Évaluation de MiniMax M2.5 de Xiyu
Évaluation de MiniMax M2.5 de Xiyu
Conclusion rapide : S'enraciner vers le bas, grandir vers le haut
Informations générales
La génération précédente de Xiyu, M2.1, en raison de problèmes techniques, bien qu'elle ait fait des progrès significatifs en programmation, était en retard sur M2 en termes de capacités logiques. Heureusement, M2.5 a fondamentalement résolu les problèmes techniques et les capacités sont revenues à la normale. Par rapport à M2, l'amélioration de M2.5 est d'environ 17 %.
Cependant, une partie de l'amélioration est obtenue grâce à des chaînes de pensée plus longues et à une exploration plus approfondie de l'espace de solution. La consommation moyenne de Tokens de M2.5 se classe au 6e rang le plus élevé de tous les modèles testés, soit près du double de celle de son concurrent Sonnet. Heureusement, la puissance de calcul de Xiyu est garantie et le coût n'est pas élevé. Bien que la programmation ne puisse pas remplacer Sonnet sans angle mort, elle est entièrement utilisable pour un usage quotidien. M2.5 a finalement atteint l'objectif que M2.1 voulait atteindre.
Résultats logiques
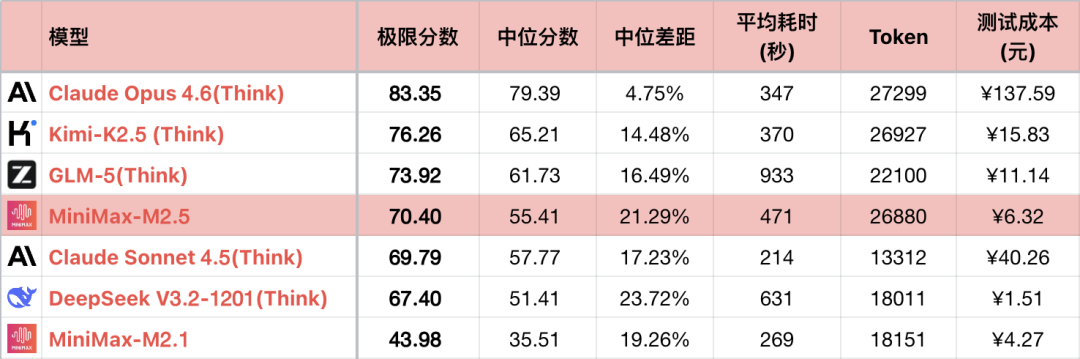
*1 Le tableau ne présente que certaines des modèles comparables pour mettre en évidence les relations de comparaison, et n'est pas un classement complet.
*2 Pour les questions et les méthodes de test, voir : Évaluation comparative des capacités logiques des grands modèles de langage - Classement mensuel de janvier 2026. Ajout de la question #56.
*3 Le classement complet est mis à jour sur https://llm2014.github.io/llm_benchmark/
*4 Le rouge est limité à la période du Nouvel An chinois, ce qui représente la joie et n'a pas d'autre signification.
Étant donné que M2.1 est une version avec un bug et des capacités logiques exceptionnellement faibles, la section suivante ne fera qu'une comparaison intergénérationnelle entre M2 et M2.5.
Améliorations
- Inférence stable : M2.5 peut maintenir les contraintes initiales et les détails du contexte pendant un processus d'inférence plus long. Par conséquent, certains problèmes qui ne sont pas difficiles mais qui nécessitent de la "concentration", M2.5 obtient des scores significativement plus élevés. Par exemple, #4 Rotation du Rubik's Cube, M2.5 est le 8e modèle au monde à obtenir une note parfaite. Cependant, ce type de problème, les trois grands d'Amérique du Nord peuvent tous obtenir une note parfaite de manière stable, tandis que M2.5 ne peut le faire qu'une fois avec une faible probabilité, la différence est évidente.
- Programmation : Comme mentionné précédemment, M2.5 ne peut pas remplacer Sonnet dans tous les aspects, principalement en raison de la quantité de connaissances en programmation. Dans les cas où l'expérience, les compétences, les différences d'API de version, etc. sont nécessaires, M2.5 a du mal à identifier les problèmes par lui-même sans invites, et il faut généralement plusieurs tours pour réduire progressivement le problème. Mais c'est déjà une énorme amélioration par rapport à M2. Dans le test de projet C, la plupart des modèles nationaux seront bloqués dans les 2 premiers tours, tandis que M2.5 est devenu le premier modèle national à percer jusqu'au 8e tour. Bien que M2.5 ait des lacunes évidentes dans l'utilisation d'OpenGL et l'imagination spatiale, avec la capacité d'Agent optimisée, il peut continuellement essayer et échouer, et converger vers la solution correcte. Il convient également de noter que M2.5 "parle" moins lorsqu'il travaille sur la programmation, et ne sort qu'un bref résumé après avoir finalement terminé le travail, et ne sort pas d'idées à mi-chemin. D'autres projets sont encore en cours de test et seront mis à jour ultérieurement.
- Capacité de calcul : La capacité de calcul de M2 n'est pas excellente, et M2.1 est encore plus en retrait. M2.5 a apporté des améliorations efficaces à partir d'un point de départ bas. Dans la plupart des calculs simples, M2.5 a une faible probabilité de haute précision, et dans la plupart des cas, il y a encore des erreurs de calcul, de grandes erreurs et des problèmes de compréhension des formules. La formation dans ce domaine est encore insuffisante. En tant que modèle piloté par Agent, la capacité de calcul n'est pas une nécessité absolue, et le calcul de la série Claude est également en retard depuis longtemps.
Inconvénients
- Suivi des instructions : Par rapport à M2, l'amélioration du suivi des instructions n'est pas significative. La probabilité d'obtenir une note parfaite pour certains problèmes simples est plus élevée, mais elle ne peut pas non plus être stable. Il existe des cas d'abandon aléatoire d'instructions ou de falsification d'instructions, mais en observant le contenu de la chaîne de pensée, le modèle a remarqué toutes les instructions, et des problèmes surviennent dans la sortie finale. La performance globale est en retard sur les autres modèles du premier niveau. En programmation, il y aura également des cas où les exigences de codage et les spécifications du projet sont ignorées. Par exemple, dans le projet C, il est stipulé que l'axe Z est orienté vers le haut, mais M2.5 l'a changé en axe Y sans autorisation afin de corriger un autre bug. Une attention particulière doit être accordée au contrôle dans l'utilisation quotidienne.
- Hallucinations : Le niveau d'hallucination de M2.5 n'a pas changé de manière significative par rapport à M2. Pour la plupart des problèmes liés au contexte, les scores limites des deux sont les mêmes. Même sur le problème de calcul du nombre cible #43, M2.5 commettra également des erreurs de bas niveau telles que l'utilisation répétée de nombres et l'omission de nombres qui n'apparaissent que dans les modèles du deuxième niveau.
L'historien cybernétique dit
Les fabricants nationaux ont passé plus de six mois à explorer comment faire des modèles de programmation. La première série de modèles qui prétendaient être des alternatives à Sonnet ne semblaient proches qu'en termes d'effet de génération de "une phrase". Leur organisation de code interne, leur ingénierie et, plus important encore, leurs capacités d'itération multi-tours sont bien inférieures. Cela a également conduit les programmeurs nationaux à se méfier généralement des modèles nationaux et à préférer utiliser Claude au risque d'être bloqués.
Et avec MiniMax M2, M2.1 inversant initialement la tendance, la génération M2.5 fait un grand pas en avant dans la disponibilité de la programmation des modèles nationaux. En effet, il existe encore un écart global entre M2.5 et le niveau Opus déclaré par le fabricant, mais tant que quelqu'un est prêt à faire confiance et à utiliser, les choses évolueront dans la bonne direction. De ce point de vue, M2.5 est en effet une étape solide que Xiyu a franchie vers son objectif de victoire.



