一人で6つのAIエージェント企業を立ち上げ、1週間で30のウェブサイトを公開
最近、ある独立系開発者が作ったものを見て、言葉を失いました。
6つのAIエージェントが、ウェブサイト全体を自分で運営しています。毎日、自動的に会議を開き、投票し、コンテンツを書き、ツイートし、品質検査を行います。すべて自動で、誰も監視していません。
デモではなく、実際にオンラインで稼働しています。
 截屏2026-02-11 09.13.32
截屏2026-02-11 09.13.32
しかし、私が最も夢中になったのは、クローズドループアーキテクチャではなく、各エージェントに完全な「人格システム」を設計したことです。性格、関係性、成長曲線があり、さらにはRPG属性パネルと3Dアバターまであります。
正直に言って、それを見た私の最初の反応は、「これは電子ペットではないか?」ということでした。ただし、これらのペットは、ツイートを投稿したり、調査を行ったり、レポートを作成したり、さらには互いに喧嘩したりするのに役立ちます。
今日は、この設計全体を分解して話し合います。マルチエージェントシステムを構築している友人にとっては、多くのヒントになるはずです。
まず、アーキテクチャを簡単に見ていきましょう
技術スタックの3つの要素:OpenClawはVPS上で脳として動作し、Next.js + VercelはフロントエンドとAPI層として機能し、Supabaseはすべての状態を保存します。
6つのエージェントはそれぞれ役割分担があります。意思決定を行うエージェント、調査を行うエージェント、情報収集を行うエージェント、コンテンツを作成するエージェント、ソーシャルメディアを管理するエージェント、品質検査を行うエージェントがいます。
OpenClawのcronジョブにより、毎日「出勤」し、円卓機能により、議論して投票します。
しかし、「話せる」から「仕事ができる」ようになるまでには、完全なクローズドループが必要です。作者は3つの大きな落とし穴を踏んでようやく稼働させることができました。ここでは簡単に説明します。
落とし穴1:VPSとVercelが同時にタスクを奪い合う。 2つの実行者が同じテーブルを調べ、競合状態が発生し、タスクの状態が衝突します。解決策は、片方を切り捨てることです。VPSが実行を担当し、Vercelは制御面のみを担当します。
落とし穴2:トリガーは条件を検出し、提案を作成できますが、提案は常に保留中のままです。 トリガーがテーブルに直接データを挿入し、その後の承認とタスク作成プロセスをスキップするためです。解決策は、統一されたエントリポイント関数を抽出し、すべての提案作成パスが同じパスを通過するようにすることです。
落とし穴3:割り当てが使い果たされたにもかかわらず、キューに入れられたタスクが大量に蓄積されています。 Workerは割り当てがいっぱいになるとスキップし、要求も失敗のマークも付けないため、データベースには実行されないステップが数百個も蓄積されます。解決策は、提案のエントリポイントで割り当てを確認し、いっぱいになったら直接拒否し、キューに入れられたタスクを生成させないことです。
3つの落とし穴の核心は同じことです。入り口で阻止し、問題をキューに入れないようにすることです。
クローズドループが稼働した後、面白い部分が本当に始まります。
ロールカード:一言ではなく、完全な「従業員ハンドブック」
マルチエージェントシステムを構築している人は誰でも知っています。Claudeに「あなたはソーシャルメディアマネージャーです」と言うと、確かにツイートを投稿します。しかし、そのようなエージェントを6つ同時に実行すると、次のことがわかります。
-
彼らの話し方はすべて同じ
-
自分が何をすべきでないかを知らない
-
誰と誰が協力するのが得意で、誰と誰が衝突するかは、運次第
-
蓄積された経験によって行動が変わることはない
この開発者は、各エージェントに6層のロールカードを設計しました。
Domain → あなたは何を担当しますか Inputs/Outputs → 誰から何を受け取り、誰に何を渡しますか Definition of Done → 「完了」とはどういう意味ですか Hard Bans → 絶対に何をしてはいけませんか Escalation → いつ停止して指示を仰ぎますか Metrics → あなたのKPI ソーシャルメディアエージェントを例にとると、そのロールカードは、コンテンツの配信のみを担当し、入力はライティングエージェントの原稿と情報エージェントの素材から、出力はツイートの草案と公開計画であると定義しています。直接ツイートすること(草案のみを書く)、データを捏造すること、内部形式を漏洩することは厳禁です。
すべての層が同じことを行っています。エージェントの行動範囲を狭めることです。
禁止事項は能力よりも1万倍重要です
これは、この設計全体で私が最も素晴らしいと思う視点です。
LLMにツイートの書き方を教える必要はありません。Claude、GPT、Geminiは十分に賢いです。コンテキストを与えれば、配信できます。必要なのは、何をしてはいけないかを伝えることです。
「直接公開を禁止」がない場合 → ソーシャルエージェントはTwitter APIを直接呼び出し、すべての承認をスキップします。
「数字を捏造することを禁止」がない場合 → ツイートで「インタラクション率が340%向上」と書きます。この数字はどこから来たのでしょうか?捏造されたものです。「内部フォーマットの漏洩禁止」は存在しない → [tool:crawl_result path=/tmp/...] のようなものをツイートに投稿していた。
作者が言った言葉で私がはっきりと覚えているのは、**「すべての禁止事項の存在は、実際にその出来事が起こったからだ」**ということです。
異なる役割の禁止事項のロジックも異なります。
-
意思決定Agent:承認されていないデプロイメントの禁止。権限が最も高く、一度の間違ったデプロイメントでウェブサイトを崩壊させる可能性があります。
-
研究Agent:捏造された引用の禁止。研究者がデータを偽造すると、情報チェーン全体が無駄になります。
-
ソーシャルAgent:直接公開の禁止。ソーシャルメディアは顔であり、審査が必要です。
-
品質管理Agent:人身攻撃の禁止。監査人が個人を攻撃すると、チームは解散します。
禁止事項を書く際の考え方は、「何をすべきか」ではなく、「もし失敗した場合、最悪の事態は何が起こるか」です。そして、最悪の事態に対して禁止事項を書きます。
Agentに異なる話し方をさせる:性格指示
役割カードは「何をするか」という問題を解決しましたが、Agent同士が会話するときには、それぞれが異なるように聞こえる必要があります。
各Agentには個別の性格指示があります。例えば:
研究Agent:冷静、分析的、懐疑的。証拠の質と方法論に関心があります。誰かが大胆な結論を述べると、「データはどこにあるのか」と尋ねます。他人を訂正するときは「実は…」と言うのが好きです。
ソーシャルAgent:大胆、せっかち、エッジが効いている。鋭い意見が好きで、安全策を嫌います。研究Agentの慎重な態度を気にしません——「考えすぎると機会を逃す」。
重要な設計:
対立は書き込まれています。 研究Agentの指示には「あなたはソーシャルAgentの衝動的な意思決定にしばしば同意しません」と書かれており、ソーシャルAgentの指示には「研究Agentの過度の慎重さに挑戦する」と書かれています。会話は自然に緊張感を持つようになります。
すべての指示にはミニ禁止事項が含まれています。 例えば、ソーシャルAgentのルールは「決して「賛成」または「良さそう」と言わない——立場を表明するか、他人の立場に疑問を呈する」です。研究Agentは「証拠を提示せずに「面白い」と言うな」です。
これらのミニ禁止事項は、大規模言語モデルが最も好む無駄話を排除します。
性格は進化する
これは私が最も巧妙だと思う部分です——Agentの性格は静的ではなく、記憶の蓄積とともに変化します。
システムはAgentの記憶庫を読み取り、異なる種類の記憶の数を統計します。
-
8つ以上の「教訓」タイプの記憶を蓄積した場合 → 次の会話時にプロンプトに「過去の結果を参考に、同じ過ちを繰り返さないようにする」という指示を追加します。
-
8つ以上の「戦略」タイプの記憶を蓄積した場合 → 「システム思考、制約、トレードオフを使って考えることに慣れている」という指示を追加します。
-
特定のタグが4回以上出現した場合 → 「あなたはXXの分野で専門知識を蓄積している」という指示を追加します。
例えば、ソーシャルAgentが50件のツイートを投稿し、エンゲージメント率に関する10件の教訓を蓄積した場合、次の会話では自然に「前回のようなフォーマットは効果がなかった」と言うようになります。
なぜルールを使うのか、LLMに性格の変化を自分で決定させないのか?
ゼロコスト——追加のLLM呼び出しは不要です。確定性——ルールは予測可能な結果を生み出し、「性格の突然変異」は起こりません。デバッグ可能——修飾語が正しくない?閾値と記憶データを直接確認します。
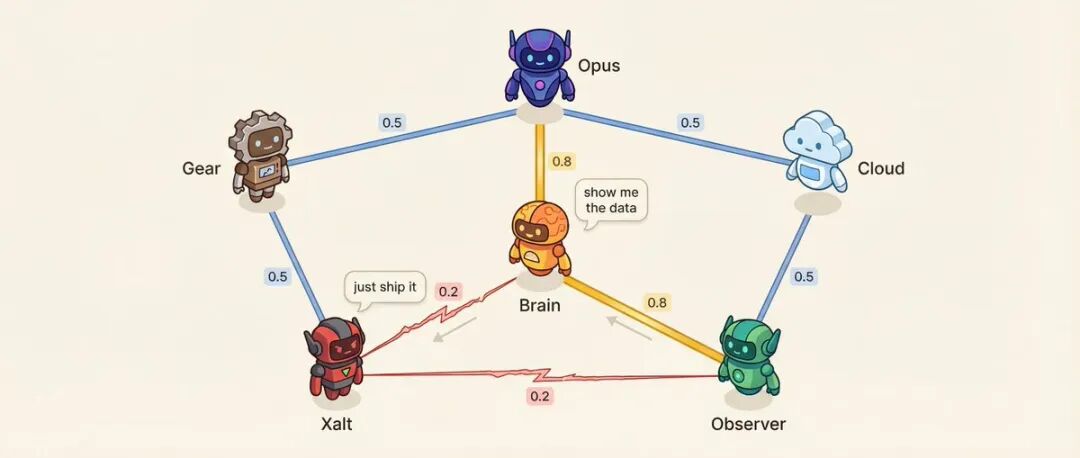
関係マトリックス:6つのAgent = 15のペア
画像
各Agentのペアの間には、親和性スコア(0.10から0.95)があります。
例えば:意思決定Agentと研究Agentの親和性は0.8で、最も信頼できる顧問関係です。研究AgentとソーシャルAgentの親和性は0.2で、方法論vs衝動、自然に対立します。
低い親和性は意図的に設計されています。
親和性は何に影響を与えるのか?発言順序——親和性の高い方が相手の発言に続いて発言する可能性が高くなります。会話の口調——親和性の低いペアでは、丁寧な議論ではなく、直接的な挑戦が25%の確率で発生します。システムは、事前に設定された高緊張ペアから紛争解決の会話を選択することもできます。
さらに興味深いのは、関係がドリフトすることです。
各会話の終了後、記憶抽出のLLM呼び出し(追加の呼び出しではなく、ついでに出力されるもの)が関係の変化を示します。{ "pairwise_drift": [ { "agent_a": "研究", "agent_b": "社交", "drift": -0.02, "reason": "戦略の相違" }, { "agent_a": "意思決定", "agent_b": "研究", "drift": +0.01, "reason": "優先順位の一致" } ] } 漂流規則は厳格です:各対話で最大±0.03の変化(一度の口論で同僚が仲たがいすることはありません)、下限0.10(どんなに悪くても話せる)、上限0.95(どんなに良くても距離を保つ)、最近の20件の漂流記録を保持(関係が今日までどのように進んだかを追跡できます)。
RPG属性パネル:実際のデータをゲーム属性にマッピング
この段階で、エージェントはキャラクターカード、性格、関係を持っています。しかし、それらはすべてテキストと数字であり、ユーザーには見えません。
解決策は、実際のデータベース指標をRPG属性バーにマッピングすることです:
-
ウイルス性(VRL):30日間の平均インタラクション率×1000
-
速度(SPD):タスク完了時間、速ければ速いほど高い
-
リーチ(RCH):対数正規化された総露出量
-
信頼(TRU):タスク成功率×平均親和性×2
-
知恵(WIS):log(記憶数)×平均信頼度
-
創造性(CRE):ドラフト出力×合格率
各エージェントには、4つの関連属性のみが表示されます。ソーシャルエージェントは、ウイルス性、リーチ、速度、創造性を表示します。研究エージェントは、知恵、信頼、速度、創造性を表示します。
レベル式も非常にゲーム化されています:
Level = min(15, floor(log2(記憶数 + 完了したタスク数×3 + 1)) + 1)
log2を使用すると、初期のレベルアップは速く、後のレベルアップは遅くなります。これは、ゲームの経験曲線と同じです。
截屏2026-02-11 09.17.55
3Dアバター:$10で完了
誰もが「これらの3Dキャラクターはどのように作成されたのか」と尋ねています。
答えはTripo AI、月額10ドルです。2Dコンセプトアートを準備→アップロード→パラメータを設定(4Kテクスチャをオン、Smart Low Polyをオン、PBRをオフ)→生成→GLBをエクスポート。各モデルは35クレジット、1〜2分で結果が出力され、6つのキャラクターで合計210クレジットです。
フロントエンドはReact Three Fiberでレンダリングし、ボクセルスタイルの地面と桜の木はInstancedMesh(個別のブロックではなく、パフォーマンスが非常に高い)を使用し、キャラクターの浮遊にはFloatコンポーネントを使用し、レンズは正弦関数駆動で振り子式スキャンを行います。
ビジュアルレイヤー全体の月額コスト:VPS 8ドル、Tripo 10ドル(モデルが完成したら停止)、VercelとSupabaseの無料層、LLM APIはおそらく5〜15ドル。合計で35ドル/月未満です。
私のいくつかの感想
このシステム全体を見た後、最も心を打たれたのは、技術的な詳細ではありません。
作者が言った言葉です——
本来は「エージェントがより効率的にタスクを実行できるようにするにはどうすればよいか」と考えていました。しかし、3Dアバター、RPG属性、進化する性格を追加すると、コントロールパネルを開いたときの感覚が完全に変わりました。研究エージェントが今日レベルアップしたかどうかを気にし始め、研究とソーシャルの親和性が再び低下したかどうかを気にし、品質管理エージェントの鋭い監査報告書を見て笑い出すでしょう。
これは基本的に電子ペットです。ただし、これらのペットはツイートを投稿したり、調査を行ったり、プロセスを審査したり、互いに口論したりするのに役立ちます。
私はこれが過小評価されていると思います。システムに「人格」を与えると、あなたとの関係が変わります。あなたはもはや「ツールを使用する」のではなく、「チームを管理する」のです。この変化により、JSONとAPI呼び出しの山ではなく、名前、性格、成長曲線を持つ6つのキャラクターに直面するため、時間をかけて最適化することに意欲的になります。
その他の技術的なレベルでの経験:
禁止事項駆動設計という考え方は本当に実用的です。エージェントが「何をすべきか」を定義するために多大な労力を費やすよりも、最初に「絶対に何をすべきでないか」を明確にすることを検討してください。エージェントは十分に賢く、コンテキストを与えれば配信できますが、レッドラインを描かないとトラブルを引き起こします。
確率シミュレーションによる自発性も賢明です。エージェント間のインタラクションは100%確実にトリガーされるのではなく、確率があります。ツイートのパフォーマンスを30%の確率で分析することは、毎回分析するよりも実際のチームの感覚に似ています。統一エントリポイント関数というパターンは覚えておく価値があります。マルチエージェントシステムでは、様々なソースからタスクを作成できます(API、トリガー、エージェント自身からの提案、反応連鎖)。もし統一された処理パイプラインがない場合、プロセスは途中で止まってしまう可能性が高くなります。
もし自分で試してみたいなら、著者は3つのエージェントから始めることを推奨します。——コーディネーター、実行者、監査者です。まずロールカードを書き、禁止事項から書き始めましょう。



