Reseña de MiniMax M2.5 de Shiyu
Reseña de MiniMax M2.5 de Shiyu
Conclusión breve: Arraigando hacia abajo, creciendo hacia arriba
Situación básica
La generación anterior de Shiyu, M2.1, debido a problemas técnicos, aunque mostró un progreso significativo en la programación, su capacidad lógica quedó por detrás de M2. Afortunadamente, M2.5 básicamente resolvió los problemas técnicos y la capacidad volvió a la normalidad. En comparación con M2, el progreso de M2.5 es de aproximadamente el 17%.
Sin embargo, parte del progreso se logra a través de cadenas de pensamiento más largas y una exploración más profunda del espacio de soluciones. El consumo promedio de Token de M2.5 se ubica en el sexto lugar más alto entre todos los modelos probados, casi el doble que el de su competidor Sonnet. Afortunadamente, la potencia de cálculo de Shiyu está garantizada y el costo no es alto. Aunque la programación no puede reemplazar a Sonnet sin puntos ciegos, es completamente utilizable para el uso diario. M2.5 finalmente logró el objetivo que M2.1 quería alcanzar.
Resultados lógicos
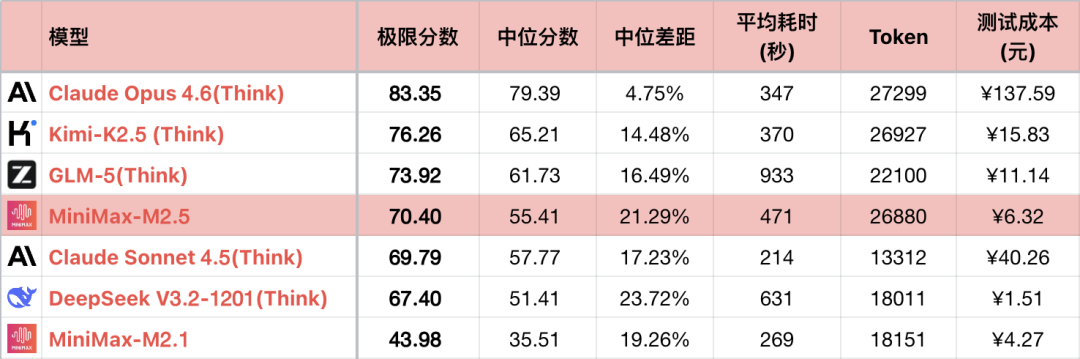
*1 La tabla solo muestra algunos modelos comparables para resaltar la relación de comparación, no es una clasificación completa.
*2 Para las preguntas y los métodos de prueba, consulte: Evaluación comparativa horizontal de la capacidad lógica del modelo de lenguaje grande - Lista mensual de enero de 2026. Se agregó la pregunta #56.
*3 La lista completa se actualiza en https://llm2014.github.io/llm_benchmark/
*4 El rojo es limitado durante el Festival de Primavera, lo que indica alegría, sin otro significado.
Dado que M2.1 es una versión con errores y una capacidad lógica anormalmente baja, el siguiente texto solo hará una comparación intergeneracional entre M2 y M2.5.
Mejoras
- Inferencia estable: M2.5 puede mantener las restricciones iniciales y los detalles del contexto durante un proceso de inferencia más largo, por lo que algunos problemas que no son difíciles, pero que requieren "concentración", M2.5 obtiene una puntuación significativamente más alta. Por ejemplo, #4 Rotación del cubo de Rubik, M2.5 es el octavo modelo a nivel mundial en obtener la máxima puntuación. Pero este tipo de problemas, los tres grandes de América del Norte pueden obtener la máxima puntuación de forma estable, mientras que M2.5 solo puede acertar una pequeña probabilidad, la diferencia es obvia.
- Programación: Como se mencionó anteriormente, M2.5 no puede reemplazar a Sonnet en todos los aspectos, principalmente debido a la cantidad de conocimiento de programación. En situaciones que requieren experiencia, habilidades, diferencias en la API de la versión, etc., M2.5 tiene dificultades para encontrar problemas por sí solo sin indicaciones, y generalmente necesita varias rondas para reducir gradualmente el problema. Pero esto ya es una gran mejora con respecto a M2. En las pruebas de ingeniería C, la mayoría de los modelos nacionales se atascan en las primeras 2 rondas, mientras que M2.5 se convirtió en el primer modelo nacional en superar la octava ronda. Aunque M2.5 tiene deficiencias obvias en el uso de OpenGL y la imaginación espacial, con la capacidad de Agent optimizada, puede probar y equivocarse continuamente, convergiendo a la solución correcta. Además, vale la pena señalar que M2.5 "habla" menos cuando trabaja en programación, y casi solo genera un breve resumen después de completar el trabajo final, y no genera ideas a mitad de camino. Otros proyectos de ingeniería aún están en prueba y se actualizarán posteriormente.
- Capacidad de cálculo: La capacidad de cálculo de M2 no es excelente, y M2.1 es aún peor. M2.5 ha realizado mejoras efectivas en un punto de partida bajo. En la mayoría de los cálculos simples, M2.5 tiene una pequeña probabilidad de alta precisión, y en la mayoría de los casos todavía hay errores de cálculo, grandes errores y problemas para comprender las fórmulas. La capacitación en este aspecto aún es insuficiente. Como modelo impulsado por Agent, la capacidad de cálculo no es una necesidad rígida, y el cálculo de la serie Claude también se ha quedado atrás durante mucho tiempo.
Deficiencias
- Seguimiento de instrucciones: En comparación con M2, el aumento en el seguimiento de instrucciones no es grande. La probabilidad de obtener la máxima puntuación en algunos problemas simples es mayor, pero tampoco es estable. Existen casos de descarte aleatorio de instrucciones o alteración de instrucciones, pero al observar el contenido de la cadena de pensamiento, el modelo ha notado todas las instrucciones y finalmente hay problemas con la salida. El rendimiento general está por detrás de otros modelos en el primer nivel. En la programación, también habrá casos en los que se ignoren los requisitos de codificación y las especificaciones del proyecto. Por ejemplo, en el proyecto C, se estipula que el eje Z de las coordenadas está hacia arriba, pero M2.5 lo cambió arbitrariamente al eje Y para corregir otro error. Se debe prestar especial atención al control en el uso diario.
- Alucinaciones: El nivel de alucinación de M2.5 no ha cambiado significativamente con respecto a M2. En la mayoría de los problemas relacionados con el contexto, las puntuaciones límite de los dos son consistentes. Incluso en el problema de cálculo del número objetivo #43, M2.5 también cometerá algunos problemas de bajo nivel que solo aparecerían en los modelos de segundo nivel, como el uso repetido de números y la omisión de números.
El historiador cibernético dice
Los fabricantes nacionales han pasado más de medio año explorando cómo se deben hacer los modelos de programación. La primera tanda de modelos que afirman ser reemplazos de Sonnet solo parecen ser similares en el efecto de generación de "una oración". Su organización de código interna, ingeniería y, lo que es más importante, la capacidad de iteración de múltiples rondas están lejos de ser comparables. Esto también hace que los programadores nacionales generalmente no confíen en los modelos nacionales y prefieran usar Claude a riesgo de que se bloqueen sus cuentas.
Con MiniMax M2 y M2.1 revirtiendo preliminarmente la reputación, la generación M2.5 avanza la usabilidad de la programación del modelo nacional un gran paso adelante. De hecho, todavía hay una brecha integral entre M2.5 y el nivel Opus declarado oficialmente, pero siempre que alguien esté dispuesto a confiar y esté dispuesto a usarlo, las cosas se desarrollarán en una buena dirección. Desde este punto de vista, M2.5 es de hecho un paso sólido que Shiyu ha dado hacia el objetivo de la victoria.



