Allt är en fil: Designfilosofin från Unix till AI Agent
Allt är en fil: Designfilosofin från Unix till AI Agent
Original Ethan 业成


Ett eko över ett halvt sekel
Redan i början av 1970-talet på Bell Labs lade Unix-fadern Ken Thompson och Dennis Ritchie för första gången fram en djärv, nästan fanatisk designprincip: Everything is a file – Allt är en fil.
Mer än femtio år senare exploderar AI Agent-ramverk. Manus, Claude Code, OpenClaw... De kommer från olika team, olika teknikstackar, olika kommersiella mål, men de har enhälligt gjort samma val: att använda filsystemet som agentens kognitiva skelett.
Manus ger agenten en virtuell maskin, och uppgifternas resultat sparas som filer. Claude Code läser och skriver direkt på användarens lokala filsystem och använder en CLAUDE.md-fil för att lagra alla instruktioner och kontext. OpenClaw och andra ramverk med öppen källkod organiserar också uppgiftsdekomponering och mellanstadier i en katalogstruktur.
När ingenjörer med ett halvt sekel emellan, inför helt olika tekniska problem, oberoende konvergerar till samma lösning – det är ingen slump, det är en resonans av designfilosofi.
Unix beslut
För att förstå vikten av detta måste vi först gå tillbaka till vad Unix gjorde.
Unix filsystemdesign är allmänt erkänd som en av de mest eleganta designerna i datavetenskapens historia. Det löste ett extremt komplext problem: hur man hanterar olika hårdvaruresurser och dataresurser med ett enhetligt och enkelt gränssnitt.
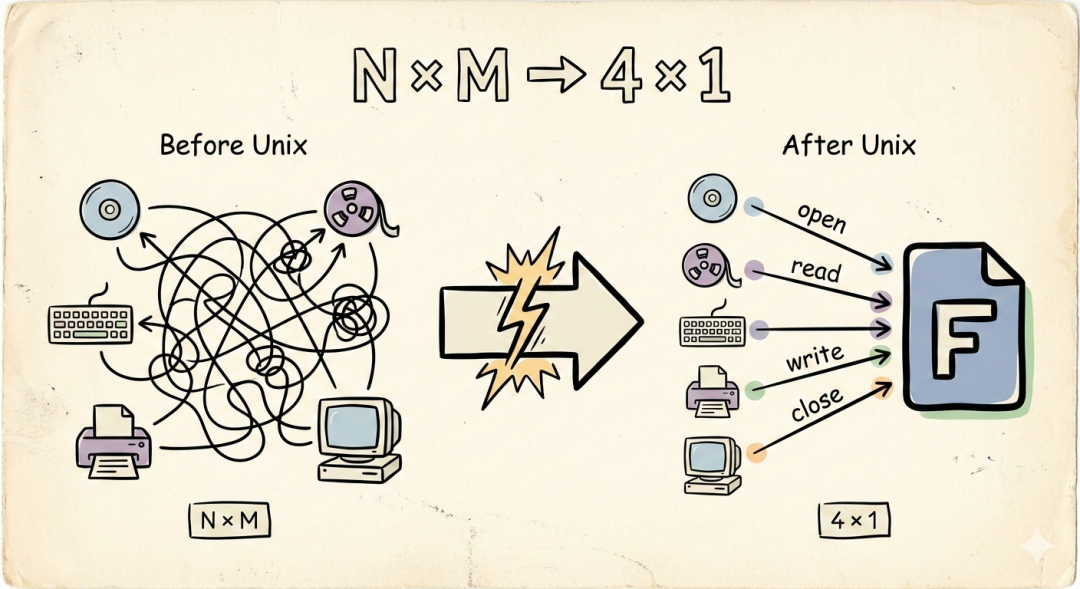
Före 1970-talet fungerade operativsystem så här: Om du ville läsa en disk, justerade du diskgränssnittet; om du ville läsa ett magnetband, justerade du magnetbandsgränssnittet; om du ville komma åt en terminal, justerade du terminalgränssnittet. Varje enhet hade sitt eget API, och varje API hade sin egen semantik. Om du hade N typer av enheter och M typer av operationer var systemkomplexiteten N × M.
Thompson och Ritchie gjorde något som verkade så enkelt att det var dumt:
Gör allt till filer. Använd de fyra verben open, read, write, close för att hantera allt.
Dess kärnbetydelse är: alla resurser i operativsystemet – dokument, kataloger, hårddiskar, modem, tangentbord, skrivare, till och med nätverksanslutningar och processinformation – kan abstraheras till en filström (Stream of Bytes).
Detta innebär att du bara behöver lära dig en uppsättning API:er – open(), read(), write(), close() – för att hantera alla datorns resurser.
Härefter kollapsade komplexiteten från N × M till 4 × 1. Fyra verb, ett abstraktionslager.
Det geniala med detta ligger inte i substantivet "fil", utan i en djupare insikt:
Du behöver inte veta vad som finns bakom fildeskriptorn. Gränssnittet är kontraktet.
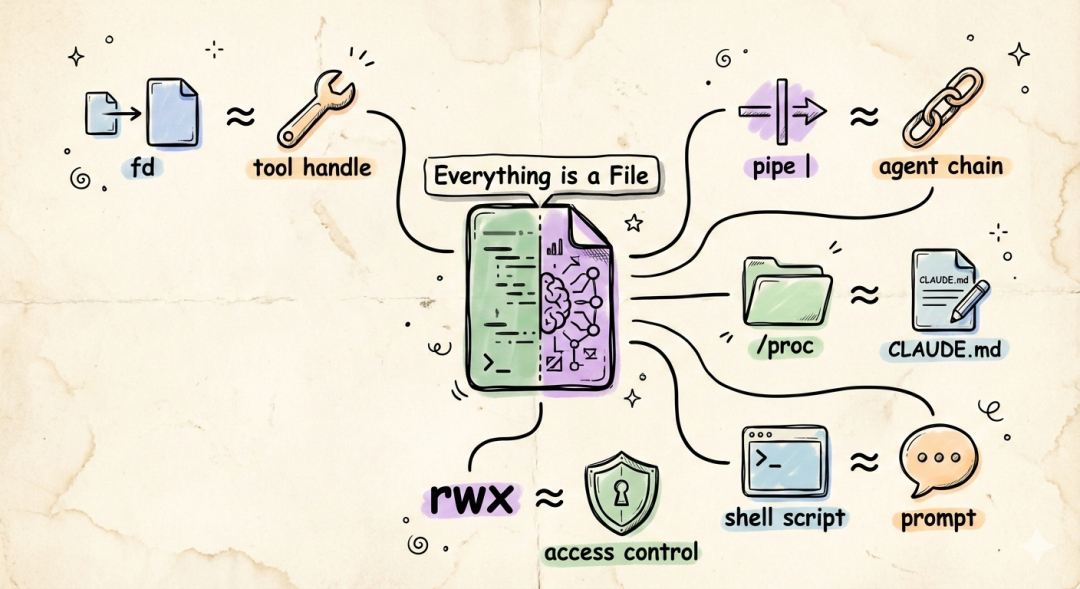
En fd (fildeskriptor) är ett ogenomskinligt handtag. Du read() den, och en ström av bytes kommer ut. Om dessa bytes kommer från en hårddisksektor, en nätverkskortsbuffert eller en annan process standardutgång – du bryr dig inte, och du borde inte bry dig.
Det är kraften i ett enhetligt gränssnitt: det gör okunnighet till en fördel.
Samma fråga som Agent står inför
Låt oss nu se på AI Agents situation.
För att slutföra komplexa uppgifter står en agent inför ett häpnadsväckande liknande dilemma som operativsystemet på 1970-talet:
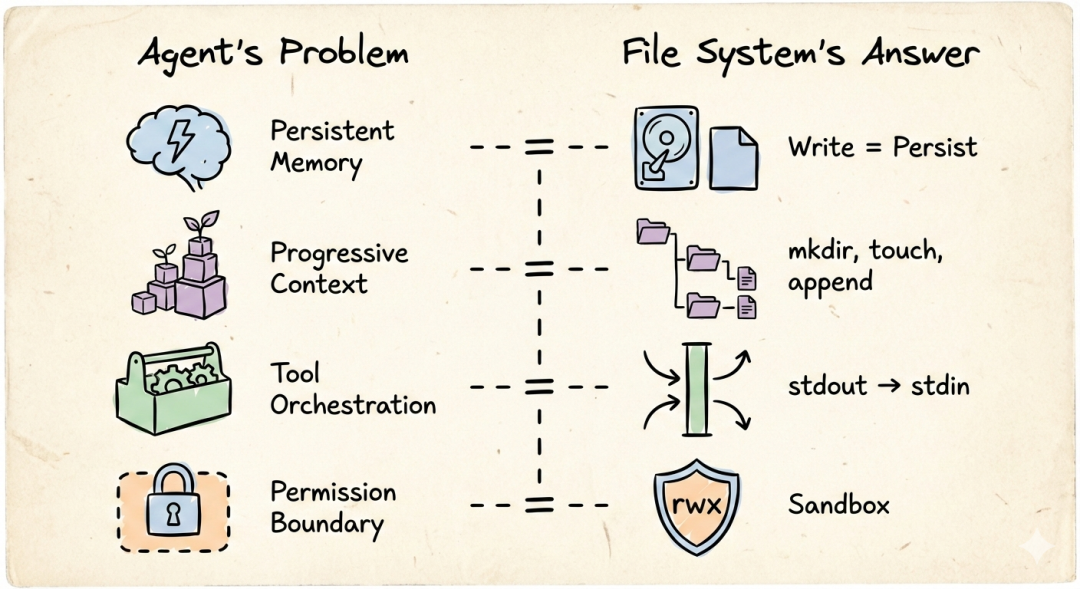
- Persistent minne: LLM:s kontextfönster är flyktigt, och tankekedjan försvinner med sessionen. Precis som minnet återvinns när en process avslutas – du behöver en plats för att persistent lagra mellanstadier, annars börjar varje konversation från noll.
- Gradvis kontext: Komplexa uppgifter kan inte slutföras i ett steg. Agenten behöver gradvis ackumulera kontext i flera resonemangsomgångar, precis som en Unix-process överför tillstånd mellan flera körningar genom att läsa och skriva filer. Filsystemet erbjuder naturligt detta "skriv lite, läs lite, skriv lite igen" gradvisa arbetsläge.
- Samordning av verktyg och färdigheter: Agenten måste anropa heterogena verktyg (Tools/Skills) som sökning, kodexekvering och bildgenerering, precis som Unix måste hantera heterogena enheter som diskar, nätverk och skrivare. Du behöver ett enhetligt abstraktionslager, annars måste du skriva en ny integrationslogik för varje nytt verktyg.
- Behörighetsgränser för datoranvändning: När agenten har förmågan att använda datorn blir frågan om "vad den får röra och vad den inte får röra" en fråga om liv och död. Unix filbehörighetssystem (rwx) tillhandahåller en färdig sandlådemodell – katalogen är gränsen, behörigheten är avtalet.
Fyra behov. Låter det bekant?
Det är precis de problem som operativsystemet stod inför på 1970-talet.
Persistent minne – filsystemet löser det naturligt, skrivning är persistent. Gradvis kontext – katalogstrukturen i sig är inkrementellt konstruerad, mkdir, touch, append, kontexten växer med filen. Enhetlig samordning av verktyg – kärnan i Unix-pipelinen: en process stdout är en annan process stdin, mellanmediet är en byteström. Agentens verktygskedja är också så: utdatafilen från föregående steg är indata till nästa steg. Behörighetsgränser – filsystemets rwx-behörigheter, chroot-sandlåda, definierar naturligt agentens "förmågekrets".
Så när designern av Agent-ramverket står inför frågan "var ska agentens arbetsstatus placeras", är svaret nästan förutbestämt: i filsystemet. Eftersom det inte finns någon enklare lösning som kan uppfylla alla fyra begränsningarna samtidigt.
 När systemet behöver "hantera interaktionen mellan ett stort antal heterogena resurser" har du två vägar:
När systemet behöver "hantera interaktionen mellan ett stort antal heterogena resurser" har du två vägar:
Rutt A: Designa ett dedikerat gränssnitt för varje resurs. N antal resurser × M antal operationer = NM antal gränssnitt. Exakt men explosivt.
Rutt B: Hitta ett tillräckligt tunt abstraktionslager så att alla resurser bär samma kläder. 4 antal operationer × 1 abstraktionslager. Grovt men kombinerbart.
Unix valde B. Mer än femtio år senare valde Agent-ramverket återigen B.
Ett djupare lager: Filen är en externalisering av tänkande
Men om vi bara stannar vid "konvergensen av tekniska lösningar" missar vi något mer väsentligt.
Tänk på hur människor själva hanterar komplexa uppgifter.
Du får ett stort projekt, det första du gör är inte att börja arbeta, utan: skapa mappar. Projektrotkatalog, underuppgiftskatalog, referensmaterialkatalog, utdatakatalog. Du använder katalogstrukturen för att bryta ner den kaotiska uppgiften i hanterbara enheter. Du använder filnamn för att namnge varje enhet. Du använder filinnehåll för att registrera tankeprocessen och mellanprodukter.
Filsystemet är inte bara en lagringslösning. Det är det ursprungliga verktyget för människor att externalisera tänkande.
Denna insikt förklarar varför Agent-ramverket konvergerar till filsystemet: LLM:s "tänkande" måste externaliseras – dess kontextfönster är begränsat, och långdistansresonemang måste förlita sig på externt minne. Och filsystemet är just det mest universella "externa minnes"-formatet som människan har uppfunnit.
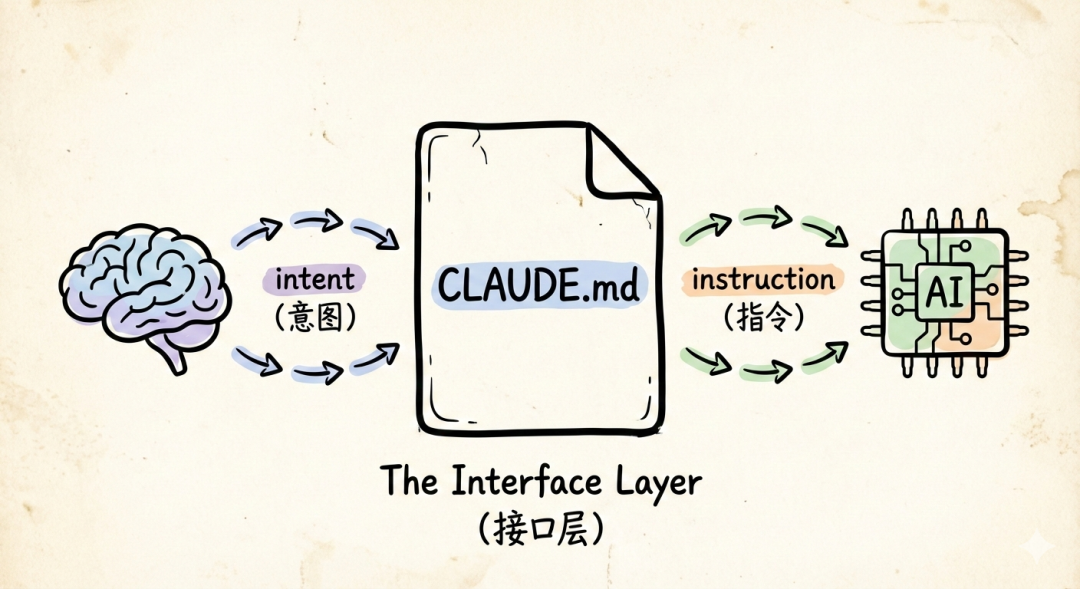
Ur detta perspektiv är CLAUDE.md i Claude Code inte en konfigurationsfil. Det är ett externaliserat kognitivt avtal – människor skriver avsikten till en fil, och agenten läser filen som en avsikt. Filen blir ett gränssnittslager mellan det mänskliga sinnet och artificiell intelligens.
 Detta är slående konsekvent med Unix-pipelinens filosofi:
Detta är slående konsekvent med Unix-pipelinens filosofi:
Skriv program för att hantera textströmmar, eftersom det är ett universellt gränssnitt.Att byta ut "programs" mot "agents" och "text streams" mot "files", det påståendet kommer fortfarande att vara sant år 2026.
Återgå till första principer
Stora abstraktioner blir inte föråldrade, de hittar bara nya instanser i nya domäner.
"Enhetliga gränssnitt löser komplexitet" är inte en uppfinning av Unix, det är en evig lag inom systemdesign. Unix råkade implementera det med namnet "fil". AI Agent råkade implementera det igen i form av en "arbetskatalog".
Nästa generations system kommer också att ställas inför samma val: att designa dedikerade gränssnitt för varje sak, eller att hitta ett tunt, generellt, komponerbart abstraktionslager?
Om historien har lärt oss något, så står svaret redan skrivet bredvid /dev/null:
Keep it simple. Make it compose. Everything is a file. (Håll det enkelt. Gör det komponerbart. Allt är en fil.)



