گٹ ہب پر روزانہ کی بہترین پہلی پوزیشن: ریئل ٹائم وائس اے آئی ایجنٹ تیار کریں، ایک ہمہ گیر ٹول باکس
گٹ ہب پر روزانہ کی بہترین پہلی پوزیشن: ریئل ٹائم وائس اے آئی ایجنٹ تیار کریں، ایک ہمہ گیر ٹول باکس
کیا آپ نے کبھی ایسا محسوس کیا ہے کہ آپ ایک سادہ سا وائس اے آئی ایجنٹ بنانا چاہتے ہیں، لیکن مختلف مسائل میں پھنس جاتے ہیں، جیسے کہ آپ کی ٹیم میں کچھ لوگ Python میں ماہر ہیں اور کچھ C++ میں۔ جب ان کے تیار کردہ حصے ایک ساتھ جوڑے جاتے ہیں تو مسائل پیدا ہوتے ہیں، ماحول کی ترتیب میں آدھا دن لگ جاتا ہے، اور توسیع شدہ افعال میں مزید تبدیلیاں کی جاتی ہیں، یہاں تک کہ جوش و خروش بھی ختم ہو جاتا ہے۔
آج میں آپ کو ایک انتہائی مفید ہمہ گیر ڈویلپمنٹ ٹول باکس TEN-Framework سے متعارف کرواؤں گا۔

اوپن سورس ایڈریس: https://github.com/TEN-framework/ten-framework
TEN Framework ایسا ہی ہے جیسے ان تمام پیچیدہ چیزوں کو آپ کے لیے پیک کر دیا گیا ہو۔ یہ دراصل ایک ایسا فریم ورک ہے جو خاص طور پر ریئل ٹائم ملٹی موڈل مکالماتی اے آئی کی تعمیر کے لیے استعمال ہوتا ہے۔ آپ اسے اے آئی وائس اسسٹنٹ کی ایک تیار شدہ پروڈکشن لائن کے طور پر تصور کر سکتے ہیں۔ وائس ریکگنیشن ماڈیول، بڑا ماڈل ماڈیول، اور وائس سنتھیسز ماڈیول، یہ سب آپ کے لیے تیار ہیں۔ آپ کو صرف اپنی ضروریات کے مطابق ان کو جمع کرنا ہے۔ یہ شروع سے پہیہ ایجاد کرنے سے کہیں زیادہ آسان ہے۔
جہاں تک اس بات کا تعلق ہے کہ یہ خاص طور پر کیا کر سکتا ہے، میں پہلے ان چند چیزوں کا انتخاب کروں گا جو مجھے زیادہ عملی لگتی ہیں۔ پہلی چیز کثیر مقصدی وائس اسسٹنٹ ہے، جو RTC اور WebSocket دونوں کنکشن طریقوں کو سپورٹ کرتا ہے، جس میں تاخیر بہت کم ہے اور آواز کا معیار بھی اچھا ہے۔ چاہے آپ سمارٹ کسٹمر سروس بنانا چاہتے ہوں یا ذاتی وائس اسسٹنٹ، یہ فنکشن بنیادی طور پر آپ کی ضروریات کو پورا کر سکتا ہے۔ دلچسپ بات یہ ہے کہ اس میں ایک ڈوڈل جنریٹر بھی ہے، آپ جو کہتے ہیں وہ اسے ڈرا کرتا ہے، اور اس طرح کے ہاتھ سے تیار کردہ ڈوڈلز تیار کرتا ہے۔ یہ فنکشن ڈیمو یا تفریحی منظرناموں میں بہت مقبول ہونا چاہیے۔

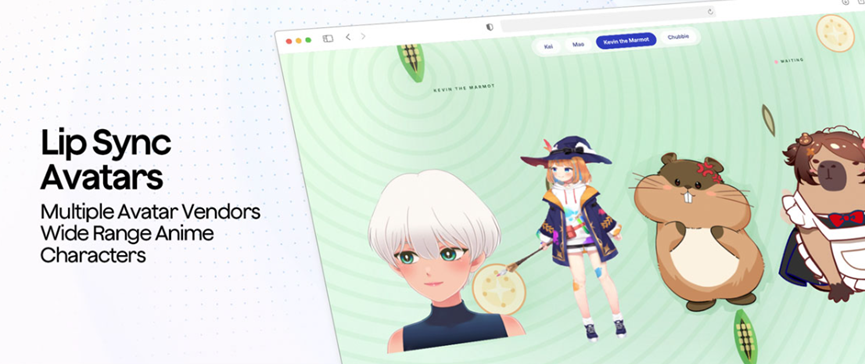
متعدد افراد کے مکالمے کے منظرناموں کے لیے بھی متعلقہ حل موجود ہیں۔ اس میں ریئل ٹائم اسپیکر ریکگنیشن فنکشن ہے، جو خود بخود یہ تمیز کر سکتا ہے کہ کون بول رہا ہے، تاکہ میٹنگ کے ریکارڈ یا انٹرویو کی نقل کے دوران الجھن کے بارے میں فکر کرنے کی ضرورت نہ ہو۔ ورچوئل امیج کے حصے میں، جب اے آئی اسسٹنٹ بولتا ہے، تو کردار کے منہ کی شکل آواز کے ساتھ بالکل مطابقت پذیر ہو سکتی ہے۔ چاہے یہ دو جہتی اینیمی کردار ہو یا ایک حقیقت پسندانہ تھری ڈی ورچوئل شخص، منہ کی شکل درست ہو سکتی ہے۔ یہ ورچوئل براڈکاسٹر یا ذاتی معاون بنانے والے ڈویلپرز کے لیے بہت آسان ہے۔
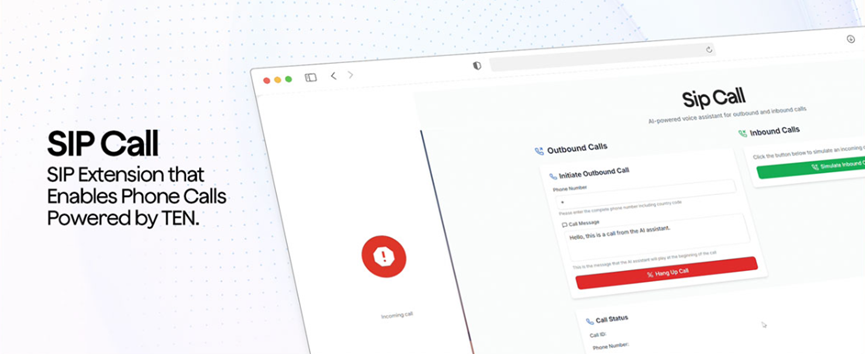
اگر آپ چاہتے ہیں کہ یہ فون کالز وصول کرے، تو یہ SIP پروٹوکول کو بھی سپورٹ کرتا ہے، اور اے آئی اسسٹنٹ براہ راست فون کالز وصول کر سکتا ہے۔ یہ فنکشن کاروباری صارفین کے لیے بہت عملی ہے۔ سمارٹ کسٹمر سروس کو فون سسٹم سے جوڑنے سے بہت زیادہ افرادی قوت کی لاگت بچ سکتی ہے۔ یقیناً، اس میں بنیادی وائس ٹو ٹیکسٹ فنکشن بھی ہے، جو ریئل ٹائم میں آواز کو متن میں تبدیل کرتا ہے، اور میٹنگ کے خلاصے اور سب ٹائٹلز کی تخلیق جیسے منظرناموں میں استعمال کیا جا سکتا ہے۔
معیاری عمل کے علاوہ، اس میں بہت سے تیار شدہ پروجیکٹ ٹیمپلیٹس بھی ہیں، چاہے وہ اے آئی ایجنٹ کے ٹیمپلیٹس ہوں یا مختلف توسیعوں اور ایپلی کیشنز کے ٹیمپلیٹس۔ مثال کے طور پر، LLM اور TTS توسیع ٹیمپلیٹس، اور کئی اہم زبانوں میں ڈیفالٹ ایپلیکیشن ٹیمپلیٹس، سبھی براہ راست استعمال کیے جا سکتے ہیں۔ ایک نیا پروجیکٹ بنانے سے لے کر پہلے ڈیمو کو چلانے تک، اس میں صرف چند منٹ لگتے ہیں، جو بہت وقت بچاتا ہے۔
اگر آپ ایک تجربہ کار ڈویلپر ہیں، تو یہاں ترقی یافتہ گیم پلے بھی ہے، جیسے کہ ایک اعلیٰ کارکردگی والا ریئل ٹائم وائس اسسٹنٹ بنانا، ریئل ٹائم آڈیو اور ویڈیو پروسیسنگ کے لیے C++ کا استعمال کرنا، کم تاخیر کو یقینی بنانا، اور LLM استدلال کے لیے Python کا استعمال کرنا، تاکہ اسسٹنٹ سمجھ سکے اور سوچ سکے۔ پھر فرنٹ اینڈ انٹریکشن کے لیے Node.js کا استعمال کریں، تاکہ صارفین آسانی سے کام کر سکیں، اور پوری ترقی کی رفتار روایتی سنگل لینگویج ڈویلپمنٹ سے 3 گنا زیادہ تیز ہے۔
یا TEN کے VAD وائس ایکٹیویٹی ڈیٹیکشن ایکسٹینشن، TTS ٹیکسٹ ٹو وائس ایکسٹینشن، اور LLM ایکسٹینشن کو یکجا کریں، اور آپ ایک مکمل طور پر خودکار ذہین مکالماتی روبوٹ بنا سکتے ہیں، اور توسیع کے درمیان بغیر کسی رکاوٹ کے رابطہ قائم کیا جا سکتا ہے، آپ کو خود پیچیدہ انٹیگریشن کوڈ لکھنے کی ضرورت نہیں ہے۔
فی الحال، یہ فریم ورک جلد ہی 10000 ستاروں کو عبور کر جائے گا، اگر آپ دلچسپی رکھتے ہیں تو آپ اسے آزما سکتے ہیں۔



