OpenClaw + Claude Code Super Tutorial: Ein Einzelner kann ein komplettes Entwicklungsteam aufbauen!
OpenClaw + Claude Code Super Tutorial: Ein Einzelner kann ein komplettes Entwicklungsteam aufbauen!
Heute teile ich ein beeindruckendes Praxisbeispiel. (Am Ende des Artikels ist ein Tutorial angehängt)
Ein unabhängiger Entwickler hat mit OpenClaw + Codex/CC ein AI-Agent-System aufgebaut. Was hat er damit erreicht?
An einem Tag 94 Commits, 30 Minuten für 7 PRs, und an diesem Tag hatte er auch 3 Kundenmeetings, ohne den Editor jemals geöffnet zu haben.
Das ist tatsächlich im Januar 2026 passiert. Der Autor hat die gesamte Systemarchitektur, den Workflow und die Codekonfiguration veröffentlicht. Nachdem ich das gesehen habe, fand ich diesen Ansatz sehr lehrreich und habe ihn in diesem Artikel für dich zusammengefasst.
Wenn du auch Codex oder Claude Code verwendest oder an OpenClaw interessiert bist, wird dir dieser Artikel viele Inspirationen geben.
Ein Einzelner, 94 Code-Commits an einem Tag
Schauen wir uns ein paar Daten an, um die Macht dieses Systems zu spüren:
- Höchstens 94 Commits an einem Tag (durchschnittlich 50 Commits pro Tag)
- 7 PRs in 30 Minuten abgeschlossen
- Die Geschwindigkeit von der Idee bis zur Bereitstellung ist so schnell, dass man "Kundenanforderungen am selben Tag liefern" kann.
Und die Kosten? 190 $ pro Monat (Claude 100 $ + Codex 90 $), ein Anfänger kann mit 20 $ starten.
Du fragst dich vielleicht: Ist das nicht nur eine Ansammlung von AI-Tools, die dann wahllos Müllcode generieren?
Nein. Die Git-Historie des Autors sieht aus wie "gerade ein Entwicklerteam eingestellt", aber in Wirklichkeit ist er allein. Der entscheidende Wandel ist: Er hat von "Claude Code verwalten" zu "einem AI-Butler verwalten, der dann eine Gruppe von Claude Code verwaltet" gewechselt.
- Vor Januar: Direkt mit Codex oder Claude Code Code schreiben
- Nach Januar: OpenClaw als Orchestrierungsschicht verwenden, um Codex/Claude Code/Gemini zu steuern
Warum ist Codex und Claude Code allein nicht gut genug?
An diesem Punkt fragst du dich vielleicht: Codex und Claude Code sind bereits sehr leistungsfähig, warum also noch eine Orchestrierungsebene hinzufügen?
Die Antwort des Autors ist sehr direkt: Codex und Claude Code wissen fast nichts über dein Geschäft. Sie sehen nur den Code, nicht das vollständige Geschäftsszenario.
Hier gibt es eine grundlegende Einschränkung: Das Kontextfenster ist fest, du kannst nur eines von zwei wählen.
Du musst entscheiden, was du hineinstecken möchtest:
- Voll mit Code → Kein Platz für Geschäftskontext
- Voll mit Kundenhistorie → Kein Platz für das Code-Repository
- Es weiß nicht, für welchen Kunden diese Funktion erstellt wird
- Es weiß nicht, warum die letzte ähnliche Anfrage gescheitert ist
- Es weiß nicht, wie deine Produktpositionierung und Designprinzipien sind
- Es kann nur basierend auf dem aktuellen Code und deinem Prompt arbeiten
Es fungiert als Orchestrierungsschicht, die zwischen dir und allen AI-Tools steht. Seine Rolle ist:
- Alle Geschäftskontexte zu halten (Kundendaten, Besprechungsprotokolle, historische Entscheidungen, Erfolgs-/Misserfolgsgeschichten)
- Den Geschäftskontext in präzise Prompts zu übersetzen und an spezifische Agenten weiterzugeben
- Diese Agenten darauf zu konzentrieren, was sie am besten können: Code schreiben
- Codex/Claude Code = Professionelle Köche, die sich nur um das Kochen kümmern
- OpenClaw = Küchenchef, der den Geschmack der Kunden, den Vorrat an Zutaten und die Menüpositionierung kennt und jedem Koch präzise Anweisungen gibt
Die spezifische Architektur des zweischichtigen Systems: Orchestrierungsschicht + Ausführungsschicht
Lass uns die spezifische Architektur dieses Systems ansehen.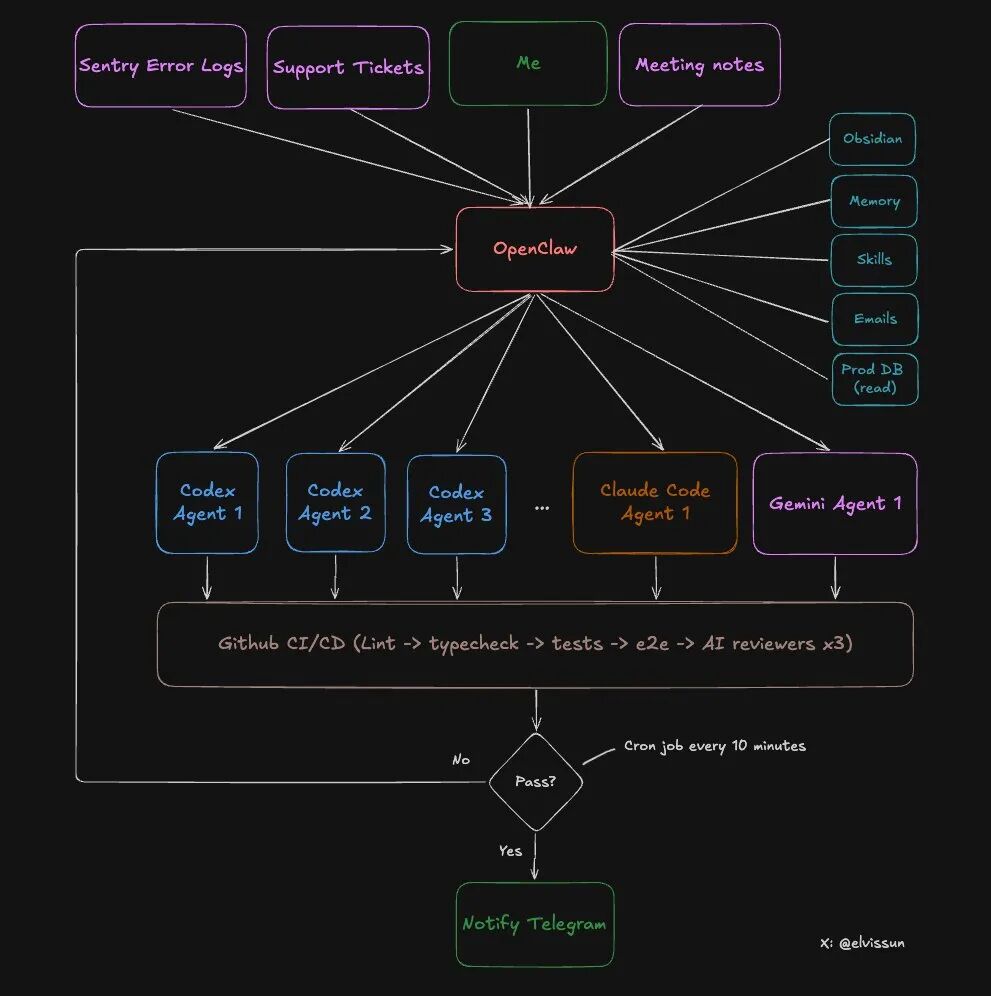
Zwei Schichten, jede mit ihrer eigenen Aufgabe:

Was kann OpenClaw (Orchestrierungsschicht) tun?
- Alle Besprechungsprotokolle aus den Obsidian-Notizen lesen (automatische Synchronisierung)
- Auf die Produktionsdatenbank zugreifen (nur Leserechte), um Kundenkonfigurationen zu erhalten
- Hat Administrator-API-Rechte, kann direkt Kunden aufladen und Blockaden aufheben
- Wählt den geeigneten Agenten basierend auf dem Aufgabentyp aus
- Überwacht den Fortschritt aller Agenten, analysiert bei Fehlern die Ursachen und passt die Eingabeaufforderung für einen erneuten Versuch an
- Benachrichtigt den Autor über Telegram, wenn die Aufgabe abgeschlossen ist
Was kann der Agent (Ausführungsschicht) tun?
- Code-Repository lesen und schreiben
- Tests und Builds ausführen
- Code einreichen und PR erstellen
- Auf Feedback zur Code-Überprüfung reagieren

Dieses Design ist clever: Die Sicherheitsgrenzen sind klar, während die Effizienz gewährleistet bleibt.
Vollständiger Workflow: 8 Schritte vom Kundenbedarf zur PR-Zusammenführung
Jetzt kommen wir zum Kernbereich. Anhand eines echten Beispiels des Autors aus der letzten Woche führen wir dich durch den vollständigen Prozess.
Hintergrund: Ein Unternehmenskunde ruft an und sagt, dass er die bereits konfigurierten Einstellungen wiederverwenden möchte, um sie im Team zu teilen.
Schritt 1: Kundenbedarf → OpenClaw versteht und zerlegt
Nach dem Telefonat hat der Autor mit Zoe (seinem OpenClaw) über diesen Bedarf gesprochen.
Das Erstaunliche hier: Null Erklärkosten. Da alle Besprechungsprotokolle automatisch mit Obsidian synchronisiert werden, hat Zoe bereits den Inhalt des Anrufs gelesen, weiß, wer der Kunde ist, welches Geschäftsszenario er hat und welche Konfigurationen vorhanden sind.
Der Autor und Zoe haben den Bedarf in folgende Punkte zerlegt: Ein Vorlagensystem erstellen, das es dem Benutzer ermöglicht, bestehende Konfigurationen zu speichern und zu bearbeiten.
Dann hat Zoe drei Dinge getan:
- Kunden aufladen – mit der Administrator-API sofort die Nutzungseinschränkung des Kunden aufheben
- Kundenkonfiguration abrufen – bestehende Einstellungen des Kunden aus der Produktionsdatenbank (nur Leserechte) abrufen
- Eingabeaufforderung generieren und Agenten starten – alle Kontexte bündeln und Codex füttern
Schritt 2: Agenten starten
Zoe hat für diese Aufgabe erstellt:
- Ein unabhängiges git worktree (isolierte Branch-Umgebung)
- Eine tmux-Sitzung (damit der Agent im Hintergrund läuft)
# 创建 worktree + 启动代理 git worktree add ../feat-custom-templates -b feat/custom-templates origin/main cd ../feat-custom-templates && pnpm install
tmux new-session -d -s "codex-templates" \ -c "/Users/elvis/Documents/GitHub/medialyst-worktrees/feat-custom-templates" \ "$HOME/.codex-agent/run-agent.sh templates gpt-5.3-codex high Warum tmux verwenden? Weil man während des Prozesses eingreifen kann.
Wenn die KI vom Kurs abkommt, muss man nicht alles neu starten, sondern kann direkt im tmux Befehle eingeben:
# 代理方向错了 tmux send-keys -t codex-templates "停一下。先做 API 层,别管 UI。" Enter
代理需要更多上下文
tmux send-keys -t codex-templates "类型定义在 src/types/template.ts,用那个。" Enter Gleichzeitig wird die Aufgabe in einer JSON-Datei protokolliert: { "id": "feat-custom-templates", "tmuxSession": "codex-templates", "agent": "codex", "description": "Funktion für benutzerdefinierte E-Mail-Vorlagen für Unternehmenskunden", "repo": "medialyst", "worktree": "feat-custom-templates", "branch": "feat/custom-templates", "startedAt": 1740268800000, "status": "running", "notifyOnComplete": true}
Schritt 3: Automatische Überwachung
Ein Cron-Job überprüft alle 10 Minuten den Status aller Agenten.
Wichtig: Es wird nicht "gefragt", wie der Fortschritt des Agenten ist (das würde viele Tokens kosten), sondern es werden objektive Fakten überprüft:
- Ist die tmux-Sitzung noch aktiv?
- Wurde ein PR erstellt?
- Wie ist der CI-Status?
- Wenn es fehlgeschlagen ist, muss neu gestartet werden? (maximal 3 Versuche)
Das ist eigentlich eine verbesserte Version der Ralph-Schleife, die später ausführlicher behandelt wird.
Schritt 4: Agent erstellt PR
Der Agent schreibt den Code, reicht ihn ein, pusht ihn und erstellt dann mit gh pr create --fill einen PR.
Hinweis: Zu diesem Zeitpunkt erhält der Autor keine Benachrichtigung. Denn ein PR selbst bedeutet nicht "fertig".
Die Definition von "fertig" ist:
- ✅ PR wurde erstellt
- ✅ Branch wurde mit main synchronisiert (keine Konflikte)
- ✅ CI bestanden (Linting, Typprüfung, Unit-Tests, E2E-Tests)
- ✅ Codex-Reviewer genehmigt
- ✅ Claude-Code-Reviewer genehmigt
- ✅ Gemini-Reviewer genehmigt
- ✅ Wenn es UI-Änderungen gibt, müssen Screenshots beigefügt werden
Schritt 5: Automatisierte Code-Überprüfung
Jeder PR wird von drei Agenten überprüft:
- Codex Reviewer — der zuverlässigste Prüfer - spezialisiert auf das Erkennen von Randfällen
- Kann logische Fehler, fehlende Fehlerbehandlung und Race Conditions erkennen
- Sehr niedrige Fehlalarmrate
- Gemini Code Assist Reviewer — kostenlos und benutzerfreundlich - kann Sicherheitsprobleme und Skalierbarkeitsprobleme erkennen, die andere Prüfer übersehen haben
- Gibt spezifische Reparaturempfehlungen
- Wenn es kostenlos ist, warum nicht nutzen?
- Claude Code Reviewer — im Grunde genommen nutzlos - übermäßig vorsichtig, empfiehlt immer "überlegen Sie, ob Sie hinzufügen sollten..."
- Die meisten Vorschläge sind überdesigniert
- Es sei denn, es ist als "kritisch" gekennzeichnet, sonst wird es einfach übersprungen
Schritt 6: Automatisierte Tests
Die CI-Pipeline führt aus:
- Linting und TypeScript-Überprüfung
- Unit-Tests
- E2E-Tests
- Playwright-Tests (in einer Umgebung, die identisch mit der Produktionsumgebung ist)
Diese Regel hat die Überprüfungszeit erheblich verkürzt - der Autor kann auf einen Blick sehen, was geändert wurde, ohne in die Vorschauumgebung klicken zu müssen.
Schritt 7: Manuelle Überprüfung
Jetzt erhält der Autor eine Telegram-Benachrichtigung: "PR #341 ist bereit zur Überprüfung."
Zu diesem Zeitpunkt:
- CI ist grün
- Alle drei AI-Prüfer haben genehmigt
- Screenshots zeigen die UI-Änderungen
- Alle Randfälle sind in den Überprüfungsanmerkungen dokumentiert
Schritt 8: Zusammenführen
Der PR wird zusammengeführt. Täglich gibt es einen Cron-Job, der isolierte Worktrees und Aufgabenprotokolle bereinigt.Der vollständige Prozess von Kundenanforderungen bis zur Codebereitstellung kann nur 1-2 Stunden in Anspruch nehmen, während der tatsächliche Aufwand des Autors möglicherweise nur 10 Minuten beträgt.
Drei Mechanismen, die das System intelligenter machen
Mechanismus 1: Verbesserte Ralph Loop – nicht nur wiederholen, sondern lernen
Sie haben vielleicht von der Ralph Loop gehört: Kontext aus dem Gedächtnis abrufen → Ausgabe generieren → Ergebnisse bewerten → Lernen speichern.
Aber die meisten Implementierungen haben ein Problem: Der verwendete Prompt ist bei jedem Durchlauf derselbe. Das Gelernte verbessert die zukünftige Abfrage, aber der Prompt selbst ist statisch.
Dieses System ist anders.
Wenn der Agent scheitert, wird Zoe nicht mit demselben Prompt neu starten. Sie wird mit dem vollständigen Geschäftskontext die Gründe für das Scheitern analysieren und dann den Prompt umschreiben:
❌ Schlechtes Beispiel (statischer Prompt): { "Implementierung der benutzerdefinierten Vorlagenfunktion" }
✅ Gutes Beispiel (dynamische Anpassung): { "Halt. Der Kunde möchte X, nicht Y. Das sind ihre genauen Worte aus dem Meeting: Wir möchten die bestehende Konfiguration beibehalten, anstatt von Grund auf neu zu erstellen. Der Schwerpunkt liegt auf der Wiederverwendung von Konfigurationen, nicht auf dem Erstellen neuer Prozesse." }Zoe kann solche Anpassungen vornehmen, weil sie Kontext hat, den der Agent nicht hat:
- Was der Kunde im Meeting gesagt hat
- Was das Unternehmen macht
- Warum ähnliche Anforderungen beim letzten Mal gescheitert sind
- Morgens: Sentry scannen → 4 neue Fehler entdecken → 4 Agenten starten, um zu untersuchen und zu beheben
- Nach dem Meeting: Besprechungsprotokolle scannen → 3 vom Kunden erwähnte Funktionsanforderungen entdecken → 3 Codex starten
- Abends: git log scannen → Claude Code starten, um das Änderungsprotokoll und die Kundendokumentation zu aktualisieren
Erfolgreiche Muster werden aufgezeichnet:
- "Diese Prompt-Struktur ist sehr effektiv für die Rechnungsfunktion"
- "Codex benötigt die Typdefinitionen im Voraus"
- "Immer den Pfad zu den Testdateien einbeziehen"
Je länger die Zeit, desto besser wird der von Zoe geschriebene Prompt, weil sie sich erinnert, was erfolgreich war.
Mechanismus 2: Agentenauswahlstrategie – verschiedene Aufgaben erfordern verschiedene Experten
Nicht alle Agenten sind gleich stark. Der Autor fasst die Auswahlstrategie zusammen:
- Codex(gpt-5.3-codex) – Hauptakteur - Backend-Logik, komplexe Bugs, Mehrdatei-Refaktorisierung, Aufgaben, die über Codebasen hinweg Schlussfolgerungen erfordern
- Langsam, aber gründlich
- Macht 90% der Aufgaben aus
- Claude Code(claude-opus-4.5) – Geschwindigkeitstyp - Frontend-Arbeiten
- Weniger Berechtigungsprobleme, geeignet für git-Operationen
- (Der Autor hat es früher häufiger verwendet, aber nach dem Erscheinen von Codex 5.3 gewechselt)
- Gemini – Designer - hat ein Gespür für Design
- Für ein schönes UI lässt man zuerst Gemini HTML/CSS-Spezifikationen erstellen, dann übergibt man es Claude Code zur Umsetzung im Komponentensystem
- Gemini entwirft, Claude baut
Mechanismus 3: Wo ist der Engpass? RAM
Hier gibt es eine unerwartete Einschränkung: nicht die Token-Kosten, nicht die API-Rate, sondern der Speicher.
Jeder Agent benötigt:
- seinen eigenen Arbeitsbaum
- seine eigenen nodemodules
- zum Ausführen von Builds, Typprüfungen, Tests
Der Mac Mini des Autors (16 GB RAM) kann maximal 4-5 Agenten gleichzeitig ausführen; mehr und es beginnt mit dem Swapping, und man muss beten, dass sie nicht gleichzeitig bauen.Also kaufte er sich einen Mac Studio M4 Max (128GB RAM, $3500), der Ende März ankam. Er sagte, er würde dann teilen, ob es sich lohnt.
Du kannst auch aufbauen: Von null auf Betrieb in nur 10 Minuten
Möchtest du dieses System ausprobieren?
Der einfachste Weg:
Kopiere diesen gesamten Artikel an OpenClaw und sage ihm: "Implementiere ein Agenten-Cluster-System für mein Code-Repository gemäß dieser Architektur."
Dann wird es:
- Die Architektur lesen
- Skripte erstellen
- Die Verzeichnisstruktur einrichten
- Cron-Überwachung konfigurieren
Du musst vorbereiten:
- OpenClaw-Konto
- API-Zugang zu Codex und/oder Claude Code
- Ein Git-Repository
- (Optional) Obsidian zur Speicherung des Geschäftskontexts
2026: Ein Ein-Mann-Millionen-Dollar-Unternehmen
Der Autor sagte am Ende einen inspirierenden Satz:
"Wir werden ab 2026 eine Vielzahl von Ein-Mann-Millionen-Dollar-Unternehmen sehen. Der Hebel ist enorm und gehört denen, die verstehen, wie man rekursive selbstverbessernde KI-Systeme aufbaut."
So sieht es aus:
- Ein KI-Orchestrator als deine Erweiterung (wie Zoe für den Autor)
- Arbeit an spezialisierte Agenten delegieren, die verschiedene Geschäftsbereiche abdecken
- Ingenieurwesen, Kundenservice, Betrieb, Marketing
- Jeder Agent konzentriert sich auf das, was er am besten kann
- Du bleibst fokussiert und hast die volle Kontrolle
Jetzt gibt es zu viel KI-generierten Müllinhalt. Verschiedene Hypes, verschiedene schicke Demos von "Task Control Centers", aber nichts wirklich Nützliches.
Der Autor sagt, er wolle das Gegenteil tun: weniger Hype, mehr Dokumentation des echten Entwicklungsprozesses. Echte Kunden, echte Einnahmen, echte Einreichungen in die Produktionsumgebung, auch echte Misserfolge.
Dieser Artikel endet hier.
Kernpunkte Rückblick:
- Zweischichtige Architektur: Die Orchestrierungsschicht hält den Geschäftskontext, die Ausführungsschicht konzentriert sich auf den Code
- Vollständige Automatisierung: 8-Schritte-Prozess von Anforderungen bis PR, die meisten Aufgaben erfolgreich beim ersten Mal
- Dynamisches Lernen: nicht wiederholte Ausführung, sondern Anpassung der Strategie basierend auf den Gründen für das Scheitern
- Kosten kontrollierbar: Einstieg bei $20/Monat, intensive Nutzung bei $190/Monat
Referenzadresse:[[HTMLPLACEHOLDER_0]]



