稀宇 MiniMax M2.5 Recension
稀宇 MiniMax M2.5 Recension
Kort slutsats: Rötter nedåt, växt uppåt
Grundläggande information
稀宇s föregående generation M2.1 hade tekniska problem, vilket ledde till betydande framsteg inom programmering, men logiska förmågor halkade efter M2. Lyckligtvis har M2.5 i princip löst de tekniska problemen och förmågan är tillbaka på rätt spår. Jämfört med M2 är M2.5 cirka 17% bättre.
En del av framstegen beror dock på längre tankekedjor och djupare utforskning av lösningsutrymmet. M2.5:s genomsnittliga Token-förbrukning är den 6:e högsta av alla modeller som testas, nästan dubbelt så hög som konkurrenten Sonnet. Lyckligtvis är 稀宇s beräkningskraft garanterad och kostnaden är inte hög. Även om programmeringen inte kan ersätta Sonnet helt och hållet, är den fullt användbar för dagligt bruk. M2.5 uppnådde slutligen det mål som M2.1 ville uppnå.
Logiska resultat
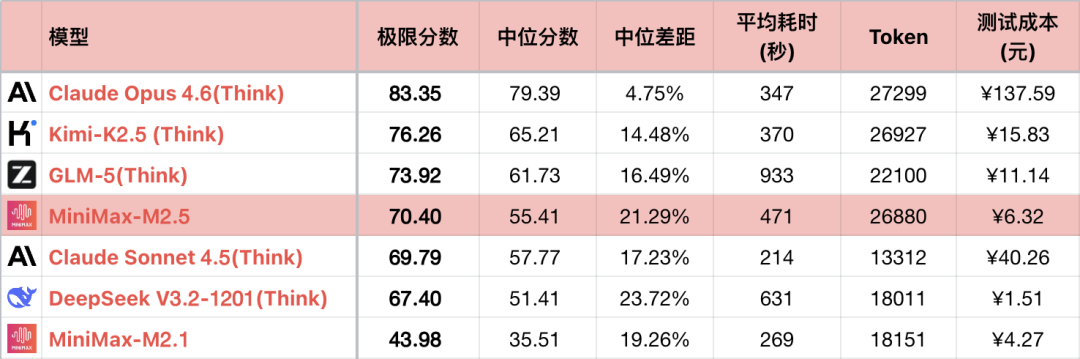
*1 Tabellen visar endast en del av de jämförbara modellerna för att framhäva jämförelsen, inte en fullständig sortering.
*2 För frågor och testmetoder, se: Stora språkmodeller - Logisk förmåga jämförelse 26-01 månadslista. Nytt #56 fråga.
*3 Fullständig lista uppdateras på https://llm2014.github.io/llm_benchmark/
*4 Rött är begränsat till vårfestivalen, vilket indikerar festlighet och har ingen annan betydelse.
Eftersom M2.1 är en version med buggar och onormalt låg logisk förmåga, kommer följande endast att göra en generationsöverskridande jämförelse mellan M2 och M2.5.
Förbättringar
- Stabil inferens: M2.5 kan behålla initiala begränsningar och kontextuella detaljer under längre inferensprocesser, så vissa problem som inte är särskilt svåra men kräver "fokus" får betydligt högre poäng av M2.5. Till exempel #4 Rubiks kub-rotation, M2.5 är den 8:e modellen i världen som får full poäng. Men den här typen av problem kan de tre stora nordamerikanska företagen stabilt få full poäng, medan M2.5 bara kan få det en gång med låg sannolikhet, vilket visar en tydlig skillnad.
- Programmering: Som nämnts tidigare kan M2.5 inte ersätta Sonnet helt och hållet, främst på grund av begränsningar i programmeringskunskaper. I situationer som kräver erfarenhet, färdigheter, API-skillnader mellan versioner etc. är det svårt för M2.5 att upptäcka problem på egen hand utan ledtrådar. Det krävs vanligtvis flera omgångar för att gradvis minska problemet. Men detta är redan en stor förbättring jämfört med M2. I C-projektets tester kommer de flesta inhemska modeller att fastna i de första 2 omgångarna, medan M2.5 är den första inhemska modellen som bryter igenom till den 8:e omgången. Även om M2.5 har tydliga brister i OpenGL-användning och rumslig fantasi, kan den, i kombination med optimerade Agent-förmågor, kontinuerligt prova och konvergera till rätt lösning. Det är också värt att notera att M2.5 "pratar" mindre när den arbetar med programmering, och nästan bara ger en kort sammanfattning efter att ha slutfört arbetet, och inte ger några tankar under processen. Andra projekt testas fortfarande och kommer att uppdateras senare.
- Beräkningsförmåga: M2:s beräkningsförmåga är inte särskilt bra, och M2.1 är ännu sämre. M2.5 har gjort effektiva förbättringar från en låg utgångspunkt. I de flesta enkla beräkningar har M2.5 en liten sannolikhet för hög precision, men i de flesta fall finns det fortfarande felberäkningar, stora fel och oförmåga att förstå formler. Utbildningen inom detta område är fortfarande otillräcklig. Som en Agent-driven modell är beräkningsförmåga inte ett måste, och Claude-seriens beräkningar har också länge halkat efter.
Brister
- Instruktionsföljande: Jämfört med M2 är förbättringen av instruktionsföljande inte stor. Sannolikheten att få full poäng på vissa enkla problem är högre, men det är inte heller stabilt. Det finns fall av slumpmässigt borttagande eller ändring av instruktioner, men genom att observera tankekedjans innehåll har modellen noterat alla instruktioner, men det finns problem med den slutliga utgången. Den totala prestandan ligger efter andra modeller i den första nivån. I programmering finns det också fall av att ignorera kodningskrav och projektstandarder. Till exempel, i C-projektet, föreskrivs att Z-axeln ska vara uppåt, men M2.5 ändrade den godtyckligt till Y-axeln uppåt för att fixa en annan bugg. Ytterligare kontroll krävs vid daglig användning.
- Hallucinationer: M2.5:s hallucinationsnivå har inte förändrats signifikant jämfört med M2. I de flesta kontextrelaterade problem är de maximala poängen desamma för båda. Till och med i #43 målräkningsproblem kommer M2.5 att göra några låga misstag som att upprepade gånger använda siffror eller missa siffror, vilket andra nivåns modeller skulle göra.
Cyberhistorikern säger
Inhemska tillverkare har spenderat mer än ett halvår på att utforska hur programmeringsmodeller ska göras. De tidigaste modellerna som påstods vara en billigare ersättning för Sonnet såg mestadels liknande ut i "en mening" generations effekter. Deras interna kodorganisation, konstruktion och, ännu viktigare, förmågan till flera iterationer är långt ifrån lika bra. Detta har också gjort att inhemska programmerare i allmänhet misstror inhemska modeller och hellre tar risken att få sina konton avstängda än att använda Claude.
Medan MiniMax M2 och M2.1 preliminärt vände opinionen, tar M2.5-generationen inhemsk programmeringsanvändbarhet ett stort steg framåt. Visst, M2.5 har fortfarande en allsidig skillnad jämfört med den officiellt deklarerade Opus-nivån, men så länge någon är villig att lita på och använda den kommer saker och ting att utvecklas i en positiv riktning. Ur detta perspektiv är M2.5 verkligen ett fast steg som 稀宇 har tagit mot seger.



