稀宇 MiniMax M2.5 Anmeldelse
稀宇 MiniMax M2.5 Anmeldelse
Kort konklusjon: Røtter ned, vekst opp
Grunnleggende informasjon
Den forrige generasjonen av 稀宇, M2.1, hadde tekniske problemer som førte til betydelig fremgang innen programmering, men logiske evner var dårligere enn M2. Heldigvis har M2.5 i utgangspunktet løst de tekniske problemene, og evnene er tilbake på normalt spor. Sammenlignet med M2 er fremgangen til M2.5 omtrent 17 %.
Imidlertid oppnås en del av fremgangen gjennom lengre tankerekker og dypere utforskning av løsningsrommet. M2.5s gjennomsnittlige Token-forbruk er det 6. høyeste blant alle modeller som testes, nesten dobbelt så høyt som konkurrenten Sonnet. Heldigvis er 稀宇s datakraft garantert, og kostnadene er ikke høye. Selv om programmering ikke kan erstatte Sonnet fullstendig, er den fullt brukbar for daglig bruk. M2.5 oppnådde til slutt målet som M2.1 ønsket å oppnå.
Logiske resultater
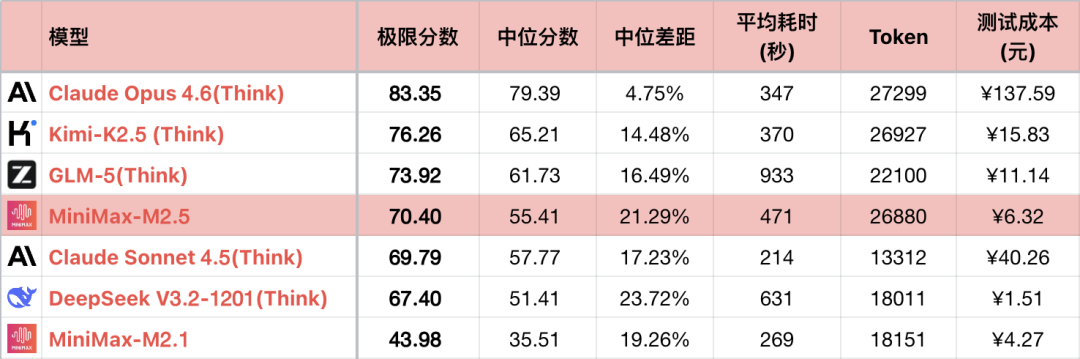
*1 For å fremheve kontrasten viser tabellen bare en del av de sammenlignbare modellene, ikke en fullstendig rangering.
*2 For spørsmål og testmetoder, se: 大语言模型-逻辑能力横评 26-01 月榜. Nytt spørsmål #56.
*3 Fullstendig liste oppdateres på https://llm2014.github.io/llm_benchmark/
*4 Rødt er begrenset til vårfestivalen, som representerer glede og har ingen annen betydning.
Siden M2.1 er en versjon med feil og unormalt lav logisk evne, vil følgende kun gjøre en generasjonsoverskridende sammenligning mellom M2 og M2.5.
Forbedringer
- Stabil resonnering: M2.5 kan opprettholde innledende begrensninger og kontekstuelle detaljer i lengre resonneringsprosesser, slik at M2.5 får betydelig høyere poengsum på noen problemer som ikke er vanskelige, men som krever "fokus". For eksempel #4 Rubiks kube-rotasjon, M2.5 er den 8. modellen i verden som får full poengsum. Imidlertid kan de tre store nordamerikanske selskapene stabilt oppnå full poengsum på denne typen problemer, mens M2.5 bare kan oppnå det med lav sannsynlighet én gang, noe som viser en tydelig forskjell.
- Programmering: Som nevnt tidligere kan ikke M2.5 erstatte Sonnet fullstendig. Hovedårsaken er begrenset kunnskap om programmering. I situasjoner som krever erfaring, ferdigheter, API-forskjeller mellom versjoner osv., er det vanskelig for M2.5 å oppdage problemer selv uten veiledning, og det krever vanligvis flere runder for gradvis å redusere problemet. Men dette er allerede en stor forbedring i forhold til M2. I C-prosjekttesting vil de fleste nasjonale modeller sitte fast i de to første rundene, mens M2.5 ble den første nasjonale modellen som brøt gjennom til den 8. runden. Selv om M2.5 har åpenbare mangler i OpenGL-bruk og romlig fantasi, kan den kontinuerlig prøve og feile og konvergere til den riktige løsningen med optimalisert Agent-evne. Det er også verdt å merke seg at M2.5 "snakker" mindre når den jobber med programmering, og gir nesten bare en kort oppsummering etter at arbeidet er fullført, og gir ikke ut ideer underveis. Andre prosjekter er fortsatt under testing og vil bli oppdatert senere.
- Kalkulasjonsevne: M2s kalkulasjonsevne er ikke eksepsjonell, og M2.1 er enda dårligere. M2.5 har gjort effektive forbedringer fra et lavt utgangspunkt. I de fleste enkle beregninger har M2.5 en liten sannsynlighet for høy presisjon, men i de fleste tilfeller er det fortsatt feilberegninger, store feil og problemer med å forstå formler. Treningen på dette området er fortsatt utilstrekkelig. Som en Agent-drevet modell er ikke kalkulasjonsevne et must, og Claude-serien har også ligget etter lenge.
Mangler
- Instruksjonsfølging: Sammenlignet med M2 er ikke forbedringen i instruksjonsfølging stor. Sannsynligheten for å få full poengsum på noen enkle problemer er høyere, men det er fortsatt ikke stabilt. Det er tilfeller av tilfeldig forkasting eller endring av instruksjoner, men ved å observere innholdet i tankerekken, merker modellen alle instruksjonene, men det er problemer med den endelige utgangen. Den generelle ytelsen er dårligere enn andre modeller i det første laget. I programmering er det også tilfeller av å ignorere kodingskrav og prosjektspesifikasjoner, for eksempel i C-prosjektet, der det er spesifisert at Z-aksen skal være oppover, men M2.5 endret den egenmektig til Y-aksen for å fikse en annen feil. Ekstra oppmerksomhet er nødvendig for daglig bruk.
- Hallusinasjoner: Nivået av hallusinasjoner i M2.5 har ikke endret seg betydelig sammenlignet med M2. De fleste kontekstrelaterte problemer har samme maksimale poengsum. Selv på #43 målrettet tallberegningsproblem vil M2.5 gjøre noen lavnivåfeil som gjentatt bruk av tall og utelatte tall som bare modeller i andre lag vil gjøre.
Cyberhistorikeren sier
Innenlandske produsenter har brukt et halvt år på å utforske hvordan programmeringsmodeller skal gjøres. De tidligste modellene som hevdet å være jevnbyrdige med Sonnet, så ut til å være like bare i "en setning" genereringseffekt. Deres interne kodeorganisering, engineering og, enda viktigere, multi-runde iterasjonsevner er langt dårligere. Dette har også ført til at innenlandske programmerere generelt sett ikke stoler på nasjonale modeller og heller vil bruke Claude, selv med risiko for å bli utestengt.
Men etter at MiniMax M2 og M2.1 i utgangspunktet snudde ryktet, har M2.5-generasjonen tatt et stort skritt fremover i brukervennligheten av nasjonal modellprogrammering. Det er sant at M2.5 fortsatt har en omfattende forskjell fra det offisielt erklærte Opus-nivået, men så lenge noen er villige til å stole på og bruke det, vil ting gå i riktig retning. I lys av dette er M2.5 virkelig et solid skritt fremover for 稀宇 mot seiersmålet.



