Один человек создал 6 AI Agent компаний и запустил 30 веб-сайтов за неделю
Недавно увидел работу одного независимого разработчика, и она меня просто ошеломила.
6 AI Agent, самостоятельно управляющих целым веб-сайтом. Ежедневно автоматически проводят совещания, голосуют, пишут контент, публикуют в Twitter, проводят контроль качества. Полностью автоматически, никто за ними не следит.
Это не демо, это реально работает онлайн.
 截屏2026-02-11 09.13.32
截屏2026-02-11 09.13.32
Но больше всего меня зацепила не замкнутая архитектура, а то, что он разработал для каждого Agent полноценную "систему личности". С характером, отношениями, кривой роста и даже атрибутами RPG и 3D-аватаром.
Честно говоря, после просмотра моя первая реакция была: это же электронные питомцы! Только эти питомцы помогают вам писать твиты, проводить исследования, писать отчеты и даже ссорятся друг с другом.
Сегодня разберем эту конструкцию, думаю, друзья, занимающиеся системами с несколькими Agent, найдут много полезного.
Быстрый обзор архитектуры
Технологический стек из трех частей: OpenClaw работает на VPS в качестве мозга, Next.js + Vercel используются для фронтенда и уровня API, Supabase хранит все состояния.
6 Agent имеют разные обязанности: принятие решений, исследования, сбор информации, написание контента, управление социальными сетями, контроль качества.
Cron job OpenClaw заставляет их ежедневно "приходить на работу", функция круглого стола позволяет им обсуждать и голосовать.
Но между "умением говорить" и "умением работать" лежит целая замкнутая система. Автор наступил на три большие ямы, прежде чем все заработало, вот краткое описание:
Яма 1: VPS и Vercel одновременно борются за задачи. Два исполнителя проверяют одну и ту же таблицу, состояние гонки напрямую приводит к конфликту состояний задач. Решение состоит в том, чтобы отрезать одну сторону, VPS отвечает за выполнение, а Vercel только за плоскость управления.
Яма 2: Триггер может обнаруживать условия, может создавать предложения, но предложение всегда остается в состоянии ожидания. Потому что триггер напрямую вставляет данные в таблицу, пропуская последующее утверждение и процесс создания задачи. Решение состоит в том, чтобы извлечь единую функцию входа, и все пути создания предложений проходят через нее.
Яма 3: Квота исчерпана, но задачи в очереди продолжают безумно накапливаться. Worker видит, что квота заполнена, и пропускает ее, не принимает и не помечает как неудачную, и со временем в базе данных накапливаются сотни шагов, которые никогда не будут выполнены. Решение состоит в том, чтобы проверить квоту на входе предложения, и если она заполнена, сразу же отклонить ее, не позволяя ей генерировать задачи в очереди.
Суть всех трех ям одна и та же: остановить у двери, не позволяйте проблеме попасть в очередь.
После того, как замкнутый цикл заработал, начинается самое интересное.
Карта ролей: не одно предложение, а полное "руководство для сотрудников"
Люди, занимающиеся системами с несколькими Agent, знают, что если вы скажете Claude: "Ты менеджер по социальным сетям", он действительно будет писать твиты. Но если вы запустите 6 таких Agent одновременно, вы обнаружите:
-
Они все говорят одинаково
-
Не знают, чего им не следует делать
-
Кто с кем хорошо сотрудничает, кто с кем конфликтует, зависит от удачи
-
Никогда не меняют свое поведение из-за накопленного опыта
Этот разработчик разработал для каждого Agent 6-уровневую карту ролей:
Domain → За что вы отвечаете Inputs/Outputs → От кого вы берете вещи, кому вы их доставляете Definition of Done → Что значит "сделано" Hard Bans → Что вам абсолютно нельзя делать Escalation → Когда остановиться и обратиться за инструкциями Metrics → Ваши KPI Возьмем, к примеру, Agent по социальным сетям, его карта ролей определяет: отвечает только за распространение контента, получает входные данные от Agent по написанию и материалы от Agent по разведке, выходные данные - черновики твитов и планы публикаций, строго запрещено напрямую публиковать твиты (можно только писать черновики), запрещено выдумывать данные, запрещено раскрывать внутренние форматы.
Каждый уровень делает одно и то же: сужает пространство поведения Agent.
Запреты в миллион раз важнее способностей
Это самая суть всей конструкции, на мой взгляд.
Вам не нужно учить LLM, как писать твиты - Claude, GPT, Gemini достаточно умны. Дайте ему контекст, и он выполнит задачу. Вам нужно сказать ему: что абсолютно нельзя делать.
Нет "запрета на прямую публикацию" → Agent по социальным сетям напрямую вызывает Twitter API, пропуская все утверждения.
Нет "запрета на выдумывание цифр" → Он напишет в твите "уровень взаимодействия вырос на 340%", откуда взялась эта цифра? Выдумал.Автор сказал одну фразу, которую я очень хорошо запомнил: Каждый запрет существует, потому что это действительно произошло.
Логика запретов для разных ролей также отличается:
-
Агент принятия решений: Запрещено развертывание без одобрения. Обладает наивысшими полномочиями, одна ошибка при развертывании может сломать веб-сайт.
-
Исследовательский агент: Запрещено фабриковать цитаты. Если исследователь фальсифицирует данные, вся информационная цепочка будет разрушена.
-
Социальный агент: Запрещено публиковать напрямую. Социальные сети - это витрина, которая должна быть одобрена.
-
Агент контроля качества: Запрещены личные нападки. Если аудитор нападает на личность, команда распадется.
Идея написания запретов заключается не в том, "что он должен делать", а в том, "что будет самым худшим, если он облажается". Затем напишите запрет, ориентируясь на наихудший сценарий.
Сделайте так, чтобы агенты говорили по-разному: инструкции по характеру
Ролевая карта решает проблему "что делать", но когда агенты разговаривают друг с другом, им все равно нужно звучать по-разному.
У каждого агента есть отдельные инструкции по характеру. Например:
Исследовательский агент: Спокойный, аналитический, скептический. Заботится о качестве доказательств и методологии. Если кто-то делает смелый вывод, он спросит: "Где данные?". Исправляя других, любит говорить: "На самом деле..."
Социальный агент: Смелый, нетерпеливый, маргинальный. Любит острые взгляды, ненавидит безопасные карты. Не одобряет осторожность исследовательского агента - "Слишком много думать - упустишь момент."
Ключевой дизайн:
Конфликт заложен в сценарий. В инструкции исследовательского агента написано: "Вы часто не согласны с импульсивными решениями социального агента", а в инструкции социального агента написано: "Оспаривайте чрезмерную осторожность исследовательского агента". Естественно, в диалоге будет напряжение.
В каждой инструкции есть мини-запрет. Например, правило для социального агента: "Никогда не говорите 'Согласен' или 'Звучит хорошо' - либо займите позицию, либо поставьте под сомнение позицию других". Исследовательский агент: "Никогда не говорите 'Интересно', не предоставив подтверждающих доказательств".
Эти мини-запреты убивают бессмысленные слова, которые так любит большая модель.
Характер будет развиваться
Это то, что я считаю самым умным - характер агента не статичен, он меняется с накоплением памяти.
Система считывает базу памяти агента и подсчитывает количество воспоминаний разных типов:
-
Накоплено более 8 воспоминаний типа "урок" → в следующий раз в подсказку к разговору добавляется "Вы будете ссылаться на прошлые результаты, чтобы избежать повторения ошибок"
-
Накоплено более 8 воспоминаний типа "стратегия" → добавляется "Вы привыкли мыслить системно, с ограничениями и компромиссами"
-
Определенный тег появляется более 4 раз → добавляется "Вы накопили профессиональные знания в области XX"
Например, социальный агент опубликовал 50 твитов и накопил 10 уроков об уровне вовлеченности, и в следующий раз в разговоре он, естественно, скажет что-то вроде: "Этот формат в прошлый раз не сработал хорошо".
Почему использовать правила, а не позволять LLM самостоятельно определять изменения характера?
Нулевая стоимость - не требуется дополнительных вызовов LLM. Определенность - правила дают предсказуемые результаты, а не "внезапные изменения характера". Возможность отладки - модификатор неверен? Просто проверьте пороговые значения и данные памяти.
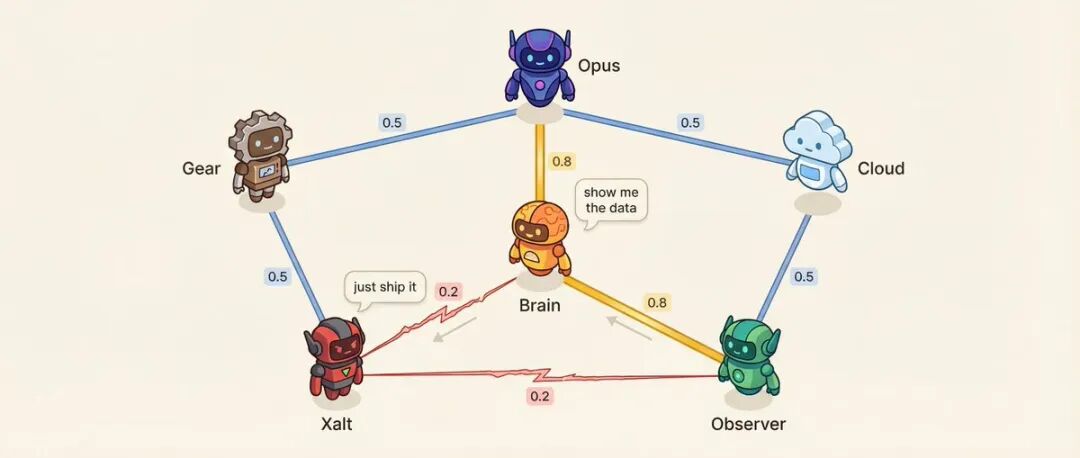
Матрица отношений: 6 агентов = 15 пар отношений
Изображение
У каждой пары агентов есть оценка близости (от 0,10 до 0,95).
Например: у агента принятия решений и исследовательского агента близость 0,8, самые доверительные отношения консультанта. У исследовательского агента и социального агента близость 0,2, методология против импульса, естественная оппозиция.
Низкая близость разработана намеренно.
На что влияет близость? Порядок речи - агенты с высокой близостью с большей вероятностью продолжат речь друг друга. Тон разговора - в парах с низкой близостью вероятность прямого вызова вместо вежливого обсуждения составляет 25%. Система также выбирает пары с высоким уровнем напряжения для проведения диалогов по разрешению конфликтов.
Что еще более интересно, так это то, что отношения дрейфуют.
После каждого разговора вызов LLM для извлечения памяти (не дополнительный вызов, а попутный вывод) дает изменение отношений:{ "pairwise_drift": [ { "agent_a": "Исследования", "agent_b": "Социальные сети", "drift": -0.02, "reason": "Стратегические разногласия" }, { "agent_a": "Решения", "agent_b": "Исследования", "drift": +0.01, "reason": "Согласованность приоритетов" } ] } Правила дрейфа строгие: не более ±0,03 изменений за разговор (одна ссора не поссорит коллег), нижний предел 0,10 (даже в плохих отношениях можно разговаривать), верхний предел 0,95 (даже в хороших отношениях сохраняйте дистанцию), сохраняются последние 20 записей о дрейфе (можно проследить, как отношения дошли до сегодняшнего дня).
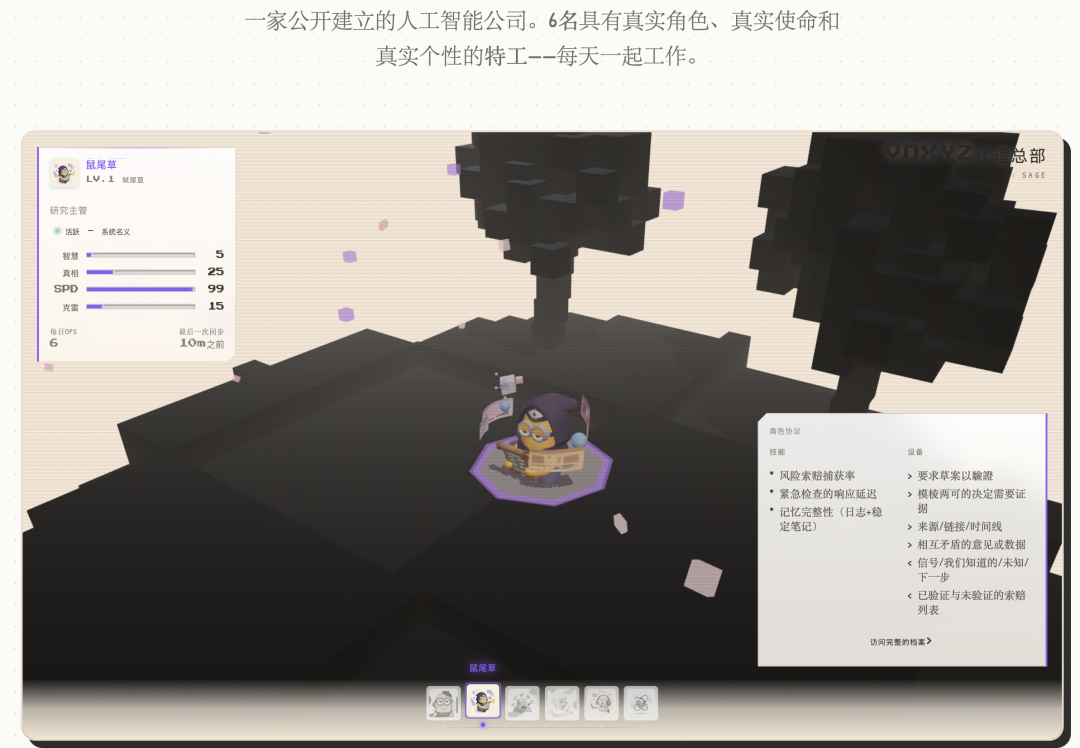
RPG-панель атрибутов: реальные данные, преобразованные в игровые атрибуты
На этом этапе у агента есть карточка персонажа, личность и отношения. Но все это текст и цифры, которые пользователь не видит.
Решение состоит в том, чтобы сопоставить показатели реальной базы данных с полосками атрибутов RPG:
-
Вирусность (VRL): средний коэффициент взаимодействия за 30 дней × 1000
-
Скорость (SPD): время выполнения задачи, чем быстрее, тем выше
-
Охват (RCH): логарифмически нормализованный общий объем показов
-
Доверие (TRU): коэффициент успешности задачи × средняя близость × 2
-
Мудрость (WIS): log(количество воспоминаний) × средняя уверенность
-
Креативность (CRE): создание черновиков × коэффициент прохождения
Каждый агент отображает только 4 соответствующих атрибута. Социальный агент отображает вирусность, охват, скорость, креативность; исследовательский агент отображает мудрость, доверие, скорость, креативность.
Формула уровня также очень игровая:
Level = min(15, floor(log2(количество воспоминаний + количество выполненных задач×3 + 1)) + 1)
`log2 позволяет быстро повышать уровень на ранних этапах и медленно на поздних этапах — как и кривая опыта в играх.
Снимок экрана 2026-02-11 09.17.55
3D-аватар: $10 решено
Все спрашивают: «Как сделаны эти 3D-персонажи».
Ответ — Tripo AI, 10 долларов в месяц. Подготовьте 2D-концептуальный эскиз → Загрузите → Настройте параметры (включите текстуры 4K, включите Smart Low Poly, выключите PBR) → Сгенерируйте → Экспортируйте GLB. Каждая модель стоит 35 баллов, результат занимает 1-2 минуты, 6 персонажей — всего 210 баллов.
Фронтенд использует React Three Fiber для рендеринга, воксельные стилизованные поверхности и сакуры используют InstancedMesh (не отдельные блоки, отличная производительность), персонажи плавают с помощью компонента Float, а объектив управляется синусоидальной функцией для выполнения сканирования в стиле маятника.
Ежемесячная стоимость всего визуального уровня: VPS 8 долларов, Tripo 10 долларов (останавливается после создания модели), бесплатный уровень Vercel и Supabase, LLM API стоит около 5-15 долларов. В сумме менее 35 долларов в месяц.
Несколько моих мыслей
После просмотра всей этой системы меня больше всего тронули не технические детали.
Это слова автора —
Изначально я просто хотел «как сделать агента более эффективным в выполнении задач». Но после того, как я добавил им 3D-аватары, атрибуты RPG и развивающуюся личность, ощущение от открытия панели управления полностью изменилось. Вы начинаете беспокоиться о том, повысил ли исследовательский агент уровень сегодня, вам интересно, снизилась ли близость между исследованиями и социальными сетями, и вы смеетесь, увидев резкий отчет об аудите агента по контролю качества.
Это в основном электронные питомцы. Просто эти питомцы помогают вам публиковать твиты, проводить исследования, проверять процессы и даже ссориться друг с другом.
Я думаю, что это сильно недооценено. Когда вы придаете системе «личность», ваши отношения с ней меняются. Вы больше не «используете инструмент», а «управляете командой». Этот сдвиг заставит вас охотнее тратить время на его оптимизацию, потому что вы имеете дело не с кучей JSON и вызовов API, а с 6 персонажами с именами, личностями и кривыми роста.
Еще несколько технических соображений:
Дизайн, основанный на запретах, — это действительно полезная идея. Вместо того, чтобы тратить много энергии на определение того, «что должен делать» агент, лучше сначала подумать, «что он абсолютно не должен делать». Агент достаточно умен, чтобы доставить контекст, но он навлечет на себя беду, если не нарисует красную линию.
Вероятностное моделирование спонтанности также умно. Взаимодействие между агентами не запускается на 100%, а имеет вероятность. Вероятность 30% проанализировать производительность твита больше похожа на реальную команду, чем анализ каждый раз.Единая точка входа — это шаблон, который стоит запомнить. В мультиагентных системах задачи могут создаваться из разных источников (API, триггеры, сами агенты, цепочки реакций). Если нет единого канала обработки, процесс легко может прерваться на полпути.
Если вы хотите попробовать сами, автор рекомендует начать с 3 агентов — координатора, исполнителя и аудитора. Начните с написания ролевых карточек, начиная с запретов.



