Огляд 稀宇 MiniMax M2.5
Огляд 稀宇 MiniMax M2.5
Короткий висновок: Корінням вниз, вгору зростання
Основна інформація
Попереднє покоління 稀宇 M2.1 через технічні проблеми, хоча й досягло значного прогресу в програмуванні, але логічні здібності відставали від M2. На щастя, M2.5 в основному вирішив технічні проблеми, і здібності повернулися до нормального рівня. Порівняно з M2, прогрес M2.5 становить приблизно 17%.
Однак частина прогресу досягнута за рахунок довших ланцюжків мислення та глибшого дослідження простору рішень. Середнє споживання токенів M2.5 займає 6-те місце серед усіх протестованих моделей, що майже вдвічі більше, ніж у конкурента Sonnet. На щастя, обчислювальні потужності 稀宇 гарантовані, а вартість невисока. Хоча програмування не може повністю замінити Sonnet, для щоденного використання воно цілком придатне. M2.5 нарешті досяг цілей, які ставив перед собою M2.1.
Логічні результати
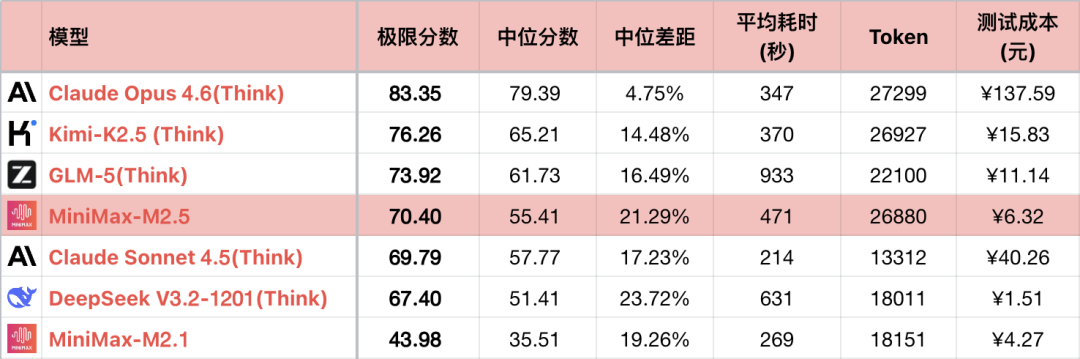
*1 Щоб підкреслити порівняння, таблиця показує лише частину порівнюваних моделей, а не повне сортування.
*2 Завдання та методи тестування див.: Велика мовна модель - Порівняльна оцінка логічних здібностей, місячний рейтинг 26-01. Додано завдання #56.
*3 Повний список оновлюється на https://llm2014.github.io/llm_benchmark/
*4 Червоний колір обмежений періодом Китайського Нового року, що символізує радість і не має іншого значення.
Оскільки M2.1 є версією з помилками та надзвичайно низькими логічними здібностями, нижче буде наведено лише порівняння між поколіннями M2 та M2.5.
Покращення
- Стабільне міркування: M2.5 може підтримувати початкові обмеження та контекстні деталі протягом тривалішого процесу міркування, тому деякі нескладні, але такі, що вимагають "зосередженості", завдання, M2.5 виконує значно краще. Наприклад, #4 Обертання кубика Рубіка, M2.5 є 8-ю моделлю у світі, яка отримала максимальний бал. Але в таких завданнях північноамериканська "велика трійка" може стабільно отримувати максимальні бали, тоді як M2.5 може це зробити лише з невеликою ймовірністю, що свідчить про значну різницю.
- Програмування: Як згадувалося вище, M2.5 не може повністю замінити Sonnet, головним чином через обмеженість знань у програмуванні. У випадках, коли потрібен досвід, навички, відмінності версій API тощо, M2.5 важко самостійно виявити проблему без підказок, і зазвичай потрібно кілька раундів, щоб поступово звузити проблему. Але це вже великий прогрес порівняно з M2. У тесті C-проєкту більшість китайських моделей застряють на перших 2 раундах, тоді як M2.5 став першою китайською моделлю, яка прорвалася до 8-го раунду. Хоча M2.5 має очевидні недоліки у використанні OpenGL та просторовій уяві, у поєднанні з оптимізованими можливостями Agent, він може постійно пробувати та помилятися, сходячись до правильного рішення. Також варто зазначити, що під час програмування M2.5 "говорить" менше, майже лише після завершення роботи виводить короткий підсумок, не виводячи міркування в середині процесу. Інші проєкти ще тестуються, оновлення будуть пізніше.
- Обчислювальні здібності: Обчислювальні здібності M2 не можна назвати видатними, а M2.1 ще більше погіршився. M2.5 досяг ефективного прогресу з низької відправної точки. У більшості простих обчислень M2.5 з невеликою ймовірністю демонструє високу точність, але в більшості випадків все ще трапляються помилки, великі похибки та нерозуміння формул. Навчання в цій галузі все ще недостатнє. Як модель, керована Agent, обчислювальні здібності не є абсолютно необхідними, і обчислення Claude серії також тривалий час відставали.
Недоліки
- Дотримання інструкцій: Порівняно з M2, покращення дотримання інструкцій невелике. Ймовірність отримання максимального балу за деякі прості завдання вища, але все ще нестабільна. Існують випадки випадкового відкидання або зміни інструкцій, але, спостерігаючи за вмістом ланцюжка мислення, модель помічає всі інструкції, але в кінцевому виводі виникають проблеми. Загальна продуктивність відстає від інших моделей першого ешелону. У програмуванні також трапляються випадки ігнорування вимог до кодування та специфікацій проєкту. Наприклад, у C-проєкті зазначено, що вісь Z спрямована вгору, але M2.5 самовільно змінив її на вісь Y, щоб виправити іншу помилку. Під час щоденного використання потрібно приділяти додаткову увагу контролю.
- Галюцинації: Рівень галюцинацій M2.5 суттєво не змінився порівняно з M2. У більшості контекстно-залежних завданнях граничні бали обох моделей однакові. Навіть у завданні #43 Обчислення цільової кількості M2.5 все ще робить деякі низькорівневі помилки, які трапляються лише у моделей другого ешелону, наприклад, повторне використання чисел або пропуск чисел.
Кібер-історик каже
Китайські виробники витратили пів року на дослідження того, як саме слід створювати моделі програмування. Найперші моделі, які називали себе альтернативою Sonnet, лише наближалися до неї за ефектом генерації "одного речення". Їх внутрішня організація коду, інженерія та, що важливіше, можливості багаторазової ітерації значно поступаються. Це також змушує китайських програмістів загалом не довіряти китайським моделям і воліють використовувати Claude, навіть ризикуючи блокуванням облікового запису.
Але з тим, як MiniMax M2, M2.1 попередньо змінили репутацію, M2.5 просуває корисність китайського програмування на крок вперед. Дійсно, M2.5 все ще має всебічну різницю з заявленим офіційним рівнем Opus, але поки є люди, які готові довіряти та використовувати, все буде рухатися в кращому напрямку. З цієї точки зору, M2.5 дійсно є твердим кроком 稀宇 до перемоги.



