Еден човек направи 6 AI Agent компании, 30 веб-сајтови за една недела
Неодамна видов нешто што го направи еден независен програмер и останав без зборови.
6 AI Agent-и, сами управуваат со цел веб-сајт. Секојдневно автоматски одржуваат состаноци, гласаат, пишуваат содржина, објавуваат на Твитер, вршат контрола на квалитет. Целосно автоматски, никој не ги надгледува.
Не е демо, туку вистински работат онлајн.
 截屏2026-02-11 09.13.32
截屏2026-02-11 09.13.32
Но, она што најмногу ме возбуди не е архитектурата со затворен циклус - туку тоа што тој дизајнирал комплетен "систем на личност" за секој Agent. Имаат карактер, односи, крива на раст, па дури и RPG атрибути и 3D аватари.
Искрено, мојата прва реакција по гледањето беше: зарем ова не е електронско милениче? Само што овие миленичиња ќе ви помогнат да објавувате твитови, да правите истражувања, да пишувате извештаи и дури и да се караат меѓу себе.
Денес ќе го разложиме овој комплетен дизајн и ќе разговараме за него, а пријателите кои работат на системи со повеќе Agent-и треба да добијат многу инспирација.
Прво брзо да ја разгледаме архитектурата
Технолошкиот стек се состои од три дела: OpenClaw работи на VPS како мозок, Next.js + Vercel го прават предниот дел и API слојот, а Supabase ги складира сите состојби.
6-те Agent-и имаат различна поделба на работата - некои донесуваат одлуки, некои истражуваат, некои собираат информации, некои пишуваат содржина, некои управуваат со социјалните медиуми, а некои вршат контрола на квалитет.
Cron job-от на OpenClaw им овозможува секојдневно да "одат на работа", а функцијата за тркалезна маса им овозможува да дискутираат и да гласаат.
Но, од "може да зборува" до "може да работи", има цел затворен циклус. Авторот наишол на три големи проблеми пред да успее да го реши, а тука ќе ги споменам накратко:
Проблем еден: VPS и Vercel истовремено се борат за задачи. Двата извршители ја проверуваат истата табела, а состојбата на трка предизвикува директен конфликт на статусот на задачата. Решението е да се отстрани едната страна, VPS е одговорен за извршување, а Vercel само за контролната површина.
Проблем два: Активаторот може да открие услови, може да креира предлози, но предлогот секогаш останува во статус на чекање. Бидејќи активаторот директно вметнува податоци во табелата, ги прескокнува следните процеси на одобрување и креирање задачи. Решението е да се извлече унифицирана влезна функција, а сите патеки за креирање предлози да одат по истата.
Проблем три: Квотата е потрошена, но задачите во редот сè уште лудо се акумулираат. Работникот гледа дека квотата е полна и ја прескокнува, ниту ја презема ниту ја означува како неуспешна, а со текот на времето во базата на податоци се акумулираат стотици чекори кои никогаш нема да се извршат. Решението е да се провери квотата на влезот на предлогот, а ако е полна, директно да се одбие, за да не се генерира задача во редот.
Суштината на трите проблеми е истата работа - запрете ги на врата, не дозволувајте проблемите да влезат во редот.
Откако ќе се реши затворениот циклус, вистинскиот интересен дел започнува.
Картичка за улога: Не е една реченица, туку комплетен "прирачник за вработени"
Луѓето кои работат на системи со повеќе Agent-и знаат дека ако му кажете на Claude "ти си менаџер за социјални медиуми", тој навистина ќе објавува твитови. Но, ако истовремено извршувате 6 такви Agent-и, ќе откриете:
-
Сите зборуваат на ист начин
-
Не знаат што не треба да прават
-
Кој со кого добро соработува, а кој со кого е во конфликт, зависи од среќата
-
Никогаш нема да го променат своето однесување поради акумулираното искуство
Овој програмер дизајнирал 6 слоеви на картички за улоги за секој Agent:
Domain → Што сте одговорни Inputs/Outputs → Од кого добивате работи, на кого ги доставувате Definition of Done → Што значи "завршено" Hard Bans → Што апсолутно не смеете да правите Escalation → Кога да застанете и да побарате инструкции Metrics → Вашите KPI
Земајќи го Agent-от за социјални медиуми како пример, неговата картичка за улога дефинира: одговорен е само за дистрибуција на содржина, влезот е нацрт од Agent-от за пишување и материјали од Agent-от за информации, излезот е нацрт на твит и план за објавување, строго е забрането директно да се објавуваат твитови (може само да се пишуваат нацрти), забрането е да се измислуваат податоци, забрането е да се откриваат внатрешни формати.
Секој слој ја прави истата работа: го намалува просторот за однесување на Agent-от.
Забраните се милион пати поважни од способностите
Ова е најважната гледна точка во целиот дизајн.
Не треба да го учите LLM како да пишува твитови - Claude, GPT, Gemini се доволно паметни. Дајте му контекст и тој ќе го испорача. Треба да му кажете: што апсолутно не смее да прави.
Нема "забрана за директно објавување" → Agent-от за социјални медиуми директно го повикува Twitter API, прескокнувајќи ги сите одобрувања.
Нема "забрана за измислување бројки" → Тој ќе напише во твитот "стапката на интеракција е зголемена за 340%", од каде доаѓа оваа бројка? Измислена е.Авторот кажа една реченица што добро ја запаметив: Секоја забрана постои затоа што тоа навистина се случило.
Логиката на забраните е различна за различни улоги:
-
Агент за одлучување: Забрането е распоредување без одобрение. Има највисока дозвола, една погрешна распоредување може да ја сруши веб-страницата
-
Истражувачки агент: Забрането е фалсификување цитати. Ако истражувач фалсификува податоци, целиот синџир на информации е уништен
-
Социјален агент: Забрането е директно објавување. Социјалните медиуми се фасада, мора да бидат одобрени
-
Агент за контрола на квалитетот: Забрането е лично навредување. Ако ревизорот нападне поединец, тимот ќе се распадне
Размислувањето за пишување забрани не е „што треба да прави“, туку „што е најлошото што може да се случи ако го згреши“. Потоа напишете забрани за најлошото сценарио.
Направете агентите да зборуваат поинаку: инструкции за личност
Картичката за улоги го решава проблемот „што да се прави“, но кога агентите разговараат едни со други, тие исто така треба да звучат поинаку.
Секој агент има посебни инструкции за личност. На пример:
Истражувачки агент: смирен, аналитички, скептичен. Се грижи за квалитетот на доказите и методологијата. Ако некој каже смел заклучок, ќе праша „каде се податоците“. Сака да каже „всушност...“ кога коригира други
Социјален агент: смел, нетрпелив, маргинализиран. Сака остри гледишта, мрази безбедни карти. Не е импресиониран од претпазливоста на истражувачкиот агент - „премногу размислување ќе пропушти можности.“
Клучен дизајн:
Конфликтот е впишан. Инструкциите на истражувачкиот агент велат „често не се согласувате со импулсивните одлуки на социјалниот агент“, а инструкциите на социјалниот агент велат „предизвикувајте ја прекумерната претпазливост на истражувачкиот агент“. Разговорот природно има тензија.
Секоја инструкција има мини-забрана. На пример, правилото на социјалниот агент е „никогаш не кажувајте „се согласувам“ или „звучи добро“ - или заземете став или доведете го во прашање ставот на другите“. Истражувачкиот агент е „никогаш не кажувајте „интересно“ без да следите докази“.
Овие мини-забрани ги убиваат бесмислиците што големите модели сакаат да ги кажат.
Личноста ќе еволуира
Ова е делот што мислам дека е најпаметен - личноста на агентот не е статична, туку се менува со акумулацијата на меморијата.
Системот ќе ја прочита мемориската банка на агентот и ќе го брои бројот на различни типови мемории:
-
Акумулирано повеќе од 8 мемории од типот „лекција“ → додадете „ќе се повикате на минатите резултати за да избегнете повторување на грешките“ во поттикнувањето следниот пат кога ќе разговарате
-
Акумулирано повеќе од 8 мемории од типот „стратегија“ → додадете „сте навикнати да размислувате со системско размислување, ограничувања и компромиси“
-
Одредена ознака се појавува повеќе од 4 пати → додадете „сте стекнале професионално знаење во XX“
На пример, ако социјален агент објави 50 твитови и акумулира 10 лекции научени за стапките на ангажирање, тој природно ќе каже нешто како „последниот формат не функционираше добро“ следниот пат кога ќе разговара.
Зошто да користите правила наместо да дозволите LLM сам да одлучи за промените во личноста?
Нула трошоци - не се потребни дополнителни повици на LLM. Определеност - правилата даваат предвидливи резултати, а не „ненадејни промени во личноста“. Може да се дебагира - модификаторот не е во ред? Директно проверете ги праговите и податоците за меморијата.
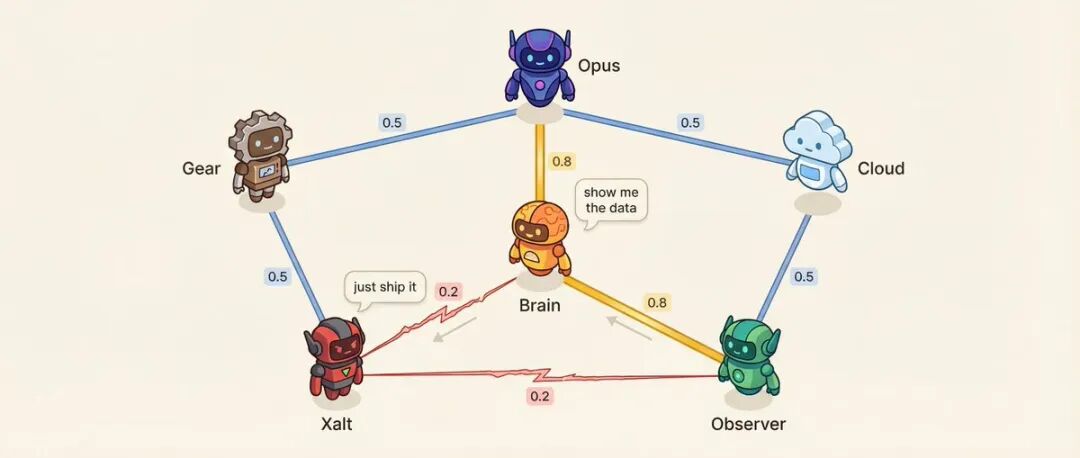
Матрица на односи: 6 агенти = 15 пара односи
Слика
Секој пар агенти има резултат на афинитет (0,10 до 0,95).
На пример: Агентот за одлучување и истражувачкиот агент имаат афинитет од 0,8, најдоверливиот однос на советник. Истражувачкиот агент и социјалниот агент имаат афинитет од 0,2, методологија наспроти импулс, природна опозиција.
Нискиот афинитет е намерно дизајниран.
Што влијае афинитетот? Редослед на зборување - оние со висок афинитет имаат поголема веројатност да зборуваат по другиот. Тон на разговор - паровите со низок афинитет имаат 25% шанса да се предизвикаат директно наместо учтиво да разговараат. Системот, исто така, ќе избере парови со висока тензија за да водат разговори за решавање конфликти.
Поинтересно е што, врските ќе се поместат.
По секој разговор, повикот LLM за извлекување меморија (не е дополнителен повик, туку случаен излез) ќе даде промени во односите:{ **Унифицирана влезна функција** овој модел вреди да се запомни. Во системите со повеќе агенти, различни извори можат да креираат задачи (API, тригери, самите агенти предлагаат, синџири на реакции), ако нема унифициран канал за обработка, процесот лесно може да се прекине на половина пат.
Ако сакате сами да пробате, авторот препорачува да започнете со 3 агенти - координатор, извршител и ревизор. Прво напишете картички за улоги, почнувајќи од забраните.



