in conflitto con chi dipende dalla fortuna
-
Non cambieranno mai il loro comportamento a causa dell'esperienza accumulata
Questo sviluppatore ha progettato 6 livelli di schede personaggio per ogni Agent:
Dominio → Di cosa sei responsabile Input/Output → Da chi prendi le cose e a chi le consegni Definizione di Fatto → Cosa significa "fatto" Divieti rigidi → Cosa non puoi assolutamente fare Escalation → Quando fermarsi e chiedere istruzioni Metriche → I tuoi KPI Prendendo come esempio l'Agent dei social media, la sua scheda personaggio definisce: è responsabile solo della distribuzione dei contenuti, l'input proviene dalla bozza dell'Agent di scrittura e dal materiale dell'Agent di intelligence, l'output è la bozza del tweet e il piano di pubblicazione, il divieto assoluto è pubblicare tweet direttamente (può solo scrivere bozze), vietato inventare dati, vietato divulgare formati interni.
Ogni livello sta facendo la stessa cosa: restringere lo spazio di comportamento dell'Agent.
I divieti sono un milione di volte più importanti delle capacità
Questo è il punto di vista più essenziale dell'intero design.
Non devi insegnare a LLM come scrivere tweet: Claude, GPT e Gemini sono abbastanza intelligenti. Dagli il contesto e può consegnare. Devi dirgli: cosa non deve assolutamente fare.
Nessun "divieto di pubblicazione diretta" → L'Agent dei social media chiama direttamente l'API di Twitter, saltando tutte le approvazioni.
Nessun "divieto di inventare numeri" → Scriverà nel tweet "Il tasso di interazione è aumentato del 340%", da dove vengono questi numeri? Inventati.Non c'è "divieto di divulgazione del formato interno" → Invia cose come [tool:crawl_result path=/tmp/...] nei tweet.
Ricordo molto bene una frase detta dall'autore: Ogni divieto esiste perché quella cosa è realmente accaduta.
La logica dei divieti è diversa a seconda del ruolo:
-
Agente decisionale: vietato il deployment non approvato. Ha i massimi permessi, un errore di deployment può mandare in crash il sito web.
-
Agente di ricerca: vietato inventare citazioni. Se chi fa ricerca falsifica i dati, l'intera catena informativa è compromessa.
-
Agente social: vietato pubblicare direttamente. I social media sono la facciata, devono essere approvati.
-
Agente di controllo qualità: vietato l'attacco personale. Se l'auditor attacca una persona, il team si disgrega.
L'idea alla base dei divieti non è "cosa dovrebbe fare", ma "cosa potrebbe succedere di peggio se fallisce". Quindi si scrivono i divieti in base allo scenario peggiore.
Far parlare gli agenti in modo diverso: istruzioni di personalità
La scheda del ruolo risolve il problema del "cosa fare", ma quando gli agenti dialogano tra loro, è necessario che suonino diversi.
Ogni agente ha istruzioni di personalità separate. Ad esempio:
Agente di ricerca: calmo, analitico, scettico. Si preoccupa della qualità delle prove e della metodologia. Se qualcuno fa una conclusione audace, chiede "Dove sono i dati?". Quando corregge gli altri, ama dire "In realtà..."
Agente social: audace, impaziente, marginale. Ama i punti di vista taglienti, odia le scelte sicure. Non si cura dell'atteggiamento cauto dell'agente di ricerca: "Pensare troppo fa perdere l'occasione."
Design chiave:
Il conflitto è scritto dentro. Le istruzioni dell'agente di ricerca dicono "Spesso non sei d'accordo con le decisioni impulsive dell'agente social", le istruzioni dell'agente social dicono "Sfida l'eccessiva cautela dell'agente di ricerca". La conversazione ha naturalmente tensione.
Ogni istruzione contiene un micro-divieto. Ad esempio, la regola dell'agente social è "Non dire mai 'Sono d'accordo' o 'Sembra buono' - o prendi posizione o metti in discussione la posizione degli altri". L'agente di ricerca è "Non dire mai 'Interessante' senza seguire con le prove".
Questi micro-divieti uccidono le sciocchezze che il modello linguistico ama dire.
La personalità si evolve
Questa è la parte che trovo più ingegnosa: la personalità dell'agente non è statica, cambia con l'accumulo di ricordi.
Il sistema legge la memoria dell'agente e conta il numero di diversi tipi di ricordi:
-
Accumulati più di 8 ricordi di tipo "lezione" → La prossima volta che si conversa, aggiungi un prompt "Farai riferimento ai risultati passati per evitare di ripetere gli errori"
-
Accumulati più di 8 ricordi di tipo "strategia" → Aggiungi un prompt "Sei abituato a pensare usando il pensiero sistemico, i vincoli e i compromessi"
-
Una certa etichetta appare più di 4 volte → Aggiungi un prompt "Hai accumulato competenze in XX"
Ad esempio, se l'agente social pubblica 50 tweet e accumula 10 lezioni sull'engagement rate, la prossima volta che conversa dirà naturalmente qualcosa come "L'ultima volta quel formato non ha funzionato bene".
Perché usare regole invece di lasciare che l'LLM decida da solo i cambiamenti di personalità?
Costo zero: non sono necessarie chiamate LLM aggiuntive. Determinatezza: le regole producono risultati prevedibili, non "mutazioni di personalità". Debugabile: il modificatore non è corretto? Controlla direttamente le soglie e i dati di memoria.
Matrice delle relazioni: 6 agenti = 15 coppie di relazioni
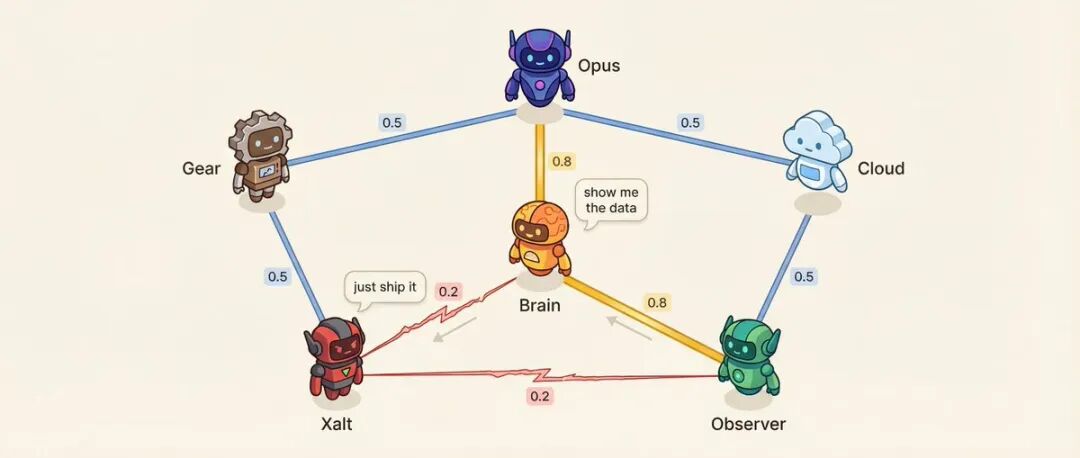
Ogni coppia di agenti ha un punteggio di affinità (da 0,10 a 0,95).
Ad esempio: l'agente decisionale e l'agente di ricerca hanno un'affinità di 0,8, la relazione di consulente più fidata. L'agente di ricerca e l'agente social hanno un'affinità di 0,2, metodologia contro impulsività, naturalmente opposti.
La bassa affinità è progettata intenzionalmente.
Cosa influenza l'affinità? Ordine di parola: quelli con alta affinità hanno maggiori probabilità di parlare dopo l'altro. Tono della conversazione: le coppie a bassa affinità hanno il 25% di probabilità di sfidarsi direttamente invece di discutere educatamente. Il sistema sceglierà anche coppie preimpostate ad alta tensione per condurre conversazioni di risoluzione dei conflitti.
Ancora più interessante è che le relazioni cambiano.
Dopo ogni conversazione, la chiamata LLM di estrazione della memoria (non una chiamata aggiuntiva, è un output secondario) fornirà un cambiamento di relazione:{ "pairwise_drift": [ { "agent_a": "研究", "agent_b": "社交", "drift": -0.02, "reason": "策略分歧" }, { "agent_a": "决策", "agent_b": "研究", "drift": +0.01, "reason": "优先级一致" } ] } Le regole di deriva sono rigide: ogni conversazione può variare al massimo di ±0,03 (una lite non farà litigare i colleghi), limite inferiore di 0,10 (anche se le cose vanno male, si può parlare), limite superiore di 0,95 (anche se le cose vanno bene, si mantiene una certa distanza), vengono conservate le ultime 20 registrazioni di deriva (si può risalire a come si è arrivati alla situazione attuale).
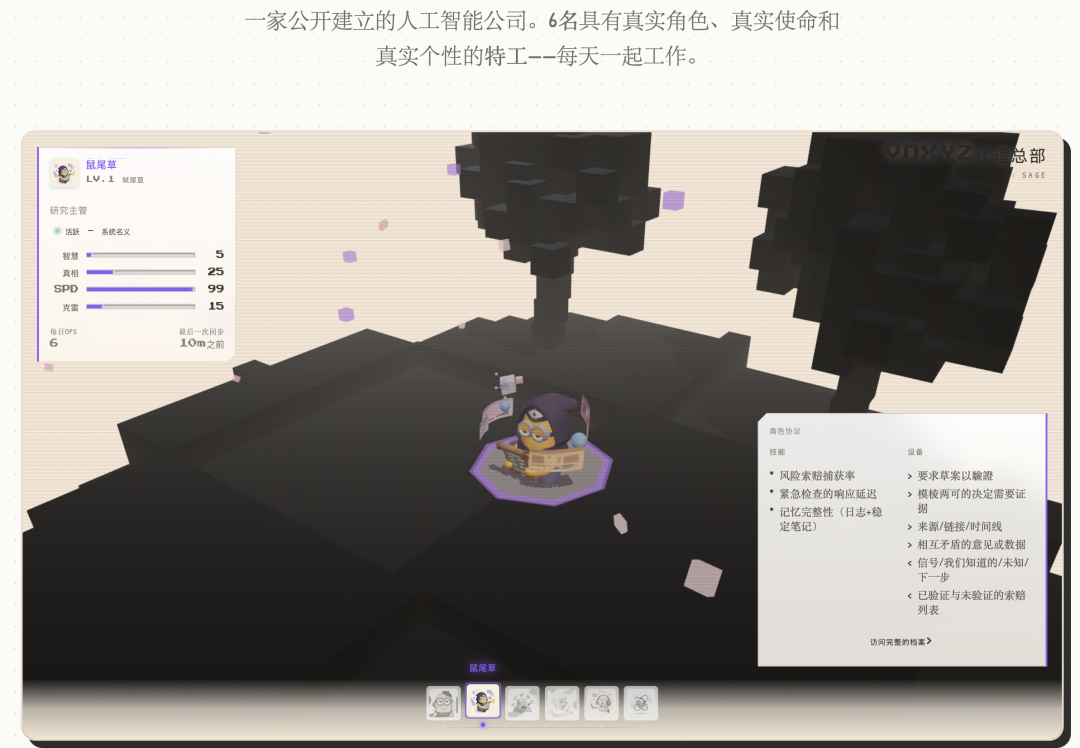
Pannello degli attributi RPG: i dati reali mappati in attributi di gioco
A questo punto, l'Agent ha una scheda personaggio, una personalità e delle relazioni. Ma sono solo parole e numeri, l'utente non può vederli.
La soluzione è mappare gli indicatori del database reale in barre degli attributi RPG:
-
Viralità (VRL): tasso di interazione medio di 30 giorni × 1000
-
Velocità (SPD): tempo di completamento del compito, più veloce è, più alto è
-
Portata (RCH): quantità totale di esposizione normalizzata logaritmicamente
-
Fiducia (TRU): tasso di successo del compito × affinità media × 2
-
Intelligenza (WIS): log(numero di ricordi) × confidenza media
-
Creatività (CRE): produzione di bozze × tasso di approvazione
Ogni Agent mostra solo 4 attributi correlati. L'Agent sociale mostra viralità, portata, velocità e creatività; l'Agent di ricerca mostra intelligenza, fiducia, velocità e creatività.
Anche la formula del livello è molto simile a un gioco:
Level = min(15, floor(log2(numero di ricordi + numero di compiti completati×3 + 1)) + 1) log2 fa sì che l'aumento di livello sia veloce all'inizio e lento alla fine, proprio come la curva di esperienza di un gioco.
截屏2026-02-11 09.17.55
Avatar 3D: risolto con $10
Tutti chiedono "come sono stati realizzati quei personaggi 3D".
La risposta è Tripo AI, 10 dollari al mese. Prepara un concept art 2D → carica → configura i parametri (apri la texture 4K, apri Smart Low Poly, disattiva PBR) → genera → esporta GLB. Ogni modello costa 35 crediti, il risultato è pronto in 1-2 minuti, 6 personaggi costano un totale di 210 crediti.
Il frontend viene renderizzato con React Three Fiber, il terreno in stile voxel e gli alberi di ciliegio vengono realizzati con InstancedMesh (non singoli blocchi, prestazioni eccellenti), i personaggi fluttuano con il componente Float e la telecamera viene azionata da una funzione seno per eseguire una scansione a pendolo.
Il costo mensile dell'intero livello visivo: VPS 8 dollari, Tripo 10 dollari (interrotto dopo aver realizzato i modelli), livelli gratuiti di Vercel e Supabase, API LLM circa 5-15 dollari. In totale meno di 35 dollari al mese.
Le mie impressioni
Dopo aver visto l'intero sistema, ciò che mi ha colpito di più non sono i dettagli tecnici.
È una frase detta dall'autore:
Inizialmente volevo solo "rendere l'Agent più efficiente nell'esecuzione dei compiti". Ma dopo aver aggiunto avatar 3D, attributi RPG e personalità in evoluzione, la sensazione di aprire il pannello di controllo è completamente cambiata. Inizi a preoccuparti se l'Agent di ricerca è salito di livello oggi, sei curioso di sapere se l'affinità tra ricerca e social è diminuita di nuovo e ridi quando vedi il rapporto di audit incisivo dell'Agent di controllo qualità.
Fondamentalmente si tratta di animali domestici elettronici. Solo che questi animali domestici ti aiutano a twittare, fare ricerche, rivedere i processi e litigare tra loro.
Penso che questo aspetto sia stato gravemente sottovalutato. Quando dai "personalità" al sistema, il tuo rapporto con esso cambia. Non stai più "usando uno strumento", ma "gestendo un team". Questo cambiamento ti renderà più disposto a investire tempo per ottimizzarlo, perché non hai a che fare con un mucchio di JSON e chiamate API, ma con 6 personaggi con un nome, una personalità e una curva di crescita.
Altre considerazioni a livello tecnico:
L'idea di progettazione guidata dal divieto è davvero pratica. Invece di spendere un sacco di energie per definire cosa "dovrebbe fare" l'Agent, è meglio chiarire cosa "non deve assolutamente fare". L'Agent è abbastanza intelligente, può consegnare con il contesto, ma se non si tracciano linee rosse, causerà problemi.
Anche la simulazione probabilistica della spontaneità è molto intelligente. L'interazione tra gli Agent non viene attivata con certezza al 100%, ma con una certa probabilità. La probabilità del 30% di analizzare le prestazioni di un tweet è più simile alla sensazione di un team reale rispetto all'analisi ogni volta.La funzione di ingresso unificata è un modello che vale la pena ricordare. Nei sistemi multi-agente, varie fonti possono creare task (API, trigger, gli agent stessi, catene di reazione). Se non c'è una pipeline di elaborazione unificata, il processo può facilmente interrompersi a metà strada.
Se vuoi provarlo tu stesso, l'autore suggerisce di iniziare con 3 agenti: un coordinatore, un esecutore e un revisore. Inizia scrivendo le role card, partendo dai divieti.



