稀宇 MiniMax M2.5 Testbericht
稀宇 MiniMax M2.5 Testbericht
Kurzes Fazit: Nach unten verwurzelt, nach oben wachsend
Grundlegende Informationen
Die vorherige Generation M2.1 von 稀宇 hatte aufgrund technischer Probleme zwar deutliche Fortschritte in der Programmierung gemacht, aber die logischen Fähigkeiten blieben hinter M2 zurück. Glücklicherweise hat M2.5 die technischen Probleme im Wesentlichen gelöst und die Fähigkeiten sind wieder auf dem normalen Stand. Im Vergleich zu M2 beträgt der Fortschritt von M2.5 etwa 17 %.
Ein Teil des Fortschritts wurde jedoch durch längere Denkketten und eine tiefere Erforschung des Lösungsraums erreicht. Der durchschnittliche Token-Verbrauch von M2.5 ist der sechsthöchste aller getesteten Modelle und fast doppelt so hoch wie der des Konkurrenten Sonnet. Glücklicherweise sind die Rechenressourcen von 稀宇 gesichert und die Kosten sind nicht hoch. Die Programmierung kann Sonnet zwar nicht lückenlos ersetzen, aber für den täglichen Gebrauch ist sie vollkommen ausreichend. M2.5 hat letztendlich das Ziel erreicht, das M2.1 erreichen wollte.
Logische Ergebnisse
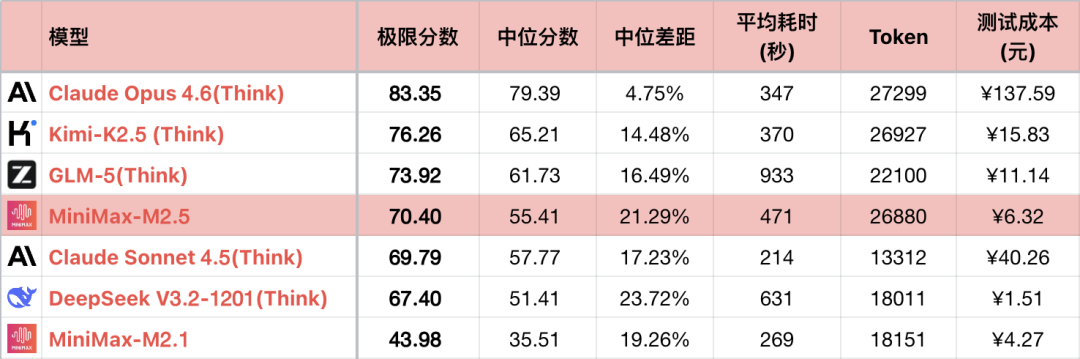
*1 Die Tabelle zeigt zur Hervorhebung der Vergleichsbeziehung nur einen Teil der vergleichbaren Modelle und ist keine vollständige Sortierung.
*2 Informationen zu den Aufgaben und Testmethoden finden Sie unter: 大语言模型-逻辑能力横评 26-01 月榜. Neu hinzugekommen ist Aufgabe #56.
*3 Die vollständige Rangliste wird unter https://llm2014.github.io/llm_benchmark/ aktualisiert.
*4 Die rote Farbe ist auf die Frühlingsfestzeit beschränkt und soll festlich wirken, sie hat keine andere Bedeutung.
Da M2.1 eine Version mit einem Bug und einer außergewöhnlich niedrigen logischen Fähigkeit ist, wird im Folgenden nur ein generationsübergreifender Vergleich zwischen M2 und M2.5 vorgenommen.
Verbesserungen
- Stabile Inferenz: M2.5 kann die anfänglichen Einschränkungen und Kontextdetails während längerer Inferenzprozesse beibehalten, sodass M2.5 bei einigen nicht allzu schwierigen, aber "konzentrierten" Problemen deutlich besser abschneidet. Zum Beispiel ist M2.5 das weltweit achte Modell, das bei #4 Zauberwürfel-Rotation die volle Punktzahl erreicht hat. Bei solchen Problemen können die nordamerikanischen Top-3 jedoch stabil die volle Punktzahl erreichen, während M2.5 nur mit geringer Wahrscheinlichkeit einmal richtig liegt, was einen deutlichen Unterschied darstellt.
- Programmierung: Wie bereits erwähnt, kann M2.5 Sonnet nicht umfassend ersetzen, was hauptsächlich auf den begrenzten Wissensstand in der Programmierung zurückzuführen ist. In Situationen, die Erfahrung, Fähigkeiten, API-Versionsunterschiede usw. erfordern, kann M2.5 ohne Hinweise nur schwer selbst Probleme erkennen und benötigt in der Regel mehrere Runden, um das Problem schrittweise einzugrenzen. Dies ist jedoch bereits ein großer Fortschritt gegenüber M2. Im C-Engineering-Test scheitern die meisten nationalen Modelle in den ersten beiden Runden, während M2.5 das erste nationale Modell ist, das die achte Runde erreicht. Obwohl M2.5 offensichtliche Schwächen in der OpenGL-Nutzung und der räumlichen Vorstellungskraft aufweist, kann es mit optimierten Agent-Fähigkeiten durch ständiges Ausprobieren und Verfeinern zur richtigen Lösung gelangen. Es ist auch erwähnenswert, dass M2.5 bei der Programmierarbeit weniger "redet" und fast nur nach Abschluss der Arbeit eine kurze Zusammenfassung ausgibt, ohne zwischendurch Gedanken auszugeben. Andere Projekte werden noch getestet und später aktualisiert.
- Rechenleistung: Die Rechenleistung von M2 ist nicht gerade herausragend, und M2.1 hat sich sogar verschlechtert. M2.5 hat auf einem niedrigen Ausgangsniveau wirksame Verbesserungen erzielt. Bei den meisten einfachen Berechnungen erzielt M2.5 mit geringer Wahrscheinlichkeit eine hohe Genauigkeit, in den meisten Fällen gibt es jedoch immer noch Rechenfehler, große Fehler und ein Unverständnis der Formeln. In diesem Bereich besteht weiterhin Trainingsbedarf. Als Agent-gesteuertes Modell ist die Rechenleistung keine zwingende Voraussetzung, und auch die Berechnungen der Claude-Serie hinken seit langem hinterher.
Mängel
- Befolgung von Anweisungen: Im Vergleich zu M2 ist die Verbesserung bei der Befolgung von Anweisungen nicht groß. Bei einigen einfachen Problemen ist die Wahrscheinlichkeit, die volle Punktzahl zu erreichen, höher, aber auch nicht stabil. Es kommt vor, dass Anweisungen zufällig verworfen oder verfälscht werden, aber bei der Beobachtung des Inhalts der Denkkette stellt man fest, dass das Modell alle Anweisungen beachtet hat, aber bei der endgültigen Ausgabe Probleme auftreten. Die Gesamtleistung liegt hinter anderen Modellen der ersten Liga zurück. Auch in der Programmierung kommt es vor, dass Kodierungsanforderungen und Projektstandards ignoriert werden. Im C-Engineering beispielsweise ist festgelegt, dass die Z-Achse nach oben zeigt, aber M2.5 hat sie eigenmächtig in die Y-Achse geändert, um einen anderen Bug zu beheben. Bei der täglichen Nutzung ist zusätzliche Vorsicht geboten.
- Halluzinationen: Das Halluzinationsniveau von M2.5 hat sich im Vergleich zu M2 nicht wesentlich verändert. Bei den meisten kontextbezogenen Problemen ist die maximale Punktzahl der beiden Modelle gleich. Sogar bei #43 Zielzahlenberechnungsproblemen macht M2.5 noch einige Anfängerfehler, die bei Modellen der zweiten Liga auftreten, wie z. B. die wiederholte Verwendung von Zahlen oder das Auslassen von Zahlen.
Der Cyber-Historiker sagt
Chinesische Hersteller haben ein halbes Jahr damit verbracht, zu erforschen, wie Programmiermodelle eigentlich funktionieren sollen. Die ersten Modelle, die angeblich Sonnet ebenbürtig waren, sahen meist nur bei der "Ein-Satz"-Generierung ähnlich aus. Ihre interne Code-Organisation, das Engineering und vor allem die Fähigkeit zur mehrfachen Iteration sind weitaus geringer. Dies führt dazu, dass chinesische Programmierer den nationalen Modellen im Allgemeinen misstrauen und lieber Claude verwenden, auch wenn sie das Risiko einer Kontosperrung eingehen.
Nachdem MiniMax M2 und M2.1 das Image zunächst verbessert hatten, hat die Generation M2.5 die Nutzbarkeit der nationalen Modelle für die Programmierung einen großen Schritt vorangebracht. Es stimmt, dass M2.5 noch in jeder Hinsicht hinter dem von offizieller Seite angekündigten Opus-Niveau zurückbleibt, aber solange jemand bereit ist, zu vertrauen und es zu nutzen, werden sich die Dinge zum Besseren entwickeln. In diesem Sinne ist M2.5 in der Tat ein solider Schritt von 稀宇 in Richtung des Siegesziels.



