Recenzia modelu 稀宇 MiniMax M2.5
Recenzia modelu 稀宇 MiniMax M2.5
Stručný záver: Zakorenenie nadol, rast nahor
Základné informácie
Predošlá generácia modelu 稀宇 M2.1 mala kvôli technickým problémom, hoci dosiahla výrazný pokrok v programovaní, logické schopnosti zaostávali za modelom M2. Našťastie M2.5 v podstate vyriešil technické problémy a schopnosti sa vrátili do normálnych koľají. V porovnaní s M2 je pokrok M2.5 približne 17 %.
Časť pokroku je však dosiahnutá dlhšími reťazcami myslenia a hlbším skúmaním priestoru riešení. Priemerná spotreba Tokenov modelu M2.5 je 6. najvyššia spomedzi všetkých testovaných modelov, takmer dvojnásobná oproti konkurenčnému modelu Sonnet. Našťastie má 稀宇 zabezpečený výpočtový výkon a náklady nie sú vysoké. Hoci programovanie nedokáže úplne nahradiť Sonnet, na každodenné použitie je plne použiteľný. M2.5 nakoniec dosiahol cieľ, ktorý si M2.1 vytýčil.
Logické výsledky
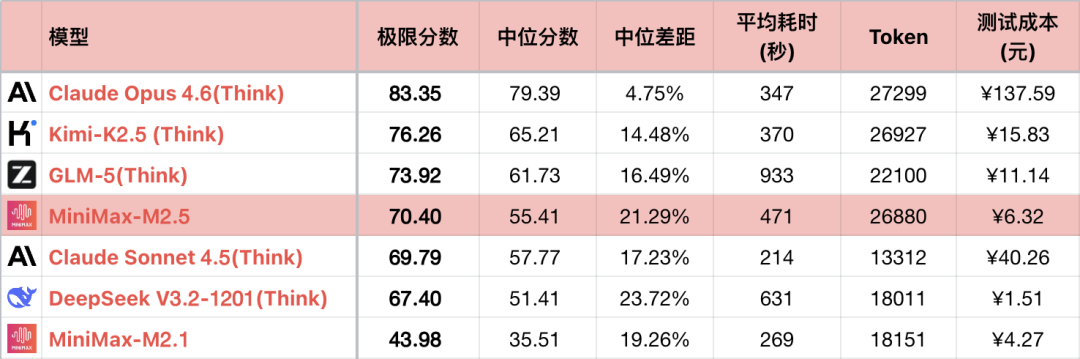
*1 Tabuľka zobrazuje iba časť porovnateľných modelov, nie je to úplné poradie, aby sa zdôraznil vzťah porovnania.
*2 Otázky a spôsob testovania, pozri: Veľké jazykové modely - horizontálne hodnotenie logických schopností 26-01 mesačný rebríček. Pridaná otázka #56.
*3 Kompletný rebríček je aktualizovaný na https://llm2014.github.io/llm_benchmark/
*4 Červená farba je obmedzená na obdobie jarných sviatkov, vyjadruje radosť a nemá iný význam.
Keďže M2.1 je verzia s chybami a abnormálne nízkymi logickými schopnosťami, nasledujúci text bude obsahovať iba medzigeneračné porovnanie M2 a M2.5.
Vylepšenia
- Stabilné usudzovanie: M2.5 dokáže udržať počiatočné obmedzenia a kontextové detaily počas dlhšieho procesu usudzovania, takže v niektorých problémoch, ktoré nie sú príliš náročné, ale vyžadujú si „sústredenie“, dosahuje M2.5 výrazne lepšie skóre. Napríklad #4 Rotácia kocky, M2.5 je 8. model na svete, ktorý získal plný počet bodov. Ale takéto problémy dokáže severoamerická „veľká trojka“ stabilne vyriešiť na plný počet bodov, zatiaľ čo M2.5 to dokáže len s malou pravdepodobnosťou, rozdiel je zrejmý.
- Programovanie: Ako už bolo spomenuté, M2.5 nedokáže komplexne nahradiť Sonnet, hlavne kvôli obmedzeným znalostiam programovania. V situáciách, ktoré si vyžadujú skúsenosti, zručnosti, rozdiely vo verziách API atď., M2.5 bez nápovedy ťažko sám zistí problém a zvyčajne potrebuje niekoľko kôl na postupné zúženie problému. Ale to je už obrovský pokrok oproti M2. V testovaní C projektov väčšina čínskych modelov uviazne v prvých 2 kolách, zatiaľ čo M2.5 sa stal prvým čínskym modelom, ktorý sa prebojoval do 8. kola. Hoci má M2.5 zjavné nedostatky v používaní OpenGL a priestorovej predstavivosti, v kombinácii s optimalizovanými schopnosťami Agenta dokáže neustále skúšať a mýliť sa, až kým sa nedopracuje k správnemu riešeniu. Okrem toho stojí za zmienku, že M2.5 pri programovaní „hovorí“ menej, takmer len po dokončení práce vypíše stručné zhrnutie, neposkytuje priebežné myšlienky. Ostatné projekty sa ešte testujú a budú aktualizované neskôr.
- Výpočtová schopnosť: Výpočtová schopnosť M2 nebola vynikajúca a M2.1 sa ešte zhoršil. M2.5 dosiahol efektívne zlepšenie na nízkej úrovni. Vo väčšine jednoduchých výpočtov má M2.5 s malou pravdepodobnosťou vysokú presnosť, vo väčšine prípadov stále existujú chyby vo výpočtoch, veľké chyby a nepochopenie vzorcov, v tejto oblasti je stále nedostatok tréningu. Ako model riadený Agentom nie je výpočtová schopnosť nevyhnutná, výpočty série Claude tiež dlhodobo zaostávajú.
Nedostatky
- Dodržiavanie inštrukcií: V porovnaní s M2 nie je zlepšenie v dodržiavaní inštrukcií veľké, pravdepodobnosť získania plného počtu bodov v niektorých jednoduchých problémoch je vyššia, ale ani to nie je stabilné. Existujú prípady náhodného vynechania inštrukcií alebo pozmenenia inštrukcií, ale pri pozorovaní obsahu reťazca myslenia si model všimol všetky inštrukcie, ale nakoniec sa vyskytol problém s výstupom. Celkový výkon zaostáva za ostatnými modelmi v prvej skupine. V programovaní sa tiež vyskytujú prípady ignorovania požiadaviek na kódovanie a projektových noriem, napríklad v C projekte je stanovené, že os Z smeruje nahor, ale M2.5 ju svojvoľne zmenil na os Y, aby opravil inú chybu. Pri každodennom používaní je potrebné venovať zvýšenú pozornosť kontrole.
- Halucinácie: Úroveň halucinácií M2.5 sa v porovnaní s M2 výrazne nezmenila, vo väčšine problémov súvisiacich s kontextom je maximálne skóre oboch rovnaké. Dokonca aj v probléme #43 s výpočtom cieľového čísla sa M2.5 dopúšťa nízkoúrovňových chýb, ktoré sa vyskytujú len u modelov druhej skupiny, ako je opakované používanie čísel a vynechávanie čísel.
Kybernetický historik hovorí
Domáci výrobcovia strávili viac ako pol roka skúmaním, ako by sa mali robiť programovacie modely. Prvé modely, ktoré sa nazývali rovnocennou náhradou za Sonnet, sa zdali byť podobné len v efektoch generovania „jednej vety“. Ich vnútorná organizácia kódu, inžinierstvo a, čo je dôležitejšie, schopnosť viacnásobnej iterácie sú oveľa horšie. To tiež spôsobuje, že domáci programátori vo všeobecnosti nedôverujú domácim modelom a radšej používajú Claude s rizikom zablokovania účtu.
S tým, ako MiniMax M2 a M2.1 predbežne zvrátili verejnú mienku, generácia M2.5 posunula použiteľnosť domáceho programovania o krok vpred. Je pravda, že M2.5 má stále komplexné rozdiely od úrovne Opus, ktorú oficiálne deklaruje, ale pokiaľ je niekto ochotný veriť a používať ho, veci sa budú vyvíjať k lepšiemu. Z tohto pohľadu je M2.5 skutočne pevným krokom, ktorý 稀宇 urobil smerom k víťaznému cieľu.



