Github Millor del Dia: Desenvolupa un Agent d'IA de Veu en Temps Real, una Caixa d'Eines Universal
Github Millor del Dia: Desenvolupa un Agent d'IA de Veu en Temps Real, una Caixa d'Eines Universal
Heu tingut mai la sensació que, tot i voler fer un agent d'IA de veu senzill, us quedeu encallats per diversos problemes, com ara que algú de l'equip domina Python i algú altre C++? Les parts desenvolupades per cadascú causen problemes quan s'ajunten, la configuració de l'entorn pot trigar mig dia i l'expansió de les funcions es torna cada cop més caòtica a mesura que es modifica, fins que al final es perd l'entusiasme.
Avui us presentaré una caixa d'eines de desenvolupament universal molt útil, TEN-Framework.

Adreça de codi obert: https://github.com/TEN-framework/ten-framework
TEN Framework és com si us haguessin empaquetat totes aquestes coses complexes. En realitat, és un framework especialitzat en la construcció d'IA conversacional multimodal en temps real. Podeu imaginar-vos-ho com una línia de producció d'assistents de veu d'IA ja feta. Mòdul de reconeixement de veu, mòdul de model gran, mòdul de síntesi de veu, tot això està preparat per a vosaltres. El que heu de fer és muntar-los segons les vostres necessitats. Això és molt més fàcil que reinventar la roda des de zero.
Pel que fa a què pot fer concretament, primer escolliré algunes coses que em semblen més pràctiques. La primera és un assistent de veu multiús que admet connexions RTC i WebSocket, amb una latència molt baixa i una bona qualitat de so. Tant si voleu fer un servei d'atenció al client intel·ligent com un assistent de veu personal, aquesta funció bàsicament pot satisfer les vostres necessitats. El que és interessant és que també té un generador de gargots, que dibuixa el que dius i genera gargots d'estil dibuixat a mà. Aquesta funció hauria de ser molt popular en escenaris de demostració o entreteniment.

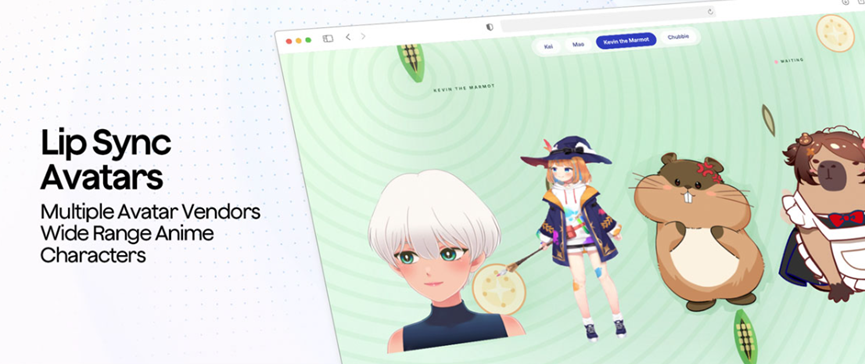
També hi ha solucions corresponents per a escenaris de conversa amb diverses persones. Té una funció de reconeixement de parlant en temps real que pot distingir automàticament qui està parlant, de manera que no us haureu de preocupar de la confusió en els registres de reunions o la transcripció d'entrevistes. Pel que fa a la imatge virtual, quan l'assistent d'IA parla, la forma de la boca del personatge es pot sincronitzar perfectament amb la veu. Tant si es tracta d'un personatge d'anime bidimensional com d'un humà virtual 3D realista, la forma de la boca pot coincidir. Això és molt convenient per als desenvolupadors que fan streamers virtuals o assistents personalitzats.
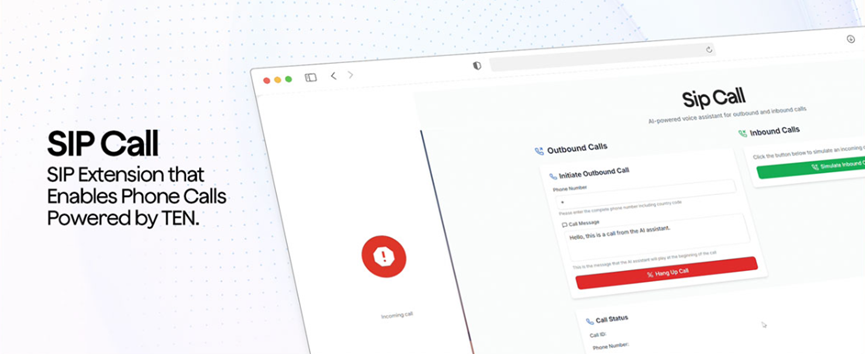
Si voleu que respongui el telèfon, també admet el protocol SIP, i l'assistent d'IA pot respondre directament les trucades telefòniques. Aquesta funció és molt útil per als usuaris empresarials, ja que connecta el servei d'atenció al client intel·ligent amb el sistema telefònic, cosa que pot estalviar molts costos laborals. Per descomptat, també té la funció bàsica de veu a text, que converteix la veu en text en temps real, que es pot utilitzar en escenaris com ara actes de reunions i generació de subtítols.
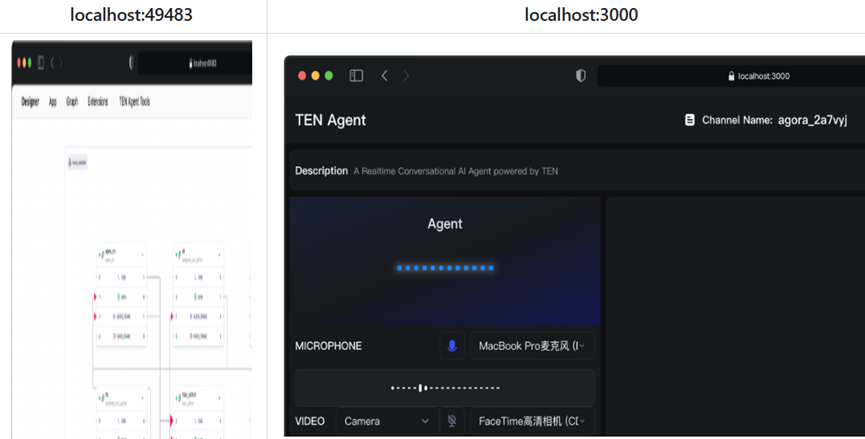
A més dels processos estandarditzats, també té moltes plantilles de projecte ja fetes, tant plantilles d'AI Agent com diverses plantilles d'extensions i aplicacions. Per exemple, plantilles d'extensió LLM, TTS, i també diverses plantilles d'aplicacions per defecte en llenguatges principals, que es poden utilitzar directament. Des de la creació d'un nou projecte fins a l'execució de la primera demostració, només triga uns minuts, cosa que estalvia molt de temps.
Si sou un expert en desenvolupament, també hi ha maneres avançades de jugar, com ara fer un assistent de veu en temps real d'alt rendiment, utilitzar C++ per al processament d'àudio i vídeo en temps real per garantir una baixa latència i utilitzar Python per a la inferència LLM per permetre que l'assistent entengui i pensi. A continuació, utilitzeu Node.js per a la interacció frontal per permetre als usuaris operar fàcilment, i la velocitat de desenvolupament general és més de 3 vegades més ràpida que el desenvolupament tradicional en un sol llenguatge.
O combineu l'extensió de detecció d'activitat de veu VAD de TEN, l'extensió de text a veu TTS i l'extensió LLM per crear un robot de diàleg intel·ligent totalment automàtic. Les extensions es poden connectar perfectament entre si, sense que hàgiu d'escriure vosaltres mateixos un codi d'integració complicat.
Actualment, aquest framework està a punt de superar les 10.000 estrelles. Si esteu interessats, podeu provar-ho.



