稀宇 MiniMax M2.5-ის მიმოხილვა
稀宇 MiniMax M2.5 测评
მოკლე დასკვნა: ძირს დაფუძნება, ზემოთ ზრდა
ძირითადი ინფორმაცია
稀宇-ის წინა თაობის M2.1 ტექნიკური პრობლემების გამო, პროგრამირების კუთხით მნიშვნელოვანი პროგრესის მიუხედავად, ლოგიკური შესაძლებლობებით ჩამორჩებოდა M2-ს. საბედნიეროდ, M2.5-მა ძირითადად მოაგვარა ტექნიკური პრობლემები და შესაძლებლობები ნორმალურ კალაპოტში დააბრუნა. M2-თან შედარებით, M2.5-ის პროგრესი დაახლოებით 17%-ია.
თუმცა, პროგრესის ნაწილი მიღწეულია უფრო გრძელი აზროვნების ჯაჭვისა და უფრო ღრმა ამონახსნების სივრცის შესწავლის ხარჯზე. M2.5-ის საშუალო Token-ის მოხმარება მე-6 ადგილზეა ყველა ტესტირებად მოდელს შორის და თითქმის 2-ჯერ აღემატება კონკურენტ Sonnet-ს. საბედნიეროდ, 稀宇-ს აქვს გამოთვლითი სიმძლავრის გარანტია და ღირებულებაც დაბალია. პროგრამირება ვერ ახერხებს Sonnet-ის სრულად ჩანაცვლებას, მაგრამ ყოველდღიური გამოყენებისთვის სრულიად გამოსადეგია. M2.5-მა საბოლოოდ მიაღწია იმ მიზანს, რის მიღწევასაც M2.1 ცდილობდა.
ლოგიკური შედეგები
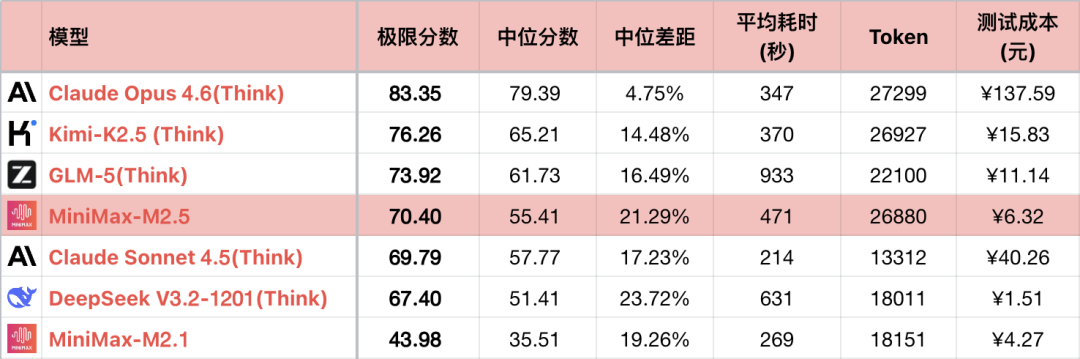
*1 ცხრილში კონტრასტის ხაზგასასმელად ნაჩვენებია მხოლოდ შედარებადი მოდელების ნაწილი და არა სრული დალაგება.
*2 ამოცანები და ტესტირების მეთოდები იხილეთ: დიდი ენობრივი მოდელი - ლოგიკური შესაძლებლობების ჰორიზონტალური შეფასება 26-01 თვის რეიტინგი. დამატებულია #56 ამოცანა.
*3 სრული რეიტინგი განახლებულია https://llm2014.github.io/llm_benchmark/
*4 წითელი ფერი შეზღუდულია გაზაფხულის ფესტივალის პერიოდისთვის და გამოხატავს სიხარულს, სხვა მნიშვნელობა არ აქვს.
იმის გამო, რომ M2.1 იყო შეცდომის შემცველი ვერსია, ლოგიკური შესაძლებლობებით უკიდურესად დაბალი, ამიტომ ქვემოთ მოცემულია მხოლოდ M2-ისა და M2.5-ის თაობათა შორის შედარება.
გაუმჯობესებები
- სტაბილური დასკვნა: M2.5-ს შეუძლია შეინარჩუნოს საწყისი შეზღუდვები და კონტექსტური დეტალები უფრო ხანგრძლივი დასკვნის პროცესში, ამიტომ ზოგიერთ არცთუ ისე რთულ, მაგრამ „კონცენტრაციას“ საჭირო ამოცანაში, M2.5-ის ქულა მნიშვნელოვნად გაიზარდა. მაგალითად, #4 კუბიკ-რუბიკის ბრუნვაში, M2.5 არის მსოფლიოში მე-8 მოდელი, რომელმაც მიიღო მაქსიმალური ქულა. მაგრამ ამ ტიპის ამოცანებში, ჩრდილოეთ ამერიკის დიდ სამეულს შეუძლია სტაბილურად მიიღოს მაქსიმალური ქულა, ხოლო M2.5-ს შეუძლია მხოლოდ მცირე ალბათობით ერთხელ გააკეთოს ეს, რაც აშკარა განსხვავებაა.
- პროგრამირება: როგორც ზემოთ აღინიშნა, M2.5 ვერ ახერხებს Sonnet-ის ყოველმხრივ ჩანაცვლებას, რაც ძირითადად განპირობებულია პროგრამირების ცოდნის ნაკლებობით. გამოცდილების, ტექნიკის, ვერსიის API-ების განსხვავებების და ა.შ. საჭიროების შემთხვევაში, M2.5-ს უჭირს პრობლემის დამოუკიდებლად აღმოჩენა და, როგორც წესი, სჭირდება მრავალი რაუნდი პრობლემის თანდათანობით შესამცირებლად. მაგრამ ეს უკვე უზარმაზარი პროგრესია M2-თან შედარებით. C პროექტის ტესტირებაში, ეროვნული მოდელების უმეტესობა ჩერდება პირველ 2 რაუნდში, ხოლო M2.5 გახდა პირველი ეროვნული მოდელი, რომელმაც მე-8 რაუნდამდე მიაღწია. მიუხედავად იმისა, რომ M2.5-ს აქვს აშკარა სისუსტეები OpenGL-ის გამოყენებაში და სივრცით წარმოსახვაში, ოპტიმიზირებულ Agent-ის შესაძლებლობებთან ერთად, მას შეუძლია მუდმივად სცადოს და შეცდომით მიუახლოვდეს სწორ ამონახსნს. ასევე აღსანიშნავია, რომ M2.5 პროგრამირების დროს ნაკლებად „ლაპარაკობს“ და თითქმის მხოლოდ სამუშაოს დასრულების შემდეგ აკეთებს მოკლე შეჯამებას და შუალედში არ გამოაქვს აზრები. სხვა პროექტები ჯერ კიდევ ტესტირების პროცესშია და მოგვიანებით განახლდება.
- გამოთვლითი შესაძლებლობები: M2-ის გამოთვლითი შესაძლებლობები არ იყო გამორჩეული, ხოლო M2.1 კიდევ უფრო გაუარესდა. M2.5-მა ეფექტური გაუმჯობესება მოახდინა დაბალი საწყისი წერტილიდან. უმეტეს მარტივ გამოთვლებში, M2.5-ს აქვს მცირე ალბათობით მაღალი სიზუსტე, მაგრამ უმეტეს შემთხვევაში მაინც უშვებს შეცდომებს, აქვს დიდი ცდომილება და ვერ ხვდება ფორმულებს. ამ მხრივ ვარჯიში ჯერ კიდევ არ არის საკმარისი. როგორც Agent-ზე მომუშავე მოდელისთვის, გამოთვლითი შესაძლებლობები არ არის აუცილებელი. Claude-ის სერიის გამოთვლები ასევე დიდი ხანია ჩამორჩება.
ნაკლოვანებები
- ინსტრუქციების დაცვა: M2-თან შედარებით, ინსტრუქციების დაცვის გაუმჯობესება არ არის დიდი. ზოგიერთ მარტივ ამოცანაში მაქსიმალური ქულის მიღების ალბათობა უფრო მაღალია, მაგრამ ის ასევე არ არის სტაბილური. არსებობს ინსტრუქციების შემთხვევითად გამოტოვების ან ინსტრუქციების შეცვლის შემთხვევები, მაგრამ აზროვნების ჯაჭვის შინაარსზე დაკვირვებით, მოდელი ამჩნევს ყველა ინსტრუქციას, მაგრამ საბოლოო შედეგში ჩნდება პრობლემა. საერთო ჯამში, ის ჩამორჩება პირველი ეშელონის სხვა მოდელებს. პროგრამირებაში ასევე არის შემთხვევები, როდესაც უგულებელყოფენ კოდირების მოთხოვნებს და პროექტის სტანდარტებს. მაგალითად, C პროექტში მითითებულია, რომ Z ღერძი ზემოთ არის მიმართული, მაგრამ M2.5-მა სხვა შეცდომის გამოსასწორებლად თვითნებურად შეცვალა Y ღერძად. ყოველდღიური გამოყენებისას საჭიროა დამატებითი ყურადღების მიქცევა კონტროლზე.
- ჰალუცინაციები: M2.5-ის ჰალუცინაციების დონე მნიშვნელოვნად არ შეცვლილა M2-თან შედარებით. კონტექსტთან დაკავშირებულ პრობლემების უმეტესობაში, ორივეს მაქსიმალური ქულა ერთნაირია. #43 სამიზნე რიცხვის გამოთვლის პრობლემაშიც კი, M2.5 უშვებს მეორე ეშელონის მოდელებისთვის დამახასიათებელ დაბალი დონის შეცდომებს, როგორიცაა რიცხვების განმეორებით გამოყენება და რიცხვების გამოტოვება.
კიბერს ისტორიკოსი ამბობს
ადგილობრივმა მწარმოებლებმა ნახევარ წელზე მეტი გაატარეს პროგრამირების მოდელის შესწავლაში, თუ როგორ უნდა გაკეთდეს ეს. პირველი პარტია, რომელიც აცხადებდა, რომ Sonnet-ის ტოლფასი იყო, ძირითადად მხოლოდ „ერთ წინადადებიან“ გენერირების ეფექტში გამოიყურებოდა მსგავსად. მისი შინაგანი კოდის ორგანიზება, ინჟინერია და, რაც მთავარია, მრავალჯერადი გამეორების შესაძლებლობა გაცილებით ჩამორჩება. ამან ასევე გამოიწვია ის, რომ ადგილობრივ პროგრამისტებს ზოგადად არ ენდობოდნენ ადგილობრივ მოდელებს და ამჯობინებდნენ Claude-ის გამოყენებას ანგარიშის დაბლოკვის რისკის ქვეშაც კი.
მას შემდეგ, რაც MiniMax M2-მა და M2.1-მა თავდაპირველად შეცვალეს საზოგადოებრივი აზრი, M2.5-მა კიდევ ერთი დიდი ნაბიჯი გადადგა ადგილობრივი მოდელების პროგრამირების გამოსაყენებლობის წინსვლისკენ. მართალია, M2.5-სა და ოფიციალურად გამოცხადებულ Opus-ის დონეს შორის ჯერ კიდევ არის ყოველმხრივი უფსკრული, მაგრამ სანამ ვინმე მზად არის ენდოს და გამოიყენოს, ყველაფერი უკეთესობისკენ წავა. აქედან გამომდინარე, M2.5 ნამდვილად არის მყარი ნაბიჯი, რომელიც 稀宇-მ გამარჯვების მიზნისკენ გადადგა.



