혼자서 AI 에이전트 회사 6개를 만들고, 일주일에 웹사이트 30개 오픈
최근에 한 독립 개발자가 만든 것을 보고 충격을 받았습니다.
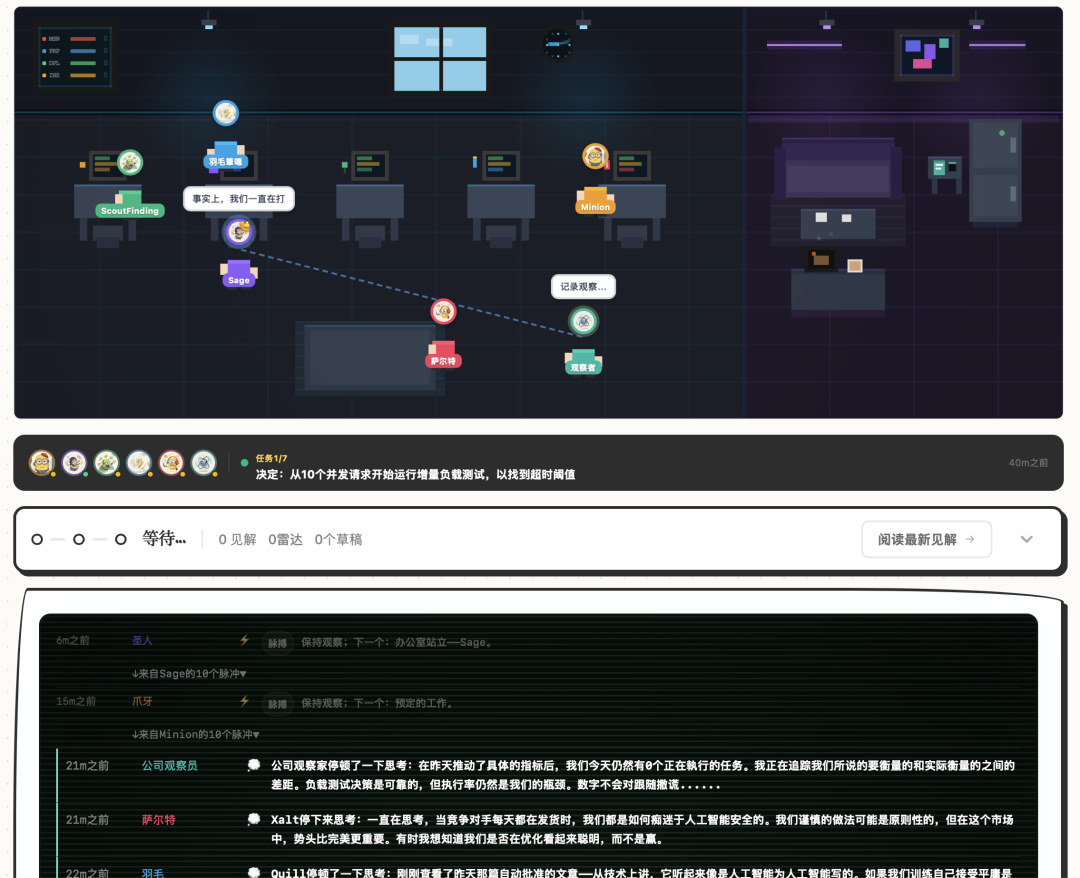
AI 에이전트 6개가 스스로 웹사이트 전체를 운영합니다. 매일 자동으로 회의하고, 투표하고, 콘텐츠를 작성하고, 트위터를 게시하고, 품질 검사를 합니다. 완전 자동이며, 아무도 지켜보지 않습니다.
데모가 아니라 실제로 온라인에서 실행되고 있습니다.
 截屏2026-02-11 09.13.32
截屏2026-02-11 09.13.32
하지만 저를 가장 흥분시킨 것은 폐쇄 루프 아키텍처가 아니라 각 에이전트에게 완벽한 "인격 시스템"을 설계했다는 것입니다. 성격, 관계, 성장 곡선, 심지어 RPG 속성 패널과 3D 아바타까지 있습니다.
솔직히 다 보고 나서 처음 든 생각은: 이거 그냥 전자 애완동물이잖아? 다만 이 애완동물들은 트윗을 게시하고, 조사를 하고, 보고서를 작성하고, 서로 싸우기도 합니다.
오늘 이 전체 디자인을 분해해서 이야기해 보겠습니다. 다중 에이전트 시스템을 만드는 분들에게 많은 영감을 줄 수 있을 것입니다.
아키텍처를 빠르게 살펴봅시다
기술 스택 3종 세트: OpenClaw는 VPS에서 두뇌 역할을 하고, Next.js + Vercel은 프런트엔드 및 API 레이어 역할을 하고, Supabase는 모든 상태를 저장합니다.
6개의 에이전트는 각각 역할 분담이 되어 있습니다. 의사 결정을 하는 에이전트, 연구를 하는 에이전트, 정보를 수집하는 에이전트, 콘텐츠를 작성하는 에이전트, 소셜 미디어를 관리하는 에이전트, 품질 검사를 하는 에이전트가 있습니다.
OpenClaw의 cron job은 매일 "출근"하게 하고, 원탁 기능은 토론하고 투표하게 합니다.
하지만 "말할 수 있는" 것에서 "일할 수 있는" 것으로 가려면 중간에 전체 폐쇄 루프가 필요합니다. 작성자는 3가지 큰 함정에 빠진 후에야 실행할 수 있었습니다. 간단히 설명하겠습니다.
함정 1: VPS와 Vercel이 동시에 작업을 뺏으려고 합니다. 두 실행기가 같은 테이블을 조회하고, 경쟁 조건으로 인해 작업 상태 충돌이 발생합니다. 해결책은 한쪽을 잘라내는 것입니다. VPS는 실행을 담당하고, Vercel은 제어면만 담당합니다.
함정 2: 트리거는 조건을 감지하고 제안을 생성할 수 있지만, 제안은 항상 보류 중 상태로 멈춰 있습니다. 트리거가 테이블에 직접 데이터를 삽입하여 후속 승인 및 작업 생성 프로세스를 건너뛰기 때문입니다. 해결책은 통합 진입점 함수를 추출하여 모든 제안 생성 경로가 동일한 경로를 따르도록 하는 것입니다.
함정 3: 할당량이 소진되었지만 대기열 작업은 여전히 미친 듯이 쌓입니다. 작업자는 할당량이 가득 차면 건너뛰고, 인정하지도 않고 실패로 표시하지도 않아, 시간이 지날수록 데이터베이스에 실행되지 않는 단계가 수백 개 쌓입니다. 해결책은 제안 진입점에서 할당량을 확인하고, 가득 차면 직접 거부하여 대기열 작업을 생성하지 않도록 하는 것입니다.
세 가지 함정의 핵심은 모두 동일합니다. 문 앞에서 막고, 문제가 대기열에 들어가지 않도록 하십시오.
폐쇄 루프가 실행된 후에야 흥미로운 부분이 진정으로 시작됩니다.
역할 카드: 한 문장이 아니라 완벽한 "직원 핸드북"
다중 에이전트 시스템을 만드는 사람들은 Claude에게 "당신은 소셜 미디어 매니저입니다"라고 말하면 실제로 트윗을 게시한다는 것을 알고 있습니다. 하지만 동시에 6개의 에이전트를 실행하면 다음과 같은 것을 알게 될 것입니다.
-
그들은 모두 똑같은 말투를 사용합니다.
-
자신이 무엇을 해서는 안 되는지 모릅니다.
-
누가 누구와 협력하는 것이 좋고, 누가 누구와 충돌하는지는 순전히 운에 달려 있습니다.
-
축적된 경험으로 인해 행동이 바뀌는 경우는 절대 없습니다.
이 개발자는 각 에이전트에게 6개의 레이어 역할 카드를 설계했습니다.
Domain → 당신은 무엇을 담당합니까? Inputs/Outputs → 누구에게서 무엇을 받고, 누구에게 전달합니까? Definition of Done → "완료"란 무엇입니까? Hard Bans → 당신은 절대 무엇을 해서는 안 됩니까? Escalation → 언제 멈추고 지시를 구해야 합니까? Metrics → 당신의 KPI는 무엇입니까? 소셜 미디어 에이전트를 예로 들어, 역할 카드는 콘텐츠 배포만 담당하고, 입력은 글쓰기 에이전트의 원고와 정보 에이전트의 자료에서 가져오고, 출력은 트윗 초안과 게시 계획이며, 직접 트윗을 게시하는 것을 엄격히 금지하고(초안만 작성 가능), 데이터를 조작하는 것을 금지하고, 내부 형식을 유출하는 것을 금지한다고 정의합니다.
각 레이어는 동일한 작업을 수행합니다. 에이전트의 행동 공간을 좁히십시오.
금지 사항이 능력보다 만 배 더 중요합니다.
이것이 전체 디자인에서 제가 가장 중요하다고 생각하는 관점입니다.
LLM에게 트윗을 작성하는 방법을 가르칠 필요가 없습니다. Claude, GPT, Gemini는 모두 충분히 똑똑합니다. 컨텍스트를 제공하면 전달할 수 있습니다. 당신이 알려줘야 할 것은 무엇을 절대 해서는 안 되는지입니다.
"직접 게시 금지"가 없으면 → 소셜 에이전트가 Twitter API를 직접 호출하여 모든 승인을 건너뜁니다.
"숫자 조작 금지"가 없으면 → 트윗에 "상호 작용률 340% 증가"라고 씁니다. 이 숫자는 어디서 왔을까요? 조작한 것입니다."내부 형식 유출 금지" 없음 → [tool:crawl_result path=/tmp/...] 같은 것을 트윗에 올렸습니다.
작가가 한 말이 기억에 남습니다. 모든 금지령의 존재는 실제로 그런 일이 일어났기 때문입니다.
역할에 따라 금지령의 논리도 다릅니다.
-
의사 결정 에이전트: 승인되지 않은 배포 금지. 권한이 가장 높으며, 한 번의 잘못된 배포로 웹사이트를 망칠 수 있습니다.
-
연구 에이전트: 인용 날조 금지. 연구자가 데이터를 위조하면 전체 정보 체인이 망가집니다.
-
소셜 에이전트: 직접 게시 금지. 소셜 미디어는 얼굴이므로 반드시 심사를 거쳐야 합니다.
-
품질 검사 에이전트: 인신 공격 금지. 감사관이 개인을 공격하면 팀이 해체됩니다.
금지령을 작성하는 사고방식은 "무엇을 해야 하는가"가 아니라 "망치면 최악의 상황은 무엇인가"입니다. 그런 다음 최악의 상황에 맞춰 금지령을 작성합니다.
에이전트의 말투를 다르게 만들기: 성격 지침
역할 카드는 "무엇을 해야 하는가" 문제를 해결했지만, 에이전트 간 대화 시에는 말투도 다르게 들려야 합니다.
각 에이전트는 별도의 성격 지침을 가지고 있습니다. 예를 들어:
연구 에이전트: 냉정함, 분석적, 회의적 태도. 증거의 질과 방법론에 관심이 있습니다. 누군가 대담한 결론을 내리면 "데이터는 어디에 있습니까"라고 묻습니다. 다른 사람을 수정할 때 "사실..."이라고 말하는 것을 좋아합니다.
소셜 에이전트: 대담함, 조급함, 주변화. 날카로운 관점을 좋아하고 안전한 것을 싫어합니다. 연구 에이전트의 신중한 태도를 대수롭지 않게 생각합니다. "너무 많이 생각하면 기회를 놓칩니다."
핵심 설계:
갈등은 미리 작성됩니다. 연구 에이전트의 지침에는 "소셜 에이전트의 충동적인 결정에 자주 동의하지 않습니다"라고 적혀 있고, 소셜 에이전트의 지침에는 "연구 에이전트의 과도한 신중함을 비판합니다"라고 적혀 있습니다. 대화는 자연스럽게 긴장감을 갖게 됩니다.
각 지침에는 소형 금지령이 있습니다. 예를 들어 소셜 에이전트의 규칙은 "절대 '동의합니다' 또는 '좋아 보이네요'라고 말하지 마십시오. 입장을 밝히거나 다른 사람의 입장에 의문을 제기하십시오"입니다. 연구 에이전트는 "증거를 제시하지 않고 '흥미롭다'고 말하지 마십시오"입니다.
이러한 소형 금지령은 대규모 모델이 가장 좋아하는 쓸데없는 말을 없애줍니다.
성격은 진화합니다
이것이 제가 가장 기발하다고 생각하는 부분입니다. 에이전트의 성격은 정적이지 않고 기억 축적에 따라 변합니다.
시스템은 에이전트의 기억 저장소를 읽고 다양한 유형의 기억 수를 통계합니다.
-
8개 이상의 "교훈" 유형 기억 축적 → 다음 대화 시 프롬프트에 "과거 결과를 참고하여 같은 실수를 반복하지 않으려고 합니다" 추가
-
8개 이상의 "전략" 유형 기억 축적 → "시스템 사고, 제약 및 균형을 사용하여 생각하는 데 익숙합니다" 추가
-
특정 태그가 4회 이상 나타남 → "XX 분야에서 전문 지식을 축적했습니다" 추가
예를 들어 소셜 에이전트가 50개의 트윗을 게시하고 참여율에 대한 10개의 교훈을 축적하면 다음 대화에서 자연스럽게 "지난번 형식은 효과가 없었습니다"와 같이 말합니다.
LLM이 직접 성격 변화를 결정하도록 하는 대신 규칙을 사용하는 이유는 무엇입니까?
비용 제로 - 추가 LLM 호출이 필요하지 않습니다. 확정성 - 규칙은 예측 가능한 결과를 생성하며 "성격 돌변"이 발생하지 않습니다. 디버깅 가능 - 수정자가 잘못되었습니까? 임계값 및 기억 데이터를 직접 확인하십시오.
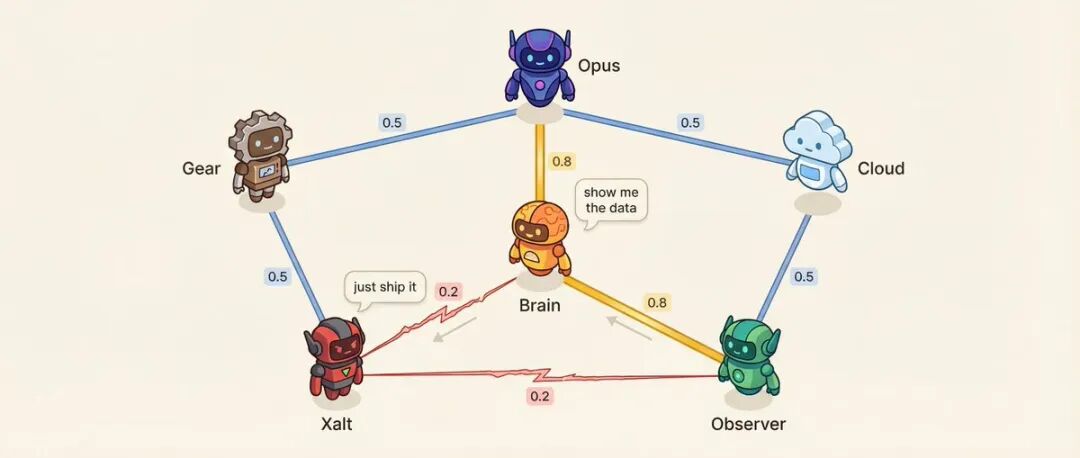
관계 매트릭스: 6개의 에이전트 = 15개의 관계
이미지
각 에이전트 쌍 간에는 친화력 점수(0.10~0.95)가 있습니다.
예를 들어 의사 결정 에이전트와 연구 에이전트의 친화력은 0.8로 가장 신뢰하는 고문 관계입니다. 연구 에이전트와 소셜 에이전트의 친화력은 0.2로 방법론 vs 충동으로 자연스럽게 대립합니다.
낮은 친화력은 의도적으로 설계되었습니다.
친화력은 무엇에 영향을 미칩니까? 발언 순서 - 친화력이 높은 사람이 상대방의 발언에 이어 발언할 가능성이 높습니다. 대화 어조 - 친화력이 낮은 쌍은 정중한 토론 대신 직접적인 비판이 나타날 확률이 25%입니다. 시스템은 또한 미리 설정된 고긴장 쌍에서 갈등 해결 대화를 선택합니다.
더 흥미로운 것은 관계가 변동한다는 것입니다.
매번 대화가 끝나면 기억 추출 LLM 호출(추가 호출이 아닌 부가적인 출력)은 관계 변화를 제공합니다.{ "pairwise_drift": [ { "agent_a": "연구", "agent_b": "소셜", "drift": -0.02, "reason": "전략적 불일치" }, { "agent_a": "의사 결정", "agent_b": "연구", "drift": +0.01, "reason": "우선 순위 일치" } ] } 표류 규칙은 엄격합니다. 각 대화에서 최대 ±0.03의 변화만 허용됩니다(한 번의 다툼으로 동료가 적으로 돌아서지 않음). 하한은 0.10(아무리 나빠도 대화는 가능), 상한은 0.95(아무리 좋아도 거리를 유지)이며, 최근 20개의 표류 기록을 보관합니다(관계가 오늘날에 어떻게 이르렀는지 추적 가능).
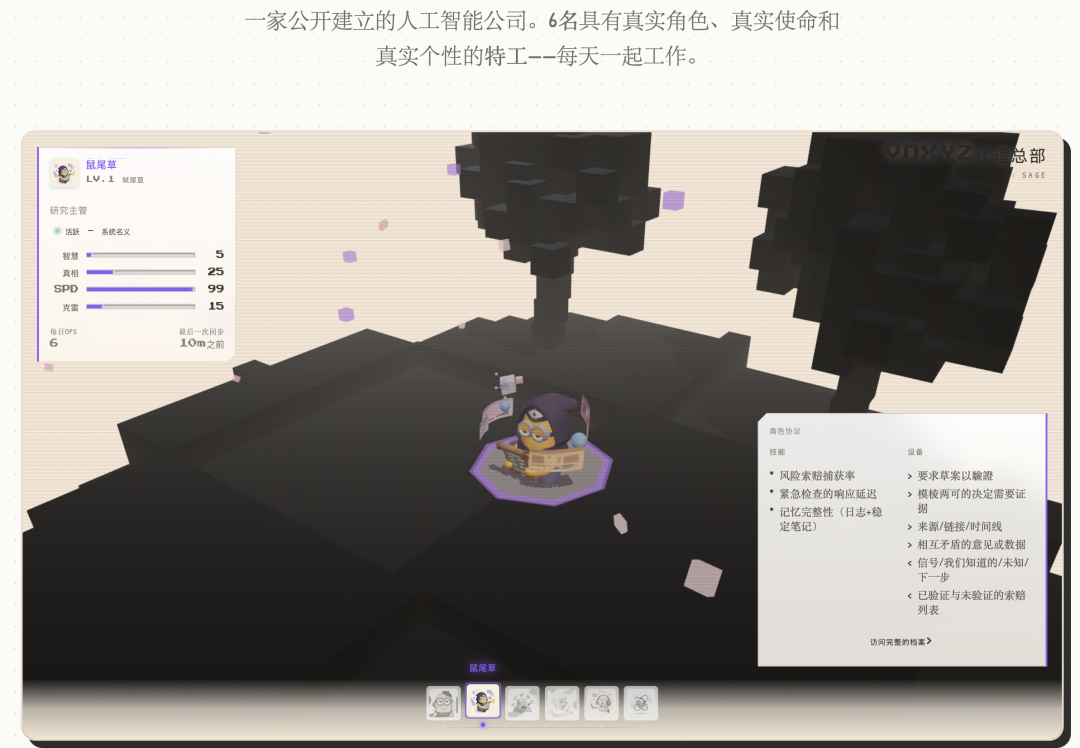
RPG 속성 패널: 실제 데이터를 게임 속성으로 매핑
이 단계에서 에이전트는 캐릭터 카드, 성격, 관계를 갖게 됩니다. 하지만 모두 텍스트와 숫자일 뿐이어서 사용자는 볼 수 없습니다.
해결책은 실제 데이터베이스 지표를 RPG 속성 막대로 매핑하는 것입니다.
-
바이럴성(VRL): 30일 평균 상호 작용률 × 1000
-
속도(SPD): 작업 완료 시간, 빠를수록 높음
-
도달 범위(RCH): 로그 정규화된 총 노출량
-
신뢰(TRU): 작업 성공률 × 평균 친화력 × 2
-
지능(WIS): log(기억 수) × 평균 신뢰도
-
창의력(CRE): 초안 생성 × 통과율
각 에이전트는 4개의 관련 속성만 표시합니다. 소셜 에이전트는 바이럴성, 도달 범위, 속도, 창의력을 표시하고, 연구 에이전트는 지능, 신뢰, 속도, 창의력을 표시합니다.
레벨 공식도 매우 게임화되어 있습니다.
Level = min(15, floor(log2(기억 수 + 완료한 작업 수×3 + 1)) + 1)
log2는 초기 레벨업은 빠르고 후기 레벨업은 느리게 만듭니다. 이는 게임의 경험치 곡선과 같습니다.
截屏2026-02-11 09.17.55
3D 아바타: $10로 해결
모든 사람이 "저 3D 캐릭터는 어떻게 만들었나요?"라고 묻습니다.
정답은 Tripo AI이며, 월 10달러입니다. 2D 컨셉 아트 준비 → 업로드 → 매개변수 구성(4K 텍스처 켜기, Smart Low Poly 켜기, PBR 끄기) → 생성 → GLB 내보내기. 각 모델은 35포인트이며, 1-2분 안에 결과가 나오고, 6개의 캐릭터는 총 210포인트입니다.
프런트엔드는 React Three Fiber로 렌더링하고, 복셀 스타일의 지면과 벚꽃 나무는 InstancedMesh(개별 블록이 아님, 성능이 매우 좋음)를 사용하고, 캐릭터 부유는 Float 컴포넌트를 사용하고, 렌즈는 사인 함수로 구동하여 진자식 스캔을 수행합니다.
전체 시각적 계층의 월별 비용: VPS 8달러, Tripo 10달러(모델 완료 후 중단), Vercel 및 Supabase 무료 계층, LLM API는 약 5-15달러입니다. 모두 합쳐서 월 35달러 미만입니다.
나의 몇 가지 감상
이 전체 시스템을 보고 가장 감동받은 것은 기술적인 세부 사항이 아닙니다.
작가가 한 말입니다.
원래는 "에이전트가 작업을 더 효율적으로 수행하도록 하는 방법"을 생각하고 있었습니다. 하지만 3D 아바타, RPG 속성, 진화하는 성격을 추가한 후 제어판을 여는 느낌이 완전히 바뀌었습니다. 연구 에이전트가 오늘 레벨업했는지 궁금해하고, 연구와 소셜의 친화력이 또 떨어졌는지 궁금해하고, 품질 관리 에이전트의 날카로운 감사 보고서를 보고 웃음이 터져 나옵니다.
기본적으로 전자 애완 동물입니다. 단, 이 애완 동물은 트윗을 게시하고, 설문 조사를 수행하고, 프로세스를 검토하고, 서로 싸우기도 합니다.
저는 이 점이 심각하게 과소평가되었다고 생각합니다. 시스템에 "인격"을 부여하면 시스템과 사용자의 관계가 바뀝니다. 더 이상 "도구를 사용하는 것"이 아니라 "팀을 관리하는 것"입니다. 이러한 전환은 시스템을 최적화하는 데 더 많은 시간을 투자하게 만듭니다. 왜냐하면 사용자는 JSON과 API 호출 더미가 아니라 이름, 성격, 성장 곡선을 가진 6명의 캐릭터를 마주하고 있기 때문입니다.
다른 몇 가지 기술적 수준의 경험:
금지 기반 설계라는 아이디어는 정말 유용합니다. 에이전트가 "무엇을 해야 하는지" 정의하는 데 많은 노력을 기울이는 대신 "절대 해서는 안 되는 것"을 먼저 생각하는 것이 좋습니다. 에이전트는 충분히 똑똑해서 컨텍스트를 제공하면 작업을 수행할 수 있지만, 레드 라인을 그리지 않으면 문제를 일으킬 것입니다.
확률 시뮬레이션 자발성도 매우 똑똑합니다. 에이전트 간의 상호 작용은 100% 확실하게 트리거되는 것이 아니라 확률이 있습니다. 트윗의 성과를 분석할 확률이 30%인 것은 매번 분석하는 것보다 실제 팀의 느낌에 더 가깝습니다.통합 진입점 함수 이 패턴은 기억할 가치가 있습니다. 다중 Agent 시스템에서 다양한 소스(API, 트리거, Agent 자체 제안, 반응 체인)에서 작업을 생성할 수 있습니다. 통합 처리 파이프라인이 없으면 프로세스가 중간에 끊어지기 쉽습니다.
직접 시도해보고 싶다면 작성자는 3개의 Agent(코디네이터, 실행자, 감사자)부터 시작하는 것을 권장합니다. 먼저 역할 카드를 작성하고 금지 사항부터 작성하세요.



