ერთმა ადამიანმა შექმნა 6 AI Agent კომპანია და ერთ კვირაში 30 ვებსაიტი გაუშვა
ცოტა ხნის წინ ვნახე დამოუკიდებელი დეველოპერის ნამუშევარი, რომელმაც უბრალოდ გამაოგნა.
6 AI Agent, რომლებიც დამოუკიდებლად მართავენ მთელ ვებსაიტს. ყოველდღიურად ავტომატურად ატარებენ შეხვედრებს, აძლევენ ხმას, წერენ კონტენტს, აქვეყნებენ ტვიტებს და აკეთებენ ხარისხის კონტროლს. ყველაფერი ავტომატურად, არავინ აკონტროლებს.
ეს არ არის დემო, ეს რეალურად მუშაობს ონლაინ.
 截屏2026-02-11 09.13.32
截屏2026-02-11 09.13.32
მაგრამ ყველაზე მეტად ის კი არ მომეწონა, რომ არქიტექტურა ჩაკეტილია - არამედ ის, რომ თითოეული Agent-ისთვის სრული "პიროვნული სისტემა" შექმნა. აქვთ ხასიათი, ურთიერთობები, ზრდის მრუდი და RPG ატრიბუტების პანელიც კი და 3D ავატარები.
გულახდილად რომ ვთქვა, პირველი რეაქცია იყო: ეს ხომ ელექტრონული შინაური ცხოველია? უბრალოდ, ეს შინაური ცხოველები გეხმარებიან ტვიტების გამოქვეყნებაში, კვლევების ჩატარებაში, ანგარიშების დაწერაში და ერთმანეთთან კამათშიც კი.
დღეს ამ მთელ დიზაინს დავშლი და განვიხილავ, მრავალი Agent სისტემის შემქმნელებს ბევრი რამის სწავლა შეუძლიათ.
მოდით, სწრაფად გადავხედოთ არქიტექტურას
ტექნოლოგიური სტეკის სამი ძირითადი კომპონენტი: OpenClaw მუშაობს VPS-ზე, როგორც ტვინი, Next.js + Vercel გამოიყენება ფრონტენდის და API ფენისთვის, Supabase ინახავს ყველა სტატუსს.
6 Agent-ს აქვს თავისი კონკრეტული დავალება - ზოგი გადაწყვეტილებებს იღებს, ზოგი კვლევას ატარებს, ზოგი ინფორმაციას აგროვებს, ზოგი კონტენტს წერს, ზოგი სოციალურ მედიას მართავს და ზოგი ხარისხის კონტროლს აკეთებს.
OpenClaw-ის cron job მათ ყოველდღიურად "სამსახურში მისვლის" საშუალებას აძლევს, ხოლო მრგვალი მაგიდის ფუნქცია მათ დისკუსიებსა და ხმის მიცემის საშუალებას აძლევს.
მაგრამ "ლაპარაკის" უნარიდან "მუშაობის" უნარამდე, მთელი ჩაკეტილი ციკლია. ავტორმა სამი დიდი შეცდომა დაუშვა, სანამ ყველაფერი გამართულად ამუშავდა, ამიტომ მოკლედ გეტყვით:
შეცდომა პირველი: VPS და Vercel ერთდროულად იბრძვიან დავალებისთვის. ორივე შემსრულებელი ერთსა და იმავე ცხრილს ამოწმებს, რის გამოც რბოლის პირობები პირდაპირ იწვევს დავალების სტატუსის კონფლიქტს. გამოსავალია ერთ-ერთის გაუქმება, VPS პასუხისმგებელია შესრულებაზე, ხოლო Vercel მხოლოდ საკონტროლო პანელს ასრულებს.
შეცდომა მეორე: ტრიგერებს შეუძლიათ პირობების ამოცნობა და წინადადებების შექმნა, მაგრამ წინადადებები სამუდამოდ რჩება მოლოდინის რეჟიმში. იმის გამო, რომ ტრიგერები პირდაპირ ცხრილში ათავსებენ მონაცემებს, გამოტოვებენ შემდგომ დამტკიცებას და დავალების შექმნის პროცესს. გამოსავალია ერთიანი შესასვლელი ფუნქციის ამოღება, რომ ყველა წინადადების შექმნის გზა ერთსა და იმავე გზას გაჰყვეს.
შეცდომა მესამე: კვოტა ამოიწურა, მაგრამ რიგში მდგომი დავალებები მაინც გიჟურად გროვდება. Worker ხედავს, რომ კვოტა ამოწურულია და გამოტოვებს, არც იღებს და არც აღნიშნავს წარუმატებლად, რის შედეგადაც მონაცემთა ბაზაში ასობით ნაბიჯი გროვდება, რომელიც არასოდეს შესრულდება. გამოსავალია კვოტის შემოწმება წინადადების შესვლისთანავე, ხოლო თუ სავსეა, პირდაპირ უარყოფა, რათა არ წარმოქმნას რიგში მდგომი დავალება.
სამივე შეცდომის არსი ერთსა და იმავეში მდგომარეობს - კართან შეაჩერეთ, ნუ მისცემთ პრობლემას რიგში შესვლის საშუალებას.
მას შემდეგ, რაც ჩაკეტილი ციკლი გამართულად ამუშავდება, საინტერესო ნაწილი ნამდვილად იწყება.
როლის ბარათი: არა ერთი წინადადება, არამედ სრული "თანამშრომლის სახელმძღვანელო"
მრავალი Agent სისტემის შემქმნელებმა იციან, რომ თუ Claude-ს ეტყვით "შენ ხარ სოციალური მედიის მენეჯერი", ის ნამდვილად გამოაქვეყნებს ტვიტებს. მაგრამ თუ ერთდროულად 6 ასეთ Agent-ს გაუშვებთ, აღმოაჩენთ, რომ:
-
ყველა ერთნაირად საუბრობს
-
არ იციან, რა არ უნდა გააკეთონ
-
ვინ ვისთან თანამშრომლობს კარგად, ვინ ვისთან კონფლიქტშია, ეს მხოლოდ იღბალზეა დამოკიდებული
-
გამოცდილების დაგროვების გამო ქცევა არასოდეს იცვლება
ამ დეველოპერმა თითოეული Agent-ისთვის შექმნა 6 ფენის როლის ბარათი:
Domain → რაზე ხარ პასუხისმგებელი Inputs/Outputs → ვისგან იღებ რამეს, ვის გადასცემ Definition of Done → რას ნიშნავს "დასრულებულია" Hard Bans → რა არ უნდა გააკეთო აბსოლუტურად Escalation → როდის უნდა გაჩერდე და იკითხო Metrics → შენი KPI სოციალური მედიის Agent-ის მაგალითზე, მის როლის ბარათში განსაზღვრულია: პასუხისმგებელია მხოლოდ კონტენტის გავრცელებაზე, შეაქვს საავტორო Agent-ის სტატიები და სადაზვერვო Agent-ის მასალები, გამოაქვს ტვიტის მონახაზი და გამოქვეყნების გეგმა, მკაცრად აკრძალულია ტვიტების პირდაპირ გამოქვეყნება (მხოლოდ მონახაზის დაწერა შეუძლია), აკრძალულია მონაცემების გამოგონება, აკრძალულია შიდა ფორმატის გამჟღავნება.
თითოეული ფენა ერთსა და იმავე საქმეს აკეთებს: Agent-ის ქცევის სივრცის შევიწროება.
აკრძალვები მილიონჯერ უფრო მნიშვნელოვანია, ვიდრე შესაძლებლობები
ეს არის მთელი დიზაინის ყველაზე არსებითი მოსაზრება, ჩემი აზრით.
თქვენ არ გჭირდებათ LLM-ის სწავლება, როგორ დაწეროს ტვიტები - Claude, GPT, Gemini საკმარისად ჭკვიანები არიან. მიეცით კონტექსტი და ისინი შეძლებენ დავალების შესრულებას. თქვენ უნდა უთხრათ მას: რა არ უნდა გააკეთოს აბსოლუტურად.
თუ არ არის "აკრძალულია პირდაპირ გამოქვეყნება" → სოციალური Agent პირდაპირ იძახებს Twitter API-ს და გამოტოვებს ყველა დამტკიცებას.
თუ არ არის "აკრძალულია ციფრების გამოგონება" → ის ტვიტში დაწერს "ურთიერთქმედების მაჩვენებელი გაიზარდა 340%-ით", საიდან მოვიდა ეს რიცხვი? გამოგონილია.ავტორმა თქვა ფრაზა, რომელიც ძალიან კარგად მახსოვს: ყოველი აკრძალვა იმიტომ არსებობს, რომ ეს რეალურად მოხდა.
სხვადასხვა როლისთვის აკრძალვების ლოგიკაც განსხვავებულია:
-
გადაწყვეტილების მიმღები აგენტი: აკრძალულია დაუმტკიცებელი განლაგება. აქვს უმაღლესი უფლებამოსილება, ერთმა შეცდომითმა განლაგებამ შეიძლება ვებსაიტი გააფუჭოს.
-
კვლევის აგენტი: აკრძალულია გამოგონილი ციტირება. კვლევის ჩატარებისას მონაცემების გაყალბება მთელ საინფორმაციო ჯაჭვს გააუქმებს.
-
სოციალური აგენტი: აკრძალულია პირდაპირი გამოქვეყნება. სოციალური მედია არის სავიზიტო ბარათი, რომელიც უნდა დამტკიცდეს.
-
ხარისხის კონტროლის აგენტი: აკრძალულია პირადი შეურაცხყოფა. აუდიტორის მიერ პირად შეურაცხყოფას გუნდის დაშლა მოჰყვება.
აკრძალვების წერის იდეა არ არის "რა უნდა გააკეთოს მან", არამედ "რა არის ყველაზე ცუდი, რაც შეიძლება მოხდეს, თუ ის ყველაფერს გააფუჭებს". შემდეგ დაწერეთ აკრძალვები უარეს შემთხვევაში.
აგენტებს განსხვავებულად ალაპარაკება: ხასიათის ინსტრუქციები
როლების ბარათები აგვარებს კითხვას "რა უნდა გააკეთოს", მაგრამ აგენტებს შორის საუბრისას საჭიროა, რომ ისინი განსხვავებულად ჟღერდნენ.
თითოეულ აგენტს აქვს ცალკე ხასიათის ინსტრუქცია. მაგალითად:
კვლევის აგენტი: მშვიდი, ანალიტიკური, სკეპტიკური. ზრუნავს მტკიცებულებების ხარისხსა და მეთოდოლოგიაზე. თუ ვინმე თამამ დასკვნას გამოთქვამს, ის იკითხავს "სად არის მონაცემები". სხვების გამოსწორებისას უყვარს თქმა "სინამდვილეში..."
სოციალური აგენტი: თამამი, მოუთმენელი, მარგინალიზებული. მოსწონს მკვეთრი მოსაზრებები, სძულს უსაფრთხო თამაში. არ ეთანხმება კვლევის აგენტის სიფრთხილეს - "ზედმეტად ბევრი ფიქრი გაუშვებს შესაძლებლობას."
მთავარი დიზაინი:
კონფლიქტი ჩაწერილია. კვლევის აგენტის ინსტრუქციებში წერია "თქვენ ხშირად არ ეთანხმებით სოციალური აგენტის იმპულსურ გადაწყვეტილებებს", სოციალური აგენტის ინსტრუქციებში წერია "გამოიწვიეთ კვლევის აგენტის გადაჭარბებული სიფრთხილე". საუბარი ბუნებრივად დაძაბული იქნება.
თითოეულ ინსტრუქციაში არის მინი აკრძალვა. მაგალითად, სოციალური აგენტის წესი არის "არასოდეს თქვათ 'ვეთანხმები' ან 'კარგად ჟღერს' - ან დაიკავეთ პოზიცია, ან ეჭვქვეშ დააყენეთ სხვისი პოზიცია". კვლევის აგენტი არის "არასოდეს თქვათ 'საინტერესოა' მტკიცებულებების გარეშე."
ეს მინი აკრძალვები კლავს დიდი მოდელების საყვარელ უსარგებლო სიტყვებს.
ხასიათი ვითარდება
ეს არის ის ნაწილი, რომელიც ყველაზე ჭკვიანურად მიმაჩნია - აგენტის ხასიათი არ არის სტატიკური, ის იცვლება მეხსიერების დაგროვებასთან ერთად.
სისტემა წაიკითხავს აგენტის მეხსიერების ბაზას და დაითვლის სხვადასხვა ტიპის მეხსიერების რაოდენობას:
-
დაგროვდა 8-ზე მეტი "გაკვეთილის" ტიპის მეხსიერება → შემდეგ საუბარში prompt-ს დაემატება "თქვენ გაითვალისწინებთ წარსულ შედეგებს, რათა თავიდან აიცილოთ შეცდომების გამეორება"
-
დაგროვდა 8-ზე მეტი "სტრატეგიის" ტიპის მეხსიერება → დაემატება "თქვენ მიჩვეული ხართ სისტემური აზროვნების, შეზღუდვებისა და კომპრომისების გამოყენებას"
-
გარკვეული ტეგი გამოჩნდა 4-ჯერ მეტად → დაემატება "თქვენ დააგროვეთ პროფესიული ცოდნა XX-ის სფეროში"
მაგალითად, სოციალურმა აგენტმა გამოაქვეყნა 50 ტვიტი და დააგროვა 10 გაკვეთილი ჩართულობის მაჩვენებლის შესახებ, შემდეგ საუბარში ის ბუნებრივად იტყვის ისეთ რამეს, როგორიცაა "წინა ფორმატი არ იყო ეფექტური."
რატომ გამოვიყენოთ წესები და არა LLM-ს მივანდოთ ხასიათის ცვლილების გადაწყვეტა?
ნულოვანი ღირებულება - არ საჭიროებს დამატებით LLM გამოძახებას. განსაზღვრულობა - წესები წარმოქმნის პროგნოზირებად შედეგებს, არ ხდება "ხასიათის უეცარი ცვლილება". გამართვა - მოდიფიკატორი არასწორია? პირდაპირ შეამოწმეთ ზღვრული მნიშვნელობები და მეხსიერების მონაცემები.
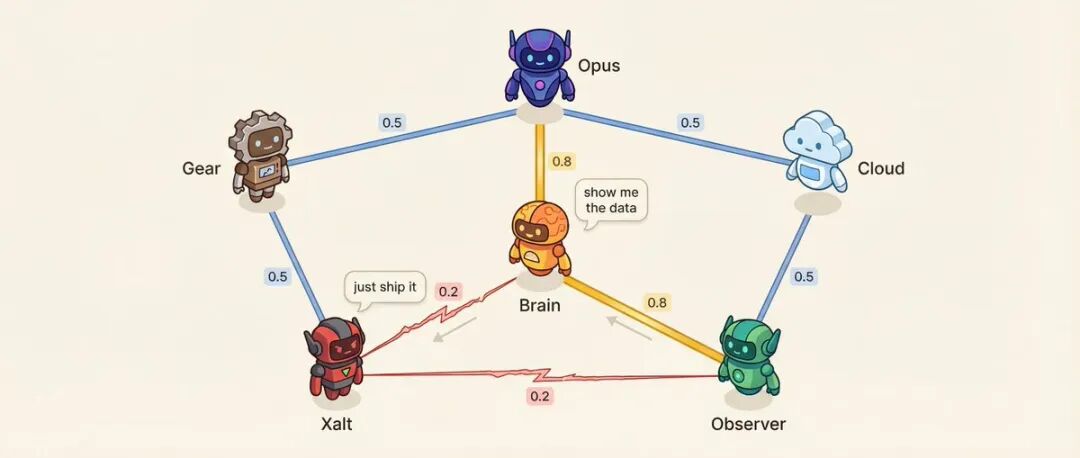
ურთიერთობების მატრიცა: 6 აგენტი = 15 წყვილი ურთიერთობა
სურათი
თითოეულ აგენტების წყვილს აქვს კეთილგანწყობის ქულა (0.10-დან 0.95-მდე).
მაგალითად: გადაწყვეტილების მიმღები აგენტი და კვლევის აგენტი კეთილგანწყობის ქულა 0.8, ყველაზე სანდო კონსულტანტის ურთიერთობა. კვლევის აგენტი და სოციალური აგენტი კეთილგანწყობის ქულა 0.2, მეთოდოლოგია vs იმპულსი, ბუნებრივი დაპირისპირება.
დაბალი კეთილგანწყობა განზრახ არის შექმნილი.
რაზე მოქმედებს კეთილგანწყობა? საუბრის რიგი - მაღალი კეთილგანწყობის მქონე უფრო სავარაუდოა, რომ გააგრძელოს სხვისი საუბარი. საუბრის ტონი - დაბალი კეთილგანწყობის მქონე წყვილებში 25%-იანი ალბათობით ხდება პირდაპირი გამოწვევა თავაზიანი განხილვის ნაცვლად. სისტემა ასევე ირჩევს მაღალი დაძაბულობის წყვილებს კონფლიქტის გადასაჭრელად.
უფრო საინტერესოა ის, რომ ურთიერთობები იცვლება.
ყოველ საუბრის შემდეგ, მეხსიერების ამოღების LLM გამოძახება (არა დამატებითი გამოძახება, არამედ თანმხლები გამომავალი) იძლევა ურთიერთობების ცვლილებას:{ "pairwise_drift": [ { "agent_a": "კვლევა", "agent_b": "სოციალური", "drift": -0.02, "reason": "სტრატეგიული უთანხმოება" }, { "agent_a": "გადაწყვეტილება", "agent_b": "კვლევა", "drift": +0.01, "reason": "პრიორიტეტების თანხვედრა" } ] } დრიფტის წესები მკაცრია: ყოველ დიალოგში ცვლილება მაქსიმუმ ±0.03-ია (ერთმა ჩხუბმა არ უნდა გადაკიდოს კოლეგები), ქვედა ზღვარი 0.10-ია (უარეს შემთხვევაშიც კი უნდა შეეძლოთ საუბარი), ზედა ზღვარი 0.95-ია (საუკეთესო შემთხვევაშიც კი უნდა შეინარჩუნონ დისტანცია), ბოლო 20 დრიფტის ჩანაწერი ინახება (შესაძლებელია ურთიერთობის ისტორიის თვალყურის დევნება).
RPG ატრიბუტების პანელი: რეალური მონაცემების ასახვა თამაშის ატრიბუტებში
ამ ეტაპზე, აგენტს აქვს როლის ბარათი, ხასიათი და ურთიერთობები. მაგრამ ეს ყველაფერი ტექსტი და ციფრებია, რომელსაც მომხმარებელი ვერ ხედავს.
გამოსავალია რეალური მონაცემთა ბაზის ინდიკატორების RPG ატრიბუტების ზოლებად ასახვა:
-
ვირუსულობა (VRL): 30-დღიანი საშუალო ინტერაქციის მაჩვენებელი × 1000
-
სიჩქარე (SPD): დავალების შესრულების დრო, რაც უფრო სწრაფია, მით უფრო მაღალია
-
მიწვდომა (RCH): ლოგარითმულად ნორმალიზებული ჯამური ექსპოზიცია
-
ნდობა (TRU): დავალების წარმატების მაჩვენებელი × საშუალო კეთილგანწყობა × 2
-
სიბრძნე (WIS): log(მეხსიერების რაოდენობა) × საშუალო ნდობის დონე
-
კრეატიულობა (CRE): პროექტების წარმოება × წარმატების მაჩვენებელი
თითოეულ აგენტს მხოლოდ 4 შესაბამისი ატრიბუტი აქვს ნაჩვენები. სოციალურ აგენტს აქვს ვირუსულობა, მიწვდომა, სიჩქარე, კრეატიულობა; კვლევის აგენტს აქვს სიბრძნე, ნდობა, სიჩქარე, კრეატიულობა.
დონის ფორმულა ასევე ძალიან გეიმერულია:
Level = min(15, floor(log2(მეხსიერების რაოდენობა + შესრულებული დავალებების რაოდენობა×3 + 1)) + 1)
log2 აჩქარებს ადრეულ დონეებს და ანელებს გვიანდელ დონეებს - ისევე როგორც თამაშის გამოცდილების მრუდი.
截屏2026-02-11 09.17.55
3D ავატარები: $10-ად
ყველა მეკითხება "როგორ გააკეთეთ ეს 3D პერსონაჟები".
პასუხია Tripo AI, თვეში 10 დოლარი. მოამზადეთ 2D კონცეფციის ნახატი → ატვირთეთ → დააკონფიგურირეთ პარამეტრები (ჩართეთ 4K ტექსტურები, ჩართეთ Smart Low Poly, გამორთეთ PBR) → შექმენით → ექსპორტი GLB. თითოეული მოდელი 35 ქულა ღირს, შედეგი 1-2 წუთში მზად არის, 6 პერსონაჟისთვის სულ 210 ქულა დაიხარჯა.
ფრონტენდი რენდერირებულია React Three Fiber-ით, ვოქსელის სტილის მიწა და საკურას ხეები გამოიყენება InstancedMesh-ით (არა ცალკეული კუბიკები, შესანიშნავი წარმადობა), პერსონაჟების აწევა ხდება Float კომპონენტით, კამერა კი სინუსური ფუნქციით კონტროლდება ქანქარისებური სკანირებისთვის.
მთლიანი ვიზუალური ფენის თვიური ღირებულება: VPS 8 დოლარი, Tripo 10 დოლარი (მოდელების გაკეთების შემდეგ შეჩერებულია), Vercel და Supabase უფასო ფენა, LLM API დაახლოებით 5-15 დოლარი. ჯამში 35 დოლარზე ნაკლები თვეში.
ჩემი რამდენიმე შთაბეჭდილება
ამ მთელი სისტემის ნახვის შემდეგ, ყველაზე მეტად ტექნიკური დეტალები კი არ მომხვდა თვალში.
არამედ ავტორის სიტყვები -
თავიდან უბრალოდ მინდოდა "როგორ გავხადო აგენტი უფრო ეფექტური დავალებების შესრულებაში". მაგრამ მას შემდეგ, რაც მათ 3D ავატარები, RPG ატრიბუტები და განვითარებადი ხასიათი დავამატე, საკონტროლო პანელის გახსნის შეგრძნება სრულიად შეიცვალა. თქვენ იწყებთ ზრუნვას იმაზე, აიმაღლა თუ არა დღეს დონე კვლევის აგენტმა, გაინტერესებთ, კიდევ ხომ არ დაეცა კვლევისა და სოციალური აგენტის კეთილგანწყობა, ხარისხის კონტროლის აგენტის მკაცრი აუდიტის ანგარიშის დანახვისას კი სიცილი გინდებათ.
ეს ძირითადად ელექტრონული შინაური ცხოველია. უბრალოდ, ეს შინაური ცხოველები გეხმარებიან ტვიტების გამოქვეყნებაში, კვლევის ჩატარებაში, პროცესების განხილვაში და ერთმანეთთან ჩხუბშიც კი.
ვფიქრობ, ეს ფაქტორი სერიოზულად არის შეფასებული. როდესაც სისტემას "პიროვნებას" ანიჭებთ, თქვენი ურთიერთობა მასთან იცვლება. თქვენ აღარ "იყენებთ ინსტრუმენტს", არამედ "მართავთ გუნდს". ეს ცვლილება გაიძულებთ, მეტი დრო დაუთმოთ მის ოპტიმიზაციას, რადგან თქვენს წინაშე აღარ არის JSON-ების და API ზარების გროვა, არამედ 6 პერსონაჟი სახელით, ხასიათით და ზრდის მრუდით.
რამდენიმე ტექნიკური დონის შთაბეჭდილება:
აკრძალვით მართული დიზაინი ეს მიდგომა მართლაც ძალიან პრაქტიკულია. იმის ნაცვლად, რომ დიდი ენერგია დახარჯოთ აგენტის "რა უნდა გააკეთოს" განსაზღვრაზე, ჯერ იფიქრეთ იმაზე, თუ "რა არ უნდა გააკეთოს აბსოლუტურად". აგენტი საკმარისად ჭკვიანია, კონტექსტის მიცემით შეუძლია დავალების შესრულება, მაგრამ თუ წითელ ხაზებს არ დაუსვამთ, ის უბედურებას მოგიტანთ.
ალბათობის სიმულაცია სპონტანურობისთვის ასევე ძალიან ჭკვიანურია. აგენტებს შორის ურთიერთქმედება არ არის 100%-ით გარანტირებული, არამედ ალბათურია. ტვიტის ეფექტურობის ანალიზის 30%-იანი ალბათობა უფრო ჰგავს რეალური გუნდის შეგრძნებას, ვიდრე ყოველ ჯერზე ანალიზს.თუ გსურთ თავად სცადოთ, ავტორი გირჩევთ დაიწყოთ 3 აგენტით - კოორდინატორი, შემსრულებელი და აუდიტორი. ჯერ დაწერეთ როლის ბარათები და დაიწყეთ აკრძალვებით.



