Recenzja modelu 稀宇 MiniMax M2.5
Recenzja modelu 稀宇 MiniMax M2.5
Krótkie podsumowanie: Zakorzenianie w dół, wzrost w górę
Podstawowe informacje
Poprzednia generacja modelu 稀宇, M2.1, ze względu na problemy techniczne, pomimo znaczącego postępu w programowaniu, wykazywała gorsze zdolności logiczne niż M2. Na szczęście M2.5 zasadniczo rozwiązał problemy techniczne, a jego możliwości wróciły na normalny tor. W porównaniu do M2, postęp M2.5 wynosi około 17%.
Jednak część postępu osiągnięto dzięki dłuższym łańcuchom myślowym i głębszej eksploracji przestrzeni rozwiązań. Średnie zużycie Tokenów przez M2.5 plasuje się na 6. miejscu wśród wszystkich testowanych modeli, prawie dwukrotnie więcej niż u konkurenta, Sonnet. Na szczęście 稀宇 ma zagwarantowaną moc obliczeniową, a koszty nie są wysokie. Chociaż programowanie nie jest w stanie w pełni zastąpić Sonnet, jest w pełni użyteczne do codziennego użytku. M2.5 ostatecznie osiągnął cel, który zamierzał osiągnąć M2.1.
Wyniki logiczne
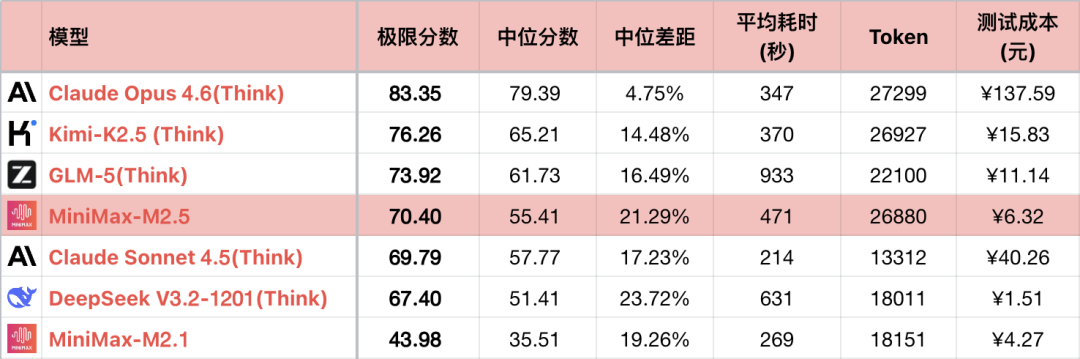
*1 Tabela przedstawia tylko część porównywalnych modeli, aby podkreślić relacje porównawcze, a nie pełne sortowanie.
*2 Pytania i metody testowania, patrz: 大语言模型-逻辑能力横评 26-01 月榜 (Ranking zdolności logicznych dużych modeli językowych - styczeń 2026). Dodano pytanie #56.
*3 Pełna lista rankingowa jest aktualizowana na stronie https://llm2014.github.io/llm_benchmark/
*4 Kolor czerwony jest ograniczony do okresu Święta Wiosny, co oznacza radość i nie ma innego znaczenia.
Ponieważ M2.1 był wersją z błędem i wyjątkowo niskimi zdolnościami logicznymi, poniższy tekst zawiera tylko porównanie międzygeneracyjne M2 i M2.5.
Ulepszenia
- Stabilne wnioskowanie: M2.5 może utrzymać początkowe ograniczenia i szczegóły kontekstowe w dłuższym procesie wnioskowania, więc w przypadku niektórych niezbyt trudnych problemów, które wymagają "skupienia", wynik M2.5 znacznie się poprawił. Na przykład w #4 Obrót kostką Rubika, M2.5 jest 8. modelem na świecie, który uzyskał maksymalny wynik. Jednak w przypadku tego typu problemów, północnoamerykańska Wielka Trójka może stabilnie uzyskiwać maksymalne wyniki, podczas gdy M2.5 może poprawnie odpowiedzieć tylko z małym prawdopodobieństwem, co pokazuje wyraźną różnicę.
- Programowanie: Jak wspomniano wcześniej, M2.5 nie może w pełni zastąpić Sonnet, głównie ze względu na ograniczoną wiedzę programistyczną. W sytuacjach wymagających doświadczenia, umiejętności, różnic w API wersji itp., M2.5 z trudem sam znajduje problemy bez podpowiedzi, zwykle wymaga to wielu rund i stopniowego zawężania problemu. Ale to już ogromny postęp w porównaniu z M2. W testach inżynierii C większość krajowych modeli utknie w pierwszych 2 rundach, a M2.5 stał się pierwszym krajowym modelem, który dotarł do 8. rundy. Chociaż M2.5 ma oczywiste wady w użyciu OpenGL i wyobraźni przestrzennej, w połączeniu ze zoptymalizowanymi możliwościami Agenta, może stale próbować i popełniać błędy, aby zbiegać się do poprawnego rozwiązania. Warto również zauważyć, że podczas pracy programistycznej M2.5 "mówi" mniej, prawie tylko po ostatecznym zakończeniu pracy wypisuje krótkie podsumowanie, a nie wypisuje pomysłów w trakcie. Inne projekty inżynieryjne są nadal w fazie testów i zostaną zaktualizowane później.
- Zdolności obliczeniowe: Zdolności obliczeniowe M2 nie były wybitne, a M2.1 wręcz się pogorszył. M2.5 dokonał skutecznych ulepszeń na niskim poziomie. W większości prostych obliczeń M2.5 z małym prawdopodobieństwem osiąga wysoką precyzję, ale w większości przypadków nadal popełnia błędy, ma duże błędy i nie rozumie wzorów. Szkolenie w tym zakresie jest nadal niewystarczające. Jako model napędzany przez Agenta, zdolności obliczeniowe nie są koniecznością, a obliczenia serii Claude również od dawna pozostają w tyle.
Niedociągnięcia
- Przestrzeganie instrukcji: W porównaniu z M2, poprawa w przestrzeganiu instrukcji nie jest duża. Prawdopodobieństwo uzyskania maksymalnego wyniku w przypadku niektórych prostych problemów jest wyższe, ale nadal nie jest stabilne. Istnieją przypadki losowego odrzucania instrukcji lub ich modyfikowania, ale obserwując treść łańcucha myślowego, model zauważa wszystkie instrukcje, a problem pojawia się w ostatecznym wyniku. Ogólna wydajność jest gorsza od innych modeli z pierwszej ligi. W programowaniu występują również przypadki ignorowania wymagań kodowania i standardów projektowych, na przykład w projekcie C określono, że oś Z jest skierowana do góry, ale M2.5 samowolnie zmienił ją na oś Y, aby naprawić inny błąd. Podczas codziennego użytkowania należy zwrócić szczególną uwagę na kontrolę.
- Halucynacje: Poziom halucynacji M2.5 nie zmienił się znacząco w porównaniu z M2. W większości problemów związanych z kontekstem, oba modele mają identyczne graniczne wyniki. Nawet w #43 problemie z obliczaniem liczby docelowej, M2.5 popełnia również niskopoziomowe błędy, które popełniają modele z drugiej ligi, takie jak powtarzanie użycia liczb i pomijanie liczb.
Kronikarz Cybernetyczny mówi
Krajowi producenci spędzili ponad pół roku na badaniu, jak właściwie powinien wyglądać model programowania. Najwcześniejsze modele, które rzekomo miały zastąpić Sonnet, wydawały się zbliżone tylko pod względem efektu generowania "jednego zdania". Ich wewnętrzna organizacja kodu, inżynieria i, co ważniejsze, możliwości wielokrotnej iteracji są znacznie gorsze. To również sprawia, że krajowi programiści powszechnie nie ufają krajowym modelom i wolą używać Claude, ryzykując zablokowaniem konta.
Jednak wraz z tym, jak MiniMax M2 i M2.1 wstępnie odwróciły opinię, generacja M2.5 popchnęła użyteczność programowania krajowych modeli o krok do przodu. Rzeczywiście, M2.5 ma wszechstronną lukę w stosunku do poziomu Opus deklarowanego przez producenta, ale dopóki ktoś chce zaufać i używać, sprawy będą się rozwijać w dobrym kierunku. Z tej perspektywy M2.5 jest rzeczywiście solidnym krokiem, jaki 稀宇 podjął w kierunku zwycięskiego celu.



