Đánh giá MiniMax M2.5 của Shiyu
Đánh giá MiniMax M2.5 của Shiyu
Kết luận ngắn gọn: Bám rễ sâu, vươn mình lên cao
Tình hình cơ bản
M2.1 thế hệ trước của Shiyu do vấn đề kỹ thuật, mặc dù có tiến bộ đáng kể về lập trình, nhưng khả năng logic lại tụt hậu so với M2. May mắn thay, M2.5 về cơ bản đã giải quyết được các vấn đề kỹ thuật và khả năng đã trở lại quỹ đạo bình thường. So với M2, sự tiến bộ của M2.5 là khoảng 17%.
Tuy nhiên, một phần tiến bộ có được là nhờ chuỗi suy nghĩ dài hơn và khám phá không gian giải pháp sâu hơn. Mức tiêu thụ Token trung bình của M2.5 đứng thứ 6 trong tất cả các mô hình đang thử nghiệm, gần gấp đôi so với đối thủ Sonnet. May mắn thay, sức mạnh tính toán của Shiyu được đảm bảo và chi phí không cao. Mặc dù khả năng lập trình không thể thay thế Sonnet một cách hoàn hảo, nhưng nó hoàn toàn có thể sử dụng được trong sử dụng hàng ngày. M2.5 cuối cùng đã đạt được mục tiêu mà M2.1 muốn đạt được.
Thành tích logic
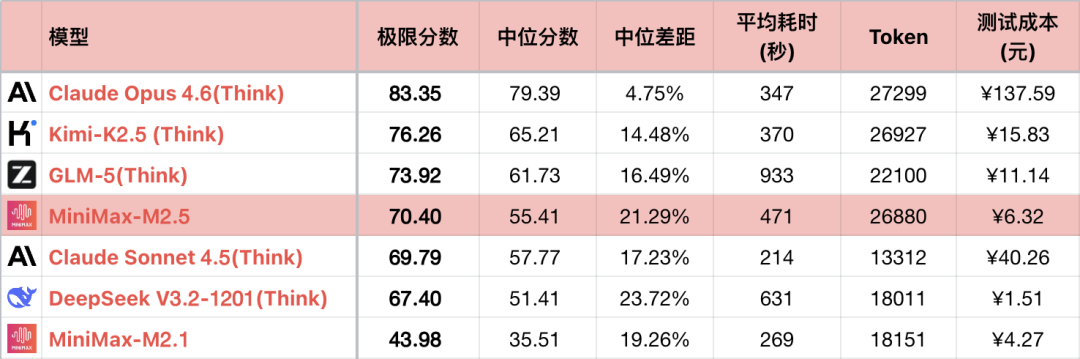
*1 Để làm nổi bật mối quan hệ so sánh, bảng chỉ hiển thị một phần các mô hình có thể so sánh được, không phải là sắp xếp đầy đủ.
*2 Câu hỏi và phương pháp kiểm tra, xem: Đánh giá ngang khả năng logic của mô hình ngôn ngữ lớn - Bảng xếp hạng tháng 1 năm 26. Đã thêm câu hỏi #56.
*3 Bảng xếp hạng đầy đủ được cập nhật tại https://llm2014.github.io/llm_benchmark/
*4 Màu đỏ chỉ dành riêng cho dịp Tết Nguyên đán, tượng trưng cho sự vui vẻ, không có ý nghĩa nào khác.
Vì M2.1 là một phiên bản có lỗi (Bug), khả năng logic đặc biệt thấp, nên phần dưới đây chỉ so sánh giữa M2 và M2.5.
Cải tiến
- Suy luận ổn định: M2.5 có thể duy trì các ràng buộc ban đầu và chi tiết ngữ cảnh trong quá trình suy luận dài hơn, do đó, một số vấn đề không quá khó nhưng đòi hỏi sự "tập trung", điểm số của M2.5 đã được cải thiện đáng kể. Ví dụ: #4 Xoay Rubik, M2.5 là mô hình thứ 8 trên thế giới đạt điểm tuyệt đối. Nhưng đối với những vấn đề như vậy, bộ ba Bắc Mỹ có thể đạt điểm tuyệt đối một cách ổn định, trong khi M2.5 chỉ có thể đúng một lần với xác suất nhỏ, sự khác biệt là rõ ràng.
- Lập trình: Như đã đề cập trước đó, M2.5 không thể thay thế Sonnet một cách toàn diện, chủ yếu là do kiến thức lập trình hạn chế. Trong những trường hợp cần kinh nghiệm, kỹ năng, sự khác biệt về API phiên bản, v.v., M2.5 khó tự mình phát hiện ra vấn đề nếu không có gợi ý, thường cần nhiều vòng để thu hẹp dần vấn đề. Nhưng điều này đã là một bước tiến lớn so với M2. Trong thử nghiệm dự án C, hầu hết các mô hình trong nước sẽ bị mắc kẹt trong 2 vòng đầu tiên, trong khi M2.5 trở thành mô hình trong nước đầu tiên đột phá đến vòng thứ 8. Mặc dù M2.5 có những thiếu sót rõ ràng trong việc sử dụng OpenGL và trí tưởng tượng không gian, nhưng với khả năng Agent được tối ưu hóa, nó có thể liên tục thử và sai, hội tụ về giải pháp đúng. Ngoài ra, điều đáng chú ý là khi M2.5 làm việc lập trình, nó "nói" ít hơn, hầu như chỉ đưa ra một bản tóm tắt ngắn gọn sau khi hoàn thành công việc cuối cùng, và không đưa ra ý tưởng trong quá trình này. Các dự án khác vẫn đang được thử nghiệm và sẽ được cập nhật sau.
- Khả năng tính toán: Khả năng tính toán của M2 không được coi là xuất sắc, và M2.1 thậm chí còn thụt lùi. M2.5 đã có những cải tiến hiệu quả trên một điểm khởi đầu thấp. Trong hầu hết các phép tính đơn giản, M2.5 có xác suất nhỏ cho độ chính xác cao, nhưng trong hầu hết các trường hợp vẫn có sai sót, sai số lớn và không hiểu công thức. Việc đào tạo về mặt này vẫn chưa đủ. Là một mô hình được điều khiển bởi Agent, khả năng tính toán không phải là một nhu cầu thiết yếu, và khả năng tính toán của dòng Claude cũng tụt hậu trong một thời gian dài.
Thiếu sót
- Tuân thủ hướng dẫn: So với M2, mức tăng tuân thủ hướng dẫn không lớn. Xác suất đạt điểm tuyệt đối cho một số vấn đề đơn giản cao hơn, nhưng cũng không thể ổn định. Có trường hợp ngẫu nhiên loại bỏ hoặc sửa đổi hướng dẫn, nhưng quan sát nội dung chuỗi suy nghĩ, mô hình đã chú ý đến tất cả các hướng dẫn, nhưng đầu ra cuối cùng lại có vấn đề. Hiệu suất tổng thể tụt hậu so với các mô hình khác trong nhóm đầu tiên. Trong lập trình, cũng có trường hợp bỏ qua các yêu cầu mã hóa và quy tắc dự án, ví dụ: dự án C quy định trục Z hướng lên trên, nhưng M2.5 đã tự ý thay đổi thành trục Y hướng lên trên để sửa một lỗi (Bug) khác. Cần đặc biệt chú ý đến việc kiểm soát trong sử dụng hàng ngày.
- Ảo giác: Mức độ ảo giác của M2.5 không có thay đổi đáng kể so với M2. Điểm số giới hạn của cả hai là như nhau đối với hầu hết các vấn đề liên quan đến ngữ cảnh. Thậm chí trong vấn đề tính toán số mục tiêu #43, M2.5 còn mắc phải một số lỗi sơ đẳng mà các mô hình nhóm thứ hai mới mắc phải, chẳng hạn như sử dụng lại số và bỏ sót số.
Nhà sử học mạng nói
Các nhà sản xuất trong nước đã dành hơn nửa năm để khám phá cách tạo ra một mô hình lập trình. Các mô hình đầu tiên được cho là thay thế Sonnet, hầu hết chỉ gần giống về hiệu ứng tạo "một câu". Tổ chức mã, kỹ thuật và khả năng lặp lại nhiều vòng quan trọng hơn nhiều đều kém xa. Điều này cũng khiến các lập trình viên trong nước nói chung không tin tưởng vào các mô hình trong nước và thà chấp nhận rủi ro bị cấm tài khoản để sử dụng Claude.
Và khi MiniMax M2, M2.1 bước đầu đảo ngược dư luận, thế hệ M2.5 này đã đưa khả năng sử dụng lập trình của các mô hình trong nước tiến thêm một bước lớn. Quả thực, M2.5 vẫn còn khoảng cách toàn diện so với trình độ Opus mà nhà sản xuất tuyên bố, nhưng chỉ cần có người sẵn sàng tin tưởng và sử dụng, mọi thứ sẽ phát triển theo hướng tốt đẹp. Từ đó có thể thấy, M2.5 thực sự là một bước đi vững chắc mà Shiyu đã thực hiện để hướng tới mục tiêu chiến thắng.



