稀宇 MiniMax M2.5 Anmeldelse
稀宇 MiniMax M2.5 Anmeldelse
Kort konklusion: Rodfæstet nedad, voksende opad
Grundlæggende information
稀宇s forrige generation, M2.1, havde tekniske problemer, hvilket resulterede i betydelige fremskridt inden for programmering, men logiske evner var ringere end M2. Heldigvis har M2.5 grundlæggende løst de tekniske problemer, og evnerne er tilbage på sporet. Sammenlignet med M2 er M2.5's fremskridt omkring 17 %.
En del af fremskridtet er dog opnået gennem længere tankekæder og dybere udforskning af løsningsrummet. M2.5's gennemsnitlige Token-forbrug er det 6. højeste blandt alle testede modeller, næsten dobbelt så højt som konkurrenten Sonnet. Heldigvis er 稀宇s computerkraft garanteret, og omkostningerne er ikke høje. Selvom programmering ikke kan erstatte Sonnet fuldstændigt, er den fuldt ud anvendelig til daglig brug. M2.5 har endelig nået det mål, som M2.1 ønskede at opnå.
Logiske resultater
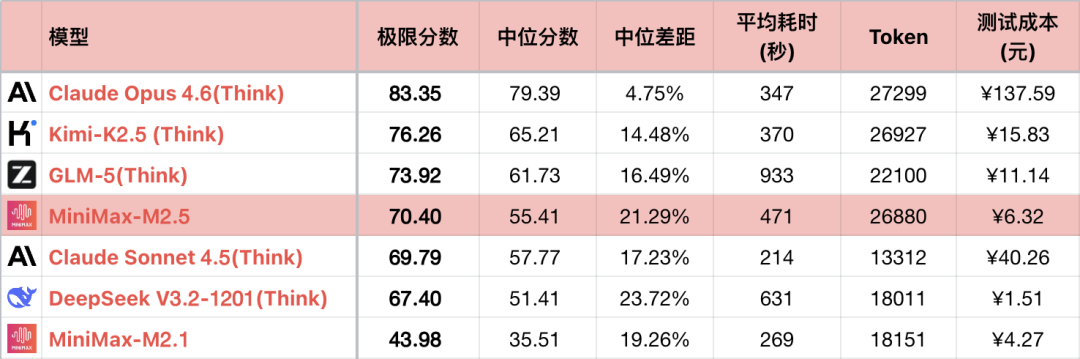
*1 For at fremhæve kontrastforholdet viser tabellen kun en del af de sammenlignelige modeller, ikke en komplet rangering.
*2 For spørgsmål og testmetoder, se: 大语言模型-逻辑能力横评 26-01 月榜. Tilføjet #56 spørgsmål.
*3 Den komplette liste opdateres på https://llm2014.github.io/llm_benchmark/
*4 Rød er begrænset til foråret og repræsenterer festlighed, uden anden betydning.
Da M2.1 er en version med en fejl og usædvanligt lav logisk evne, vil den følgende tekst kun foretage en generationssammenligning mellem M2 og M2.5.
Forbedringer
- Stabil inferens: M2.5 kan opretholde indledende begrænsninger og kontekstuelle detaljer under længere inferensprocesser, så nogle problemer, der ikke er særligt vanskelige, men kræver "fokus", har M2.5 en markant forbedret score. For eksempel #4 Rubiks terning rotation, M2.5 er den 8. model i verden til at opnå en perfekt score. Men denne type problemer kan de tre store nordamerikanske virksomheder stabilt opnå en perfekt score, mens M2.5 kun kan opnå det med en lille sandsynlighed, hvilket viser en klar forskel.
- Programmering: Som nævnt ovenfor kan M2.5 ikke erstatte Sonnet fuldstændigt, primært på grund af begrænset viden om programmering. I situationer, der kræver erfaring, færdigheder, API-versionsforskelle osv., er det svært for M2.5 at opdage problemer på egen hånd uden hints, og det kræver normalt flere runder for gradvist at indsnævre problemet. Men dette er allerede et stort fremskridt i forhold til M2. I C-ingeniørtesten vil de fleste indenlandske modeller sidde fast i de første 2 runder, mens M2.5 er den første indenlandske model, der bryder igennem til 8. runde. Selvom M2.5 har åbenlyse mangler i OpenGL-brug og rumlig fantasi, kan den med optimerede Agent-evner konstant prøve og fejle og konvergere til den korrekte løsning. Det er også værd at bemærke, at M2.5 "taler" mindre, når den arbejder med programmering, og næsten kun outputter et kort resumé, når arbejdet er endeligt afsluttet, og ikke outputter tanker undervejs. Andre ingeniørprojekter er stadig under test og vil blive opdateret senere.
- Beregningskapacitet: M2's beregningskapacitet er ikke fremragende, og M2.1 er endda et tilbageskridt. M2.5 har gjort effektive forbedringer fra et lavt udgangspunkt. I de fleste simple beregninger har M2.5 en lille sandsynlighed for høj præcision, men i de fleste tilfælde er der stadig problemer med forkerte beregninger, store fejl og manglende forståelse af formler. Træningen på dette område er stadig utilstrækkelig. Som en Agent-drevet model er beregningskapacitet ikke et must, og Claude-seriens beregninger har også længe været bagud.
Mangler
- Instruktionsoverholdelse: Sammenlignet med M2 er forbedringen i instruktionsoverholdelse ikke stor. Sandsynligheden for at opnå en perfekt score på nogle simple problemer er højere, men den er heller ikke stabil. Der er tilfælde af tilfældig kassering eller ændring af instruktioner, men ved at observere tankekædeindholdet bemærker modellen alle instruktioner, og det endelige output har problemer. Den samlede præstation er bagud i forhold til andre modeller i den første række. I programmering er der også tilfælde af ignorering af kodningskrav og projektstandarder, for eksempel i C-ingeniørprojektet, hvor det er specificeret, at Z-aksen vender opad, men M2.5 ændrede den egenhændigt til Y-aksen for at rette en anden fejl. Det er nødvendigt at være ekstra opmærksom på kontrol ved daglig brug.
- Hallucinationer: M2.5's hallucinationsniveau har ikke ændret sig markant i forhold til M2. I de fleste kontekstrelaterede problemer er de to modellers maksimale score ens. Selv i #43 målantalberegningsproblemet vil M2.5 begå nogle lavniveauproblemer, som kun modeller i anden række vil begå, såsom gentagen brug af tal og udeladelse af tal.
Cyberhistorikeren siger
Indenlandske producenter har brugt et halvt år på at udforske, hvordan programmeringsmodeller skal laves. De tidligste modeller, der hævdede at være en erstatning for Sonnet, lignede kun hinanden i "en sætning" generationseffekten. Deres interne kodeorganisation, engineering og vigtigere multi-runde iterationskapacitet er langt ringere. Dette har også gjort, at indenlandske programmører generelt ikke stoler på indenlandske modeller og hellere vil bruge Claude med risiko for at blive blokeret.
Men efterhånden som MiniMax M2 og M2.1 indledningsvist vendte stemningen, har M2.5-generationen taget et stort skridt fremad i anvendeligheden af indenlandsk modelprogrammering. Faktisk er der stadig en allround forskel mellem M2.5 og det officielle krav om Opus-niveau, men så længe nogen er villig til at stole på og bruge det, vil tingene udvikle sig i den rigtige retning. I lyset af dette er M2.5 virkelig et solidt skridt fremad, som 稀宇 har taget mod sejrsmålet.



