Avaluació de MiniMax M2.5 de Shiyu
Avaluació de MiniMax M2.5 de Shiyu
Conclusió breu: Arrelar cap avall, créixer cap amunt
Situació bàsica
L'anterior M2.1 de Shiyu, a causa de problemes tècnics, tot i que va mostrar un progrés significatiu en la programació, la seva capacitat lògica va quedar per darrere de la M2. Afortunadament, la M2.5 bàsicament ha resolt els problemes tècnics i la seva capacitat ha tornat a la normalitat. En comparació amb la M2, el progrés de la M2.5 és d'aproximadament el 17%.
No obstant això, part del progrés s'aconsegueix mitjançant cadenes de pensament més llargues i una exploració més profunda de l'espai de solucions. El consum mitjà de tokens de la M2.5 es troba entre els 6 més alts de tots els models provats, gairebé el doble que el del seu competidor Sonnet. Afortunadament, la potència de càlcul de Shiyu està garantida i el cost no és elevat. Tot i que la programació no pot substituir Sonnet sense cap punt feble, és completament útil per a l'ús diari. La M2.5 finalment ha aconseguit l'objectiu que la M2.1 volia assolir.
Resultats lògics
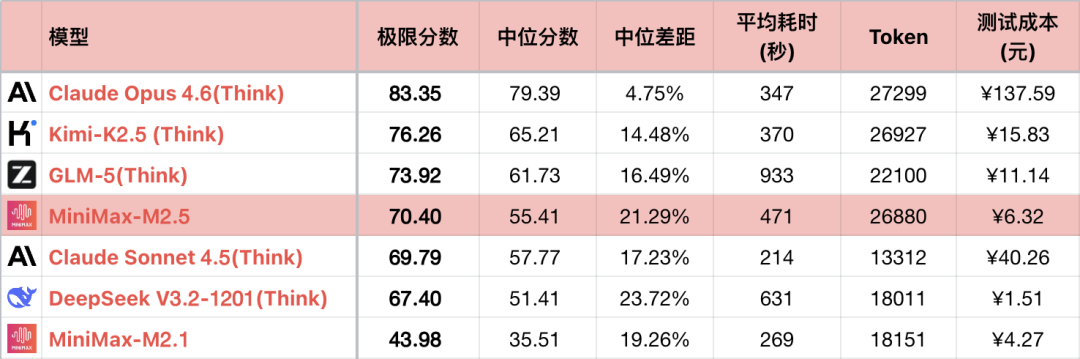
*1 Per tal de destacar la relació de comparació, la taula només mostra una part dels models comparables, no una classificació completa.
*2 Per a les preguntes i el mètode de prova, consulteu: Avaluació comparativa de la capacitat lògica del model de llenguatge gran - Llista mensual de gener de 2026. S'ha afegit la pregunta #56.
*3 La llista completa s'actualitza a https://llm2014.github.io/llm_benchmark/
*4 El vermell és limitat durant el Festival de Primavera, que representa la felicitat i no té cap altre significat.
Com que la M2.1 és una versió amb un error i una capacitat lògica anormalment baixa, el text següent només farà una comparació intergeneracional entre la M2 i la M2.5.
Millores
- Raonament estable: La M2.5 pot mantenir les restriccions inicials i els detalls del context durant un procés de raonament més llarg, de manera que la M2.5 obté una puntuació significativament més alta en alguns problemes que no són gaire difícils, però que requereixen "concentració". Per exemple, en el #4 Cub de Rubik, la M2.5 és el vuitè model del món que obté la màxima puntuació. Però en aquest tipus de problemes, les tres grans empreses nord-americanes poden obtenir la màxima puntuació de manera estable, mentre que la M2.5 només pot encertar-ho amb una petita probabilitat, la diferència és òbvia.
- Programació: Com s'ha dit anteriorment, la M2.5 no pot substituir Sonnet en tots els aspectes, principalment a causa de la quantitat de coneixement de programació. En situacions que requereixen experiència, habilitats, diferències d'API de versions, etc., la M2.5 difícilment pot trobar problemes per si sola sense indicacions, i normalment necessita diverses rondes per reduir gradualment el problema. Però això ja és un gran progrés respecte a la M2. En les proves d'enginyeria C, la majoria dels models nacionals es quedaran encallats a les dues primeres rondes, mentre que la M2.5 s'ha convertit en el primer model nacional que arriba a la vuitena ronda. Tot i que la M2.5 té mancances evidents en l'ús d'OpenGL i la imaginació espacial, amb la capacitat d'Agent optimitzada, pot provar i equivocar-se contínuament, convergint a la solució correcta. A més, val la pena assenyalar que la M2.5 "parla" menys quan treballa en programació, i gairebé només emet un breu resum després d'haver completat finalment la feina, sense emetre idees a mig camí. Altres projectes d'enginyeria encara s'estan provant i s'actualitzaran posteriorment.
- Capacitat de càlcul: La capacitat de càlcul de la M2 no és excel·lent, i la M2.1 és encara pitjor. La M2.5 ha fet millores efectives a partir d'un punt de partida baix. En la majoria de càlculs senzills, la M2.5 té una petita probabilitat d'alta precisió, però en la majoria dels casos encara hi ha errors de càlcul, grans errors i problemes per entendre les fórmules. L'entrenament en aquest aspecte encara és insuficient. Com a model impulsat per Agent, la capacitat de càlcul no és una necessitat bàsica, i el càlcul de la sèrie Claude també s'ha quedat enrere durant molt de temps.
Deficiències
- Seguiment d'instruccions: En comparació amb la M2, la millora en el seguiment d'instruccions no és gran. La probabilitat d'obtenir la màxima puntuació en alguns problemes senzills és més alta, però tampoc és estable. Hi ha casos d'abandonament aleatori d'instruccions o de manipulació d'instruccions, però observant el contingut de la cadena de pensament, el model ha notat totes les instruccions, i finalment hi ha un problema amb la sortida. El rendiment general està per darrere d'altres models de la primera línia. En la programació, també hi ha casos en què s'ignoren els requisits de codificació i les normes del projecte. Per exemple, en el projecte C, s'especifica que l'eix Z de les coordenades apunta cap amunt, però la M2.5 el canvia sense autorització a l'eix Y per tal de solucionar un altre error. Cal prestar atenció addicional al control en l'ús diari.
- Al·lucinacions: El nivell d'al·lucinacions de la M2.5 no ha canviat significativament respecte a la M2. En la majoria de problemes relacionats amb el context, les dues tenen la mateixa puntuació límit. Fins i tot en el problema de càlcul del nombre objectiu #43, la M2.5 comet errors de baix nivell com ara l'ús repetit de números i l'omissió de números que només apareixen en els models de segona línia.
L'historiador cibernètic diu
Els fabricants nacionals han passat més de mig any explorant com s'ha de fer exactament un model de programació. La primera fornada de models que es deien substituts de Sonnet només semblaven propers en l'efecte de generació d'"una frase". La seva organització interna del codi, l'enginyeria i, el que és més important, la capacitat d'iteració multironda estan molt per darrere. Això també fa que els programadors nacionals desconfiïn generalment dels models nacionals i prefereixin utilitzar Claude, fins i tot arriscant-se a ser bloquejats.
I amb MiniMax M2 i M2.1 que van revertir inicialment l'opinió pública, aquesta generació de M2.5 ha avançat un gran pas en la usabilitat de la programació de models nacionals. De fet, hi ha una diferència integral entre la M2.5 i el nivell Opus declarat oficialment, però sempre que algú estigui disposat a confiar i a utilitzar-lo, les coses aniran en la direcció correcta. Des d'aquest punt de vista, la M2.5 és, de fet, un pas ferm que Shiyu ha fet cap a l'objectiu de la victòria.



