Github Codziennie Najlepszy #1: Rozwijaj inteligentnego agenta AI głosowego w czasie rzeczywistym, uniwersalny zestaw narzędzi
Github Codziennie Najlepszy #1: Rozwijaj inteligentnego agenta AI głosowego w czasie rzeczywistym, uniwersalny zestaw narzędzi
Czy kiedykolwiek miałeś takie uczucie, że wyraźnie chcesz stworzyć prostego inteligentnego agenta AI głosowego, ale utknąłeś z powodu różnych problemów, na przykład ktoś w zespole jest dobry w Pythonie, a ktoś inny biegle posługuje się C++. Części opracowane przez każdego z nich powodują problemy po połączeniu, konfiguracja środowiska może trwać pół dnia, a rozszerzanie funkcji staje się coraz bardziej chaotyczne, aż w końcu entuzjazm znika.
Dziś przedstawiam bardzo przydatny, uniwersalny zestaw narzędzi programistycznych TEN-Framework.

Adres open source: https://github.com/TEN-framework/ten-framework
TEN Framework jest jak spakowanie wszystkich tych skomplikowanych rzeczy. W rzeczywistości jest to framework specjalnie zaprojektowany do budowania wielomodowych konwersacyjnych AI w czasie rzeczywistym. Możesz go sobie wyobrazić jako gotową linię produkcyjną asystenta głosowego AI. Moduł rozpoznawania mowy, moduł dużego modelu, moduł syntezy mowy, wszystko to jest dla Ciebie przygotowane. Wszystko, co musisz zrobić, to złożyć je zgodnie z własnymi potrzebami. To o wiele bardziej oszczędza kłopotów niż samodzielne wynajdywanie koła od zera.
Jeśli chodzi o to, co konkretnie może zrobić, najpierw wybiorę kilka, które uważam za bardziej praktyczne. Pierwszym z nich jest wielofunkcyjny asystent głosowy, który obsługuje dwa tryby połączenia: RTC i WebSocket, z niskim opóźnieniem i dobrą jakością dźwięku. Niezależnie od tego, czy chcesz stworzyć inteligentną obsługę klienta, czy osobistego asystenta głosowego, ta funkcja zasadniczo może spełnić Twoje potrzeby. Co ciekawe, ma również generator graffiti, który rysuje to, co mówisz, generując graffiti w stylu ręcznie rysowanym. Ta funkcja powinna być bardzo popularna w demonstracjach lub scenariuszach rozrywkowych.

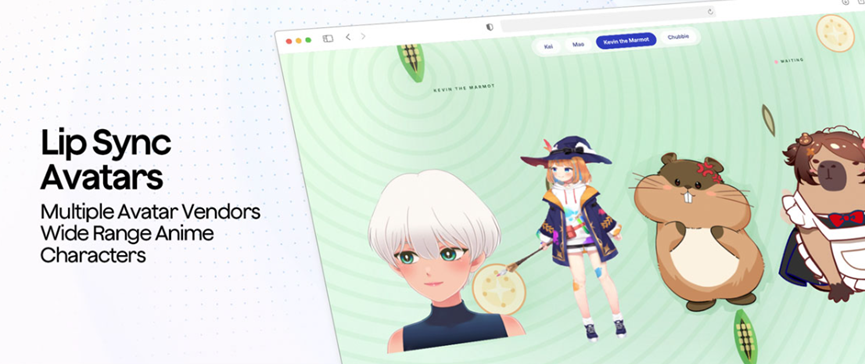
Istnieją również odpowiednie rozwiązania dla scenariuszy rozmów wieloosobowych. Posiada funkcję rozpoznawania mówcy w czasie rzeczywistym, która może automatycznie rozróżniać, kto mówi, dzięki czemu nie musisz się martwić o zamieszanie podczas nagrywania spotkań lub transkrypcji wywiadów. Jeśli chodzi o wirtualny wizerunek, kiedy asystent AI mówi, kształt ust postaci może być idealnie zsynchronizowany z głosem. Niezależnie od tego, czy jest to postać z anime 2D, czy realistyczny wirtualny człowiek 3D, kształt ust można dopasować. Jest to bardzo wygodne dla programistów, którzy tworzą wirtualnych streamerów lub spersonalizowanych asystentów.
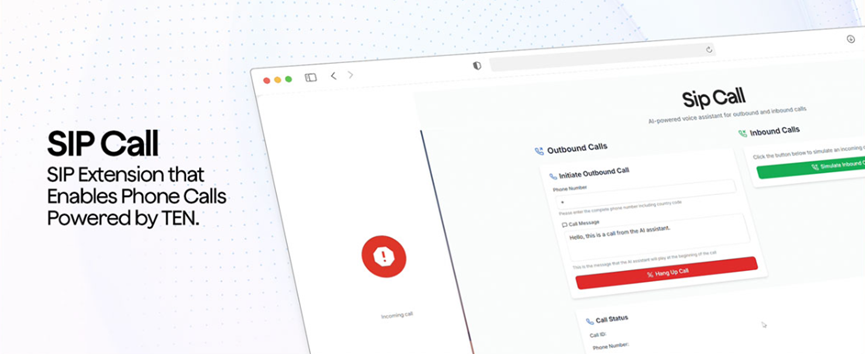
Jeśli chcesz, aby odbierał telefony, obsługuje również protokół SIP, a asystent AI może bezpośrednio odbierać telefony. Ta funkcja jest bardzo praktyczna dla użytkowników korporacyjnych. Połączenie inteligentnej obsługi klienta z systemem telefonicznym może zaoszczędzić wiele kosztów pracy. Oczywiście ma również podstawową funkcję zamiany mowy na tekst, która może przekształcać mowę w tekst w czasie rzeczywistym, co może być używane w scenariuszach takich jak protokoły spotkań i generowanie napisów.
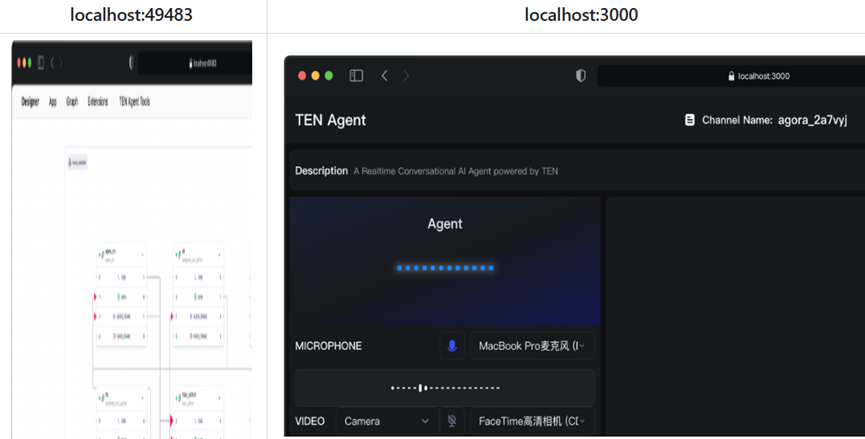
Oprócz standardowych procesów, ma również wbudowanych wiele gotowych szablonów projektów, niezależnie od tego, czy są to szablony AI Agent, czy różne szablony rozszerzeń i aplikacji. Na przykład szablony rozszerzeń LLM i TTS, a także domyślne szablony aplikacji w kilku popularnych językach, mogą być używane bezpośrednio. Od utworzenia nowego projektu do uruchomienia pierwszej wersji demonstracyjnej zajmuje tylko kilka minut, co oszczędza dużo czasu.
Jeśli jesteś doświadczonym programistą, istnieją również zaawansowane sposoby gry, na przykład możesz stworzyć wysokowydajnego asystenta głosowego w czasie rzeczywistym, użyć C++ do przetwarzania audio i wideo w czasie rzeczywistym, aby zapewnić niskie opóźnienia, użyć Pythona do wnioskowania LLM, aby asystent mógł słuchać i myśleć. Następnie użyj Node.js do interakcji front-end, aby użytkownicy mogli łatwo obsługiwać, a cała prędkość rozwoju jest ponad 3 razy szybsza niż w przypadku tradycyjnego rozwoju w jednym języku.
Lub połącz rozszerzenie wykrywania aktywności głosowej VAD TEN, rozszerzenie zamiany tekstu na mowę TTS i rozszerzenie LLM, aby zbudować w pełni automatycznego inteligentnego robota do rozmów. Rozszerzenia mogą bezproblemowo łączyć się ze sobą, bez konieczności pisania żmudnego kodu integracyjnego.
Obecnie framework wkrótce przekroczy 10000 gwiazdek, jeśli jesteś zainteresowany, możesz spróbować.



