OpenClaw + Claude Code Tutorial Poderoso: ¡Un solo individuo puede construir un equipo de desarrollo completo!
OpenClaw + Claude Code Tutorial Poderoso: ¡Un solo individuo puede construir un equipo de desarrollo completo!
Hoy comparto un caso práctico impresionante. (Tutorial al final del artículo)
Un desarrollador independiente, utilizando OpenClaw + Codex/CC, construyó un sistema de Agente AI. ¿Qué resultados logró?
94 envíos en un día, 7 PR completados en 30 minutos, y ese mismo día tuvo 3 reuniones con clientes, sin siquiera abrir el editor.
Esto realmente sucedió en enero de 2026. El autor ha hecho público el diseño del sistema, el flujo de trabajo y la configuración del código. Después de verlo, sentí que esta idea es muy valiosa para aprender, así que la organicé en este artículo para compartirla contigo.
Si también estás usando Codex o Claude Code, o si estás interesado en OpenClaw, este artículo te dará muchas ideas.
Un solo individuo, 94 envíos de código en un día
Primero, veamos algunos datos para sentir el poder de este sistema:
- Máximo de 94 envíos en un solo día (promedio de 50 envíos diarios)
- 7 PR completados en 30 minutos
- La velocidad desde la idea hasta el lanzamiento es tan rápida que se puede "entregar la demanda del cliente el mismo día"
¿Y el costo? $190 al mes (Claude $100 + Codex $90), un principiante puede comenzar con solo $20.
Podrías preguntar: ¿No es esto solo apilar un montón de herramientas de IA y generar código basura de manera frenética?
No. El historial de Git del autor parece como si "acaba de contratar un equipo de desarrollo", pero en realidad solo es él. El cambio clave es: pasó de "gestionar Claude Code" a "gestionar un mayordomo AI, que a su vez gestiona un grupo de Claude Code".
- Antes de enero: escribir código directamente con Codex o Claude Code
- Después de enero: usar OpenClaw como capa de orquestación, permitiendo que gestione Codex/Claude Code/Gemini
¿Por qué Codex y Claude Code por separado no son suficientes?
En este punto, podrías pensar: Codex y Claude Code ya son muy potentes, ¿por qué agregar una capa de orquestación?
La respuesta del autor es muy directa: Codex y Claude Code casi no saben nada sobre tu negocio. Solo ven el código, no ven el panorama completo del negocio.
Aquí hay una limitación fundamental: la ventana de contexto es fija, solo puedes elegir uno.
Debes decidir qué meter:
- Llenar de código → No hay espacio para el contexto del negocio
- Llenar de historial del cliente → No hay espacio para el repositorio de código
- No sabe para qué cliente se está desarrollando esta función
- No sabe por qué falló la última demanda similar
- No sabe tu posicionamiento de producto y principios de diseño
- Solo puede trabajar según el código actual y tu prompt
Actúa como una capa de orquestación, situada entre tú y todas las herramientas de IA. Su papel es:
- Mantener todo el contexto del negocio (datos del cliente, actas de reuniones, decisiones históricas, casos de éxito/fracasos)
- Traducir el contexto del negocio en prompts precisos, que se alimentan a los Agentes específicos
- Permitir que estos Agentes se concentren en lo que mejor saben hacer: escribir código
- Codex/Claude Code = Chef profesional, solo se encarga de cocinar
- OpenClaw = Chef principal, conoce los gustos de los clientes, el inventario de ingredientes, la posición del menú, y da instrucciones precisas a cada chef
Arquitectura específica del sistema de doble capa: Capa de orquestación + Capa de ejecución
Veamos la arquitectura específica de este sistema.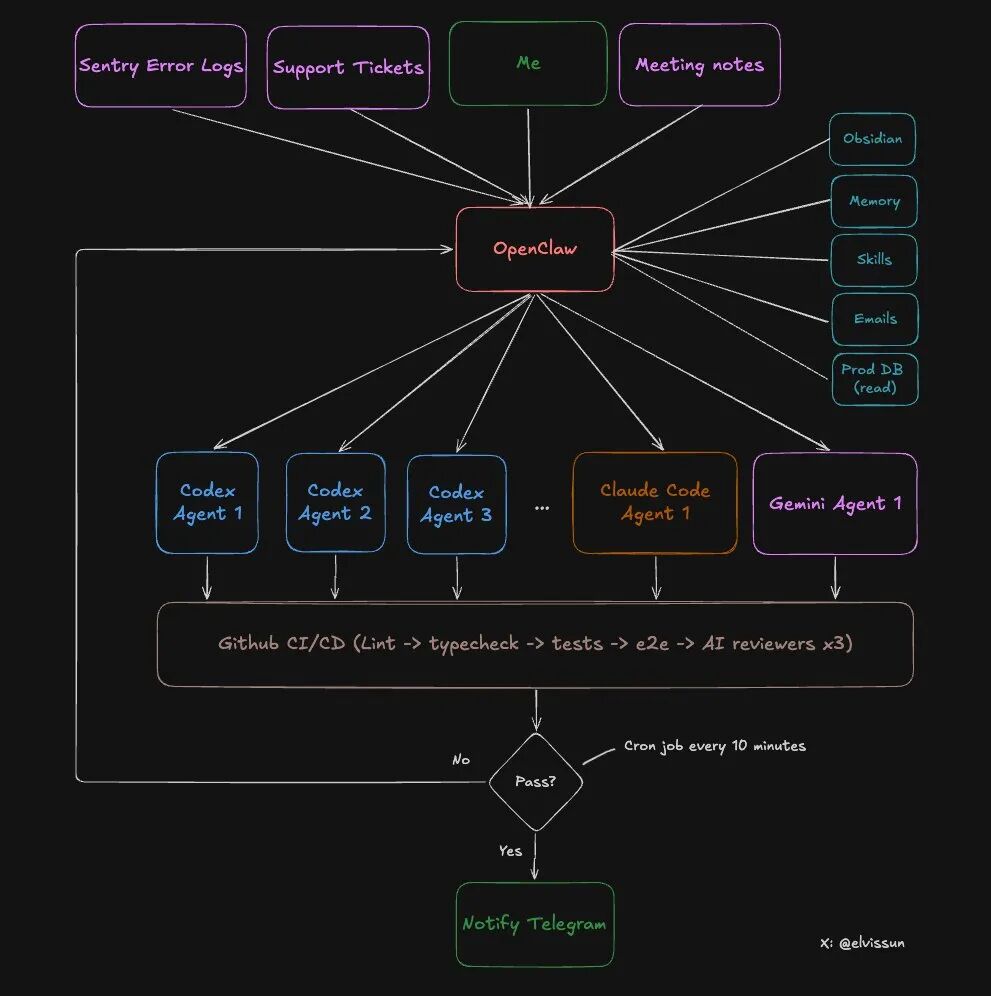
Dos capas, cada una con su función:

¿Qué puede hacer OpenClaw (capa de orquestación)?
- Leer todos los registros de reuniones en las notas de Obsidian (sincronización automática)
- Acceder a la base de datos de producción (solo permisos de lectura) para obtener la configuración del cliente
- Tener permisos de API de administrador, puede recargar y desbloquear al cliente directamente
- Seleccionar el agente adecuado según el tipo de tarea
- Monitorear el progreso de todos los agentes, si falla, analizar la causa y ajustar el prompt para reintentar
- Notificar al autor a través de Telegram una vez completado
¿Qué puede hacer el Agente (capa de ejecución)?
- Leer y escribir en el repositorio de código
- Ejecutar pruebas y construcciones
- Enviar código y crear PR
- Responder a los comentarios de la revisión de código

Este diseño es inteligente: el límite de seguridad es claro, mientras que se garantiza la eficiencia.
Flujo de trabajo completo: 8 pasos desde la necesidad del cliente hasta la fusión del PR
Ahora entramos en la parte central. Usaremos un caso real del autor de la semana pasada para guiarte a través del proceso completo.
Contexto: Un cliente empresarial llamó y dijo que quería reutilizar su configuración ya establecida y compartirla dentro del equipo.
Paso 1: Necesidad del cliente → OpenClaw entiende y descompone
Después de la llamada, el autor y Zoe (su OpenClaw) discutieron esta necesidad.
Aquí está la parte mágica: costo de explicación cero. Debido a que todos los registros de reuniones se sincronizan automáticamente con Obsidian, Zoe ya había leído el contenido de la llamada y sabía quién era el cliente, su escenario de negocio y la configuración existente.
El autor y Zoe descompusieron la necesidad en: crear un sistema de plantillas que permita a los usuarios guardar y editar la configuración existente.
Luego, Zoe hizo tres cosas:
- Recargar al cliente — Usar la API de administrador para eliminar inmediatamente las restricciones de uso del cliente
- Obtener la configuración del cliente — Obtener la configuración existente del cliente de la base de datos de producción (solo lectura)
- Generar el prompt e iniciar el agente — Empacar todo el contexto y alimentarlo a Codex
Paso 2: Iniciar el agente
Zoe creó para esta tarea:
- Un worktree git independiente (entorno de rama aislado)
- Una sesión tmux (para que el Agente se ejecute en segundo plano)
# Crear worktree + iniciar agente git worktree add ../feat-custom-templates -b feat/custom-templates origin/main cd ../feat-custom-templates && pnpm install
tmux new-session -d -s "codex-templates" \ -c "/Users/elvis/Documents/GitHub/medialyst-worktrees/feat-custom-templates" \ "$HOME/.codex-agent/run-agent.sh templates gpt-5.3-codex high ¿Por qué usar tmux? Porque se puede intervenir en el medio.
Si la IA se desvía, no es necesario matar y reiniciar, simplemente se envían comandos directamente en tmux:
# El agente se está desviando tmux send-keys -t codex-templates "Detente. Primero haz la capa API, no te preocupes por la UI." Enter
El agente necesita más contexto
tmux send-keys -t codex-templates "La definición de tipo está en src/types/template.ts, usa eso." Enter Al mismo tiempo, la tarea se registrará en un archivo JSON:[[HTMLPLACEHOLDER0]]
[[HTMLPLACEHOLDER1]]
[[HTMLPLACEHOLDER2]]
[[HTMLPLACEHOLDER3]]
[[HTMLPLACEHOLDER4]]
[[HTMLPLACEHOLDER5]]
[[HTMLPLACEHOLDER6]]
[[HTMLPLACEHOLDER7]]
[[HTMLPLACEHOLDER8]]
[[HTMLPLACEHOLDER9]]
[[HTMLPLACEHOLDER10]]
[[HTMLPLACEHOLDER11]]
[[HTMLPLACEHOLDER12]]
[[HTMLPLACEHOLDER13]]
[[HTMLPLACEHOLDER14]]
[[HTMLPLACEHOLDER15]]
[[HTMLPLACEHOLDER16]]
[[HTMLPLACEHOLDER17]]
[[HTMLPLACEHOLDER18]]
[[HTMLPLACEHOLDER19]]
[[HTMLPLACEHOLDER20]]
[[HTMLPLACEHOLDER21]]
[[HTMLPLACEHOLDER22]] [[HTMLPLACEHOLDER23]]
[[HTMLPLACEHOLDER24]]
[[HTMLPLACEHOLDER25]]
[[HTMLPLACEHOLDER26]]El proceso completo, desde la necesidad del cliente hasta el lanzamiento del código, puede tardar solo de 1 a 2 horas, mientras que la inversión real del autor puede ser de solo 10 minutos.
Tres mecanismos para hacer que el sistema sea más inteligente
Mecanismo 1: Ralph Loop mejorado — No solo repetir, sino aprender
Es posible que hayas oído hablar del Ralph Loop: extraer contexto de la memoria → generar salida → evaluar resultados → guardar aprendizaje.
Pero la mayoría de las implementaciones tienen un problema: el prompt utilizado en cada ciclo es el mismo. Lo que se aprende mejora la recuperación futura, pero el prompt en sí es estático.
Este sistema es diferente.
Cuando el Agente falla, Zoe no reinicia con el mismo prompt. Ella lleva el contexto completo del negocio, analiza la razón del fracaso y luego reescribe el prompt:
❌ Mal ejemplo (prompt estático): { "Implementar función de plantilla personalizada" }
✅ Buen ejemplo (ajuste dinámico): { "Detente. El cliente quiere X, no Y. Estas son sus palabras en la reunión: Queremos conservar la configuración existente, no crear una nueva desde cero. Enfócate en la reutilización de la configuración, no en crear un nuevo proceso." }Zoe puede hacer este tipo de ajustes porque tiene contexto que el Agente no tiene:
- Lo que el cliente dijo en la reunión
- A qué se dedica la empresa
- Por qué falló la última solicitud similar
Más allá de eso, Zoe no espera a que le asignes tareas, ella busca trabajo activamente:
- Por la mañana: escanea Sentry → encuentra 4 nuevos errores → inicia 4 Agentes para investigar y reparar
- Después de la reunión: escanea las actas de la reunión → encuentra 3 funciones mencionadas por el cliente → inicia 3 Codex
- Por la noche: escanea el registro de git → inicia Claude Code para actualizar el changelog y la documentación del cliente
El autor regresa de su paseo y ve en Telegram: "7 PR listos. 3 nuevas funciones, 4 correcciones de errores."
Los patrones exitosos se registran:
- "Esta estructura de prompt es muy efectiva para la función de facturación"
- "Codex necesita recibir las definiciones de tipo con anticipación"
- "Siempre debe incluir la ruta del archivo de prueba"
La señal de recompensa es: CI aprobado, tres revisiones de código aprobadas, fusión manual. Cualquier fallo desencadenará el ciclo.
Cuanto más tiempo pasa, mejor es el prompt que escribe Zoe, porque recuerda qué puede tener éxito.
Mecanismo 2: Estrategia de selección de Agentes — Diferentes tareas requieren diferentes expertos
No todos los Agentes son igual de fuertes. La estrategia de selección resumida por el autor:
- Codex(gpt-5.3-codex) — Principal - lógica de backend, errores complejos, reestructuración de múltiples archivos, tareas que requieren inferencia entre bibliotecas de código
- Lento pero exhaustivo
- Cubre el 90% de las tareas
- Claude Code(claude-opus-4.5) — Competidor rápido - trabajo de frontend
- Menos problemas de permisos, adecuado para operaciones de git
- (El autor lo usaba más antes, pero cambió a Codex 5.3)
- Gemini — Diseñador - tiene sentido estético
- Para una UI atractiva, primero deja que Gemini genere las especificaciones de HTML/CSS, luego se las pasa a Claude Code para implementarlas en el sistema de componentes
- Gemini diseña, Claude construye
Zoe selecciona automáticamente el Agente según el tipo de tarea y transfiere la salida entre ellos. Los errores del sistema de facturación se envían a Codex, la corrección del estilo del botón a Claude Code, y el nuevo diseño del panel se envía primero a Gemini.
Mecanismo 3: ¿Dónde está el cuello de botella? RAM
Aquí hay una limitación inesperada: no es el costo de tokens, no es la tasa de API, sino la memoria.
Cada Agente necesita:
- Su propio worktree
- Sus propios node_modules
- Ejecutar construcción, verificación de tipos, pruebas
5 Agentes ejecutándose al mismo tiempo = 5 compiladores de TypeScript en paralelo + 5 ejecutores de pruebas + 5 conjuntos de dependencias cargadas en memoria.
El Mac Mini del autor (16GB de RAM) puede ejecutar un máximo de 4-5 Agentes al mismo tiempo, más que eso comenzará a usar swap, y hay que rezar para que no construyan al mismo tiempo.Así que compró una Mac Studio M4 Max (128GB RAM, $3500), que llegó a finales de marzo. Dijo que compartirá si valió la pena.
También puedes construir: desde cero hasta funcionando en solo 10 minutos
¿Quieres probar este sistema?
La forma más sencilla:
Copia todo este artículo a OpenClaw y dile: "Implementa un sistema de clúster de agentes para mi repositorio de código según esta arquitectura."
Entonces, hará lo siguiente:
- Leerá el diseño de la arquitectura
- Creará scripts
- Configurará la estructura de directorios
- Configurará la monitorización de cron
10 minutos y listo.
Necesitas preparar:
- Cuenta de OpenClaw
- Acceso a la API de Codex y/o Claude Code
- Un repositorio git
- (Opcional) Obsidian para almacenar el contexto del negocio
2026: La compañía de un millón de dólares de una sola persona
El autor dice una frase al final que creo que es muy inspiradora:
"Veremos una gran cantidad de compañías de un millón de dólares de una sola persona aparecer a partir de 2026. El apalancamiento es enorme, pertenece a aquellos que entienden cómo construir sistemas de IA de auto-mejora recursiva."
Así es como se ve:
- Un orquestador de IA como tu extensión (como Zoe para el autor)
- Delegar trabajo a agentes especializados, manejando diferentes funciones del negocio
- Ingeniería, soporte al cliente, operaciones, marketing
- Cada agente se enfoca en lo que mejor sabe hacer
- Tú mantienes el enfoque y el control total
La próxima generación de emprendedores no contratará a 10 personas para hacer lo que una persona más un sistema puede hacer. Ellos construirán así: manteniendo un tamaño pequeño, actuando rápido, publicando todos los días.
Ahora hay demasiados contenidos basura generados por IA. Todo tipo de exageraciones, todo tipo de demos llamativas de "centros de control de tareas", pero nada realmente útil.
El autor dice que quiere hacer lo contrario: menos exageración, más documentación del proceso de construcción real. Clientes reales, ingresos reales, envíos reales a producción, y también fracasos reales.
Este artículo termina aquí.
Resumen de los puntos clave:
- Arquitectura de doble capa: la capa de orquestación mantiene el contexto del negocio, la capa de ejecución se enfoca en el código
- Automatización completa: un proceso de 8 pasos desde la demanda hasta el PR, la mayoría de las tareas se completan con éxito en un intento
- Aprendizaje dinámico: no se trata de ejecutar repetidamente, sino de ajustar la estrategia según las razones del fracaso
- Costos controlables: comienza en $20/mes, uso intensivo $190/mes
Si también estás explorando aplicaciones prácticas de la automatización de IA, espero que este caso te brinde algo de inspiración.
Referencia:https://x.com/elvissun/status/2025920521871716562`



