Avaliação do MiniMax M2.5 da 稀宇 (Xiyu)
Avaliação do MiniMax M2.5 da 稀宇 (Xiyu)
Conclusão curta: Enraizar para baixo, crescer para cima
Informações básicas
A geração anterior do 稀宇 (Xiyu), o M2.1, devido a problemas técnicos, embora tenha apresentado um progresso significativo na programação, ficou aquém do M2 em termos de capacidade lógica. Felizmente, o M2.5 resolveu basicamente os problemas técnicos, e a capacidade retornou ao normal. Comparado ao M2, o progresso do M2.5 é de aproximadamente 17%.
No entanto, parte desse progresso é obtido por meio de cadeias de pensamento mais longas e exploração mais profunda do espaço de soluções. O consumo médio de Token do M2.5 está entre os 6 maiores de todos os modelos testados, quase o dobro do concorrente Sonnet. Felizmente, o poder computacional da 稀宇 (Xiyu) é garantido e o custo não é alto. Embora a programação não consiga substituir o Sonnet em todos os aspectos, o uso diário é totalmente viável. O M2.5 finalmente alcançou o objetivo que o M2.1 pretendia.
Desempenho lógico
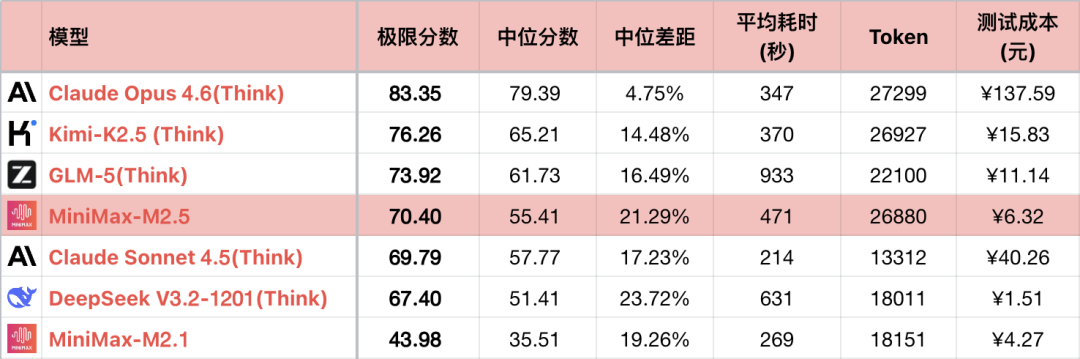
*1 A tabela exibe apenas parte dos modelos comparáveis para destacar as relações de comparação, não é uma classificação completa.
*2 Para as questões e métodos de teste, consulte: Avaliação Horizontal da Capacidade Lógica de Modelos de Linguagem Grandes - Ranking Mensal de Janeiro de 2026. Adicionada a questão #56.
*3 A lista completa é atualizada em https://llm2014.github.io/llm_benchmark/
*4 O vermelho é limitado ao período do Festival da Primavera, representando alegria, sem outro significado.
Como o M2.1 é uma versão com bugs e capacidade lógica excepcionalmente baixa, a comparação intergeracional abaixo será feita apenas entre o M2 e o M2.5.
Melhorias
- Inferência estável: O M2.5 pode manter as restrições iniciais e os detalhes do contexto durante processos de inferência mais longos. Portanto, em algumas questões que não são muito difíceis, mas exigem "foco", a pontuação do M2.5 melhorou significativamente. Por exemplo, na questão #4, Rotação do Cubo Mágico, o M2.5 é o 8º modelo global a obter pontuação máxima. No entanto, esse tipo de questão pode ser resolvida de forma estável com pontuação máxima pelos três grandes da América do Norte, enquanto o M2.5 só consegue acertar uma vez com baixa probabilidade, mostrando uma diferença significativa.
- Programação: Conforme mencionado anteriormente, o M2.5 não consegue substituir o Sonnet em todos os aspectos, principalmente devido à limitação da quantidade de conhecimento de programação. Em situações que exigem experiência, habilidades, diferenças de API de versão, etc., o M2.5 tem dificuldade em identificar problemas por conta própria sem dicas, geralmente exigindo várias rodadas para restringir gradualmente o problema. Mas isso já é um grande progresso em relação ao M2. No teste de projeto em C, a maioria dos modelos nacionais fica presa nas primeiras 2 rodadas, enquanto o M2.5 se tornou o primeiro modelo nacional a romper para a 8ª rodada. Embora o M2.5 tenha deficiências óbvias no uso de OpenGL e na imaginação espacial, com a capacidade de Agent otimizada, ele pode tentar e errar continuamente, convergindo para a solução correta. Além disso, vale a pena notar que, ao trabalhar em programação, o M2.5 "fala" menos, quase apenas produzindo um breve resumo após a conclusão final do trabalho, sem apresentar ideias no meio do caminho. Outros projetos ainda estão em teste e serão atualizados posteriormente.
- Capacidade de cálculo: A capacidade de cálculo do M2 não era excelente, e o M2.1 regrediu ainda mais. O M2.5 fez melhorias eficazes a partir de um ponto de partida baixo. Na maioria dos cálculos simples, o M2.5 tem uma pequena probabilidade de alta precisão, mas na maioria das vezes ainda existem erros de cálculo, grandes erros e problemas para entender as fórmulas. O treinamento nessa área ainda é insuficiente. Como um modelo orientado por Agent, a capacidade de cálculo não é uma necessidade absoluta, e o cálculo da série Claude também está atrasado há muito tempo.
Deficiências
- Seguimento de instruções: Comparado ao M2, o aumento no seguimento de instruções não é grande. A probabilidade de obter pontuação máxima em algumas questões simples é maior, mas também não é estável. Existem casos de descarte aleatório de instruções ou adulteração de instruções, mas observando o conteúdo da cadeia de pensamento, o modelo percebe todas as instruções, mas o resultado final apresenta problemas. O desempenho geral está atrás de outros modelos na primeira linha. Na programação, também há casos de desconsiderar os requisitos de codificação e as normas do projeto. Por exemplo, no projeto em C, foi estipulado que o eixo Z das coordenadas está para cima, mas o M2.5 mudou arbitrariamente para o eixo Y para corrigir outro bug. O uso diário requer atenção extra ao controle.
- Alucinações: O nível de alucinação do M2.5 não tem mudanças significativas em relação ao M2. Na maioria das questões relacionadas ao contexto, as pontuações máximas de ambos são consistentes. Mesmo na questão #43, Cálculo do número alvo, o M2.5 comete alguns erros básicos que apenas os modelos de segunda linha cometem, como usar números repetidamente e omitir números.
O Historiador Cibernético diz
Os fabricantes nacionais gastaram mais de meio ano explorando como os modelos de programação devem ser feitos. Os primeiros modelos que afirmavam ser substitutos do Sonnet pareciam próximos apenas no efeito de geração de "uma frase". Sua organização interna de código, engenharia e, mais importante, capacidade de iteração de várias rodadas estão muito aquém. Isso também faz com que os programadores nacionais geralmente não confiem nos modelos nacionais, preferindo usar o Claude, mesmo correndo o risco de ter suas contas bloqueadas.
Com o MiniMax M2 e M2.1 revertendo preliminarmente a reputação, a geração M2.5 avança a usabilidade da programação de modelos nacionais em um grande passo. De fato, o M2.5 ainda tem uma lacuna abrangente em relação ao nível Opus declarado oficialmente, mas enquanto houver alguém disposto a confiar e usar, as coisas se desenvolverão em uma direção melhor. Desta forma, o M2.5 é de fato um passo sólido que a 稀宇 (Xiyu) deu em direção ao objetivo da vitória.



