희우 MiniMax M2.5 리뷰
희우 MiniMax M2.5 리뷰
짧은 결론: 아래로 뿌리내리고, 위로 성장하다
기본 상황
희우의 이전 세대인 M2.1은 기술적인 문제로 인해 프로그래밍 측면에서는 괄목할 만한 진보를 이루었지만, 논리 능력은 오히려 M2보다 뒤쳐졌습니다. 다행히 M2.5는 기술적인 문제를 기본적으로 해결하여 능력이 정상 궤도로 돌아왔습니다. M2와 비교했을 때 M2.5의 진보는 약 17% 정도입니다.
하지만 일부 진보는 더 긴 사고 사슬과 더 심층적인 해 공간 탐색을 통해 얻어졌습니다. M2.5의 평균 Token 소모량은 테스트 중인 모든 모델 중에서 6번째로 높으며, 경쟁 모델인 Sonnet의 거의 2배에 달합니다. 다행히 희우는 연산 능력이 보장되고 비용도 저렴하여, 프로그래밍 측면에서 Sonnet을 완벽하게 대체할 수는 없지만 일상적인 사용에는 완전히 사용할 수 있습니다. M2.5는 결국 M2.1이 달성하고자 했던 목표를 실현했습니다.
논리 성적
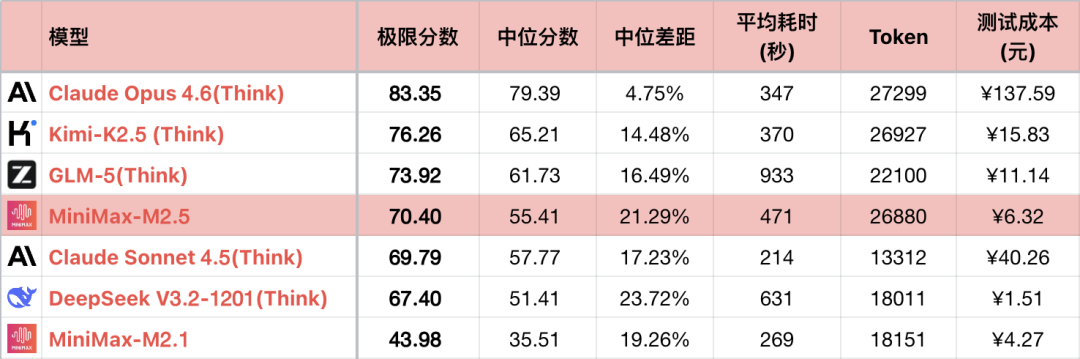
*1 표는 대비 관계를 강조하기 위해 일부 비교 가능한 모델만 표시했으며, 전체 순위는 아닙니다.
*2 문제 및 테스트 방식은 다음을 참조하십시오: 대규모 언어 모델 - 논리 능력 횡평가 26-01 월간 순위. #56번 문제 추가.
*3 전체 순위는 https://llm2014.github.io/llm_benchmark/ 에서 업데이트됩니다.
*4 빨간색은 춘절 기간 한정이며, 경사스러움을 나타내며 다른 의미는 없습니다.
M2.1은 버그가 있고 논리 능력이 비정상적으로 낮은 버전이므로, 아래에서는 M2와 M2.5의 세대 간 비교만 진행합니다.
개선 사항
- 안정적인 추론: M2.5는 더 긴 추론 과정에서 초기 제약 조건과 문맥 세부 사항을 유지할 수 있으므로, 난이도가 높지 않지만 "집중"이 필요한 문제에서 M2.5의 점수가 크게 향상되었습니다. 예를 들어 #4 큐브 회전 문제에서 M2.5는 전 세계에서 8번째로 만점을 받은 모델입니다. 하지만 이러한 문제는 북미의 주요 3개 기업은 대부분 안정적으로 만점을 받지만, M2.5는 낮은 확률로 한 번만 맞출 수 있어 격차가 뚜렷합니다.
- 프로그래밍: 앞서 언급했듯이 M2.5는 모든 면에서 Sonnet을 대체할 수는 없습니다. 주로 프로그래밍 지식량의 한계로 인해 경험, 기술, 버전 API 차이 등이 필요한 경우, M2.5는 힌트가 없으면 스스로 문제를 발견하기 어렵고, 일반적으로 여러 번의 시도를 거쳐 점진적으로 문제를 좁혀야 합니다. 하지만 이는 이미 M2에 비해 엄청난 발전입니다. C 프로젝트 테스트에서 대부분의 중국 모델은 처음 2라운드에서 막히지만, M2.5는 처음으로 8라운드까지 돌파한 중국 모델이 되었습니다. M2.5는 OpenGL 사용과 공간 상상력에 뚜렷한 단점이 있지만, 최적화된 Agent 능력과 함께 지속적으로 시행착오를 거쳐 올바른 해답으로 수렴할 수 있습니다. 또한 M2.5는 프로그래밍 작업을 할 때 "말"이 더 적고, 거의 최종적으로 작업을 완료한 후에만 간략한 요약을 출력하며, 중간에 아이디어를 출력하지 않는다는 점에 주목할 가치가 있습니다. 다른 프로젝트는 아직 테스트 중이며, 추후 업데이트될 예정입니다.
- 계산 능력: M2의 계산 능력은 뛰어나다고 할 수 없으며, M2.1은 더욱 퇴보했습니다. M2.5는 낮은 시작점에서 효과적인 개선을 이루었습니다. 대부분의 간단한 계산에서 M2.5는 낮은 확률로 고정밀도를 보이지만, 대부분의 경우 여전히 계산 오류, 큰 오차, 공식 이해 부족 등의 문제가 있으며, 이 부분에 대한 훈련은 여전히 부족합니다. Agent 기반 모델로서 계산 능력은 필수적인 요소가 아니며, Claude 시리즈의 계산 능력도 오랫동안 뒤쳐져 있습니다.
부족한 점
- 명령어 준수: M2에 비해 명령어 준수의 개선 폭은 크지 않으며, 일부 간단한 문제에서 만점을 받을 확률이 더 높지만, 안정적이지는 않습니다. 무작위로 명령어를 버리거나 변경하는 경우가 있지만, 사고 사슬 내용을 살펴보면 모델은 모든 명령어를 인지하고 있지만 최종 출력에 문제가 발생하는 것으로 보입니다. 전체적인 성능은 1군 다른 모델에 비해 뒤쳐집니다. 프로그래밍에서도 코딩 요구 사항이나 프로젝트 규범을 무시하는 경우가 있습니다. 예를 들어 C 프로젝트에서 좌표 Z축이 위를 향하도록 규정했지만, M2.5는 다른 버그를 수정하기 위해 임의로 Y축이 위를 향하도록 변경했습니다. 일상적인 사용에서는 추가적인 주의가 필요합니다.
- 환각: M2.5의 환각 수준은 M2에 비해 뚜렷한 변화가 없습니다. 대부분의 문맥 관련 문제에서 두 모델의 한계 점수는 동일합니다. 심지어 #43 목표 숫자 계산 문제에서는 M2.5가 2군 모델에서나 나타나는 숫자 반복 사용, 숫자 누락 등의 저급한 문제를 일으키기도 합니다.
사이버 사관의 말
중국 제조업체들은 반년 이상 프로그래밍 모델을 어떻게 만들어야 하는지 탐색했으며, 초기에 Sonnet을 대체한다고 주장했던 모델들은 대부분 "한 문장" 생성 효과에서만 비슷해 보였습니다. 그 내재적인 코드 조직, 엔지니어링, 그리고 더 중요한 다중 반복 능력은 훨씬 뒤쳐져 있습니다. 이로 인해 중국 프로그래머들은 일반적으로 중국 모델을 신뢰하지 않고, 계정 정지 위험을 감수하면서도 Claude를 사용하려 합니다.
MiniMax M2, M2.1이 초기에 평판을 바꾸기 시작하면서, M2.5 세대는 중국 모델의 프로그래밍 사용 가능성을 한 단계 더 발전시켰습니다. 확실히 M2.5는 공식적으로 발표한 Opus 수준과는 모든 면에서 차이가 있지만, 누군가 믿고 사용하려는 의지가 있다면 상황은 좋은 방향으로 발전할 것입니다. 이로 미루어 볼 때 M2.5는 희우가 승리 목표를 향해 내딛는 확실한 발걸음이라고 할 수 있습니다.



