OpenClaw + Claude Code Super Tutoriel : Un seul individu peut construire une équipe de développement complète !
OpenClaw + Claude Code Super Tutoriel : Un seul individu peut construire une équipe de développement complète !
Aujourd'hui, je partage un cas pratique très impressionnant. (Le tutoriel est à la fin de l'article)
Un développeur indépendant a utilisé OpenClaw + Codex/CC pour mettre en place un système d'Agent IA. Quel effet cela a-t-il eu ?
94 soumissions en une journée, 7 PR complétés en 30 minutes, et ce jour-là, il a également eu 3 réunions avec des clients, sans même ouvrir l'éditeur.
Cela s'est réellement produit en janvier 2026. L'auteur a rendu public l'architecture du système, le flux de travail et la configuration du code. Après avoir lu cela, j'ai trouvé cette approche tellement instructive que j'ai décidé de la compiler dans cet article pour vous la partager.
Si vous utilisez également Codex ou Claude Code, ou si vous êtes intéressé par OpenClaw, cet article vous apportera beaucoup d'inspiration.
Un seul individu, 94 soumissions de code en une journée
Commençons par quelques données pour ressentir la puissance de ce système :
- Maximum de 94 soumissions en une journée (moyenne de 50 soumissions par jour)
- 7 PR complétés en 30 minutes
- La vitesse de mise en ligne est si rapide qu'il est possible de "livrer les demandes des clients le jour même"
Et le coût ? 190 $ par mois (Claude 100 $ + Codex 90 $), un débutant peut démarrer avec seulement 20 $.
Vous vous demandez peut-être : est-ce qu'il a simplement empilé une multitude d'outils IA et généré une quantité folle de code inutile ?
Non. L'historique Git de l'auteur ressemble à celui d'une "équipe de développement récemment embauchée", mais en réalité, il n'est qu'une seule personne. Le changement clé est : il est passé de "gérer Claude Code" à "gérer un majordome IA, qui gère ensuite un groupe de Claude Code".
- Avant janvier : écrire du code directement avec Codex ou Claude Code
- Après janvier : utiliser OpenClaw comme couche d'orchestration pour gérer Codex/Claude Code/Gemini
Pourquoi Codex et Claude Code ne suffisent-ils pas lorsqu'ils sont utilisés séparément ?
À ce stade, vous pourriez vous demander : Codex et Claude Code sont déjà très puissants, pourquoi ajouter une couche d'orchestration ?
La réponse de l'auteur est très directe : Codex et Claude Code ne connaissent presque rien de votre entreprise. Ils ne voient que le code, sans comprendre le tableau d'ensemble des affaires.
Il y a une limitation fondamentale ici : la fenêtre de contexte est fixe, vous ne pouvez choisir qu'une option.
Vous devez faire un choix sur ce que vous allez y insérer :
- Remplir de code → Pas d'espace pour le contexte commercial
- Remplir de l'historique client → Pas d'espace pour la base de code
- Il ne sait pas pour quel client cette fonctionnalité est développée
- Il ne sait pas pourquoi la dernière demande similaire a échoué
- Il ne connaît pas votre positionnement produit et vos principes de conception
- Il ne peut travailler qu'en fonction du code actuel et de votre prompt
Il agit comme une couche d'orchestration, se situant entre vous et tous les outils IA. Son rôle est :
- Détenir tout le contexte commercial (données clients, comptes rendus de réunions, décisions historiques, cas de succès/échec)
- Traduire le contexte commercial en prompts précis, à fournir à des Agents spécifiques
- Permettre à ces Agents de se concentrer sur ce qu'ils font le mieux : écrire du code
- Codex/Claude Code = Chef cuisinier professionnel, se concentre uniquement sur la cuisine
- OpenClaw = Chef de cuisine, connaît les goûts des clients, les stocks d'ingrédients, le positionnement du menu, et donne des instructions précises à chaque cuisinier
Architecture spécifique du système à deux niveaux : couche d'orchestration + couche d'exécution
Voyons l'architecture spécifique de ce système.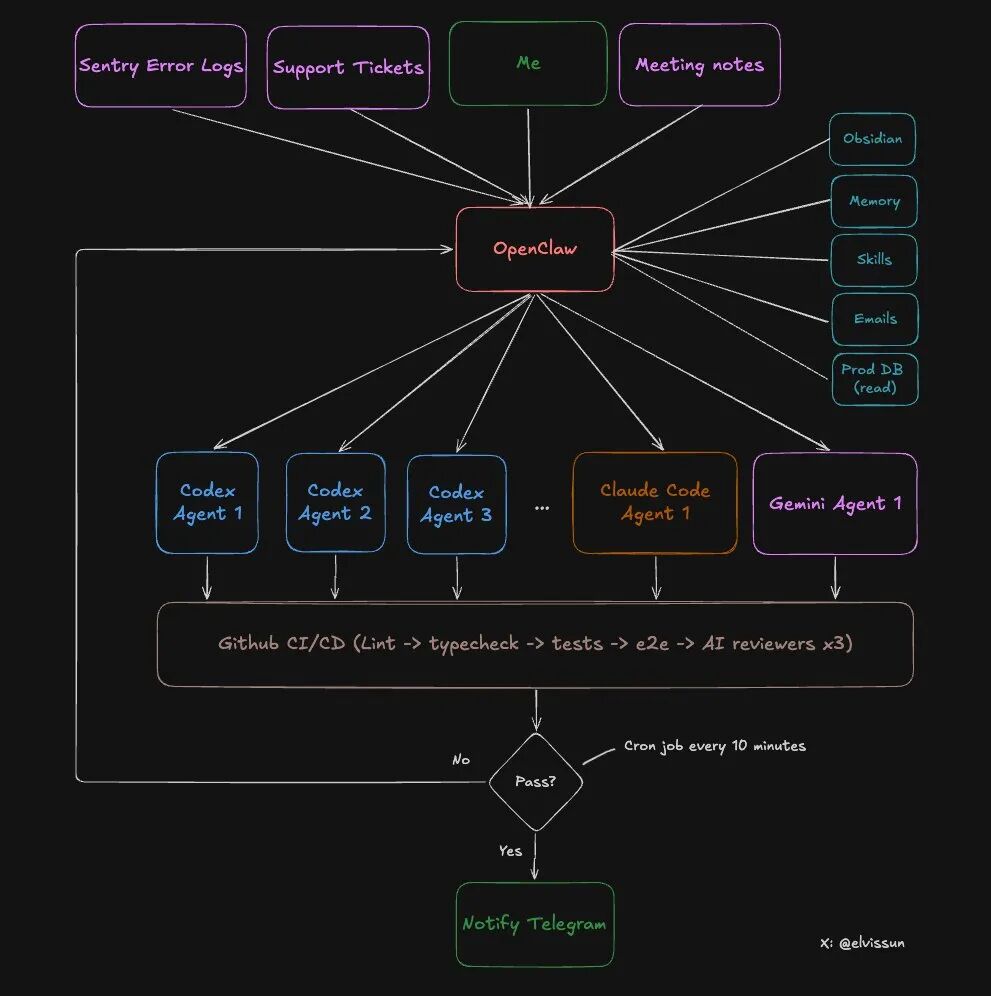
Deux niveaux, chacun avec ses propres responsabilités :

Que peut faire OpenClaw (couche d'orchestration) ?
- Lire tous les comptes rendus de réunion dans les notes Obsidian (synchronisation automatique)
- Accéder à la base de données de production (permissions en lecture seule) pour obtenir la configuration client
- Avoir des permissions API administratives, permettant de recharger directement le client et de lever les blocages
- Choisir le bon agent en fonction du type de tâche
- Surveiller l'avancement de tous les agents, analyser les raisons des échecs et ajuster les prompts pour réessayer
- Notifier l'auteur via Telegram une fois terminé
Que peut faire l'Agent (couche d'exécution) ?
- Lire et écrire dans le dépôt de code
- Exécuter des tests et des constructions
- Soumettre du code et créer des PR
- Répondre aux retours de la révision de code

Ce design est intelligent : les frontières de sécurité sont claires tout en garantissant l'efficacité.
Flux de travail complet : 8 étapes de la demande client à la fusion de PR
Entrons maintenant dans la partie centrale. Avec un cas réel de l'auteur de la semaine dernière, je vais vous faire traverser le processus complet.
Contexte : un client entreprise a appelé, disant qu'il souhaitait réutiliser leurs paramètres déjà configurés et les partager au sein de l'équipe.
Étape 1 : Demande client → OpenClaw comprend et décompose
Après l'appel, l'auteur a discuté de cette demande avec Zoe (son OpenClaw).
Ce qui est magique ici : coût d'explication nul. Puisque tous les comptes rendus de réunion sont automatiquement synchronisés avec Obsidian, Zoe a déjà lu le contenu de l'appel, sait qui est le client, leur scénario commercial et leur configuration existante.
L'auteur et Zoe ont décomposé la demande en : créer un système de modèles permettant aux utilisateurs de sauvegarder et d'éditer la configuration existante.
Ensuite, Zoe a fait trois choses :
- Recharger le client — utiliser l'API administrateur pour lever immédiatement les restrictions d'utilisation du client
- Récupérer la configuration du client — obtenir les paramètres existants du client depuis la base de données de production (lecture seule)
- Générer un prompt et démarrer l'agent — empaqueter tout le contexte et le fournir à Codex
Étape 2 : Démarrer l'agent
Zoe a créé pour cette tâche :
- Un worktree git indépendant (environnement de branche isolé)
- Une session tmux (permettant à l'Agent de s'exécuter en arrière-plan)
# 创建 worktree + 启动代理 git worktree add ../feat-custom-templates -b feat/custom-templates origin/main cd ../feat-custom-templates && pnpm install
tmux new-session -d -s "codex-templates" \ -c "/Users/elvis/Documents/GitHub/medialyst-worktrees/feat-custom-templates" \ "$HOME/.codex-agent/run-agent.sh templates gpt-5.3-codex high Pourquoi utiliser tmux ? Parce que cela permet d'intervenir en cours de route.
Si l'IA s'égare, il n'est pas nécessaire de tout arrêter et de recommencer, il suffit d'envoyer des instructions directement dans tmux :
# 代理方向错了 tmux send-keys -t codex-templates "停一下。先做 API 层,别管 UI。" Enter
代理需要更多上下文
tmux send-keys -t codex-templates "类型定义在 src/types/template.ts,用那个。" Enter Pendant ce temps, la tâche sera enregistrée dans un fichier JSON.{ "id": "feat-custom-templates", "tmuxSession": "codex-templates", "agent": "codex", "description": "Fonctionnalité de modèles d'e-mails personnalisés pour les clients d'entreprise", "repo": "medialyst", "worktree": "feat-custom-templates", "branch": "feat/custom-templates", "startedAt": 1740268800000, "status": "running", "notifyOnComplete": true}### Étape 3 : Surveillance automatique
Une tâche cron vérifie l'état de tous les agents toutes les 10 minutes.
Point clé : il ne s'agit pas de "demander" à l'Agent comment ça se passe (cela consommerait beaucoup de tokens), mais de vérifier des faits objectifs :
- La session tmux est-elle toujours active ?
- Un PR a-t-il été créé ?
- Quel est l'état du CI ?
- En cas d'échec, faut-il redémarrer ? (maximum 3 tentatives)
C'est en fait une version améliorée de Ralph Loop, qui sera détaillée plus tard.
Étape 4 : L'Agent crée un PR
L'Agent écrit le code, le soumet, le pousse, puis crée un PR avec gh pr create --fill.
Remarque : à ce stade, l'auteur ne recevra pas de notification. Car un PR en soi ne représente pas "terminé".
La définition de "terminé" est :
- ✅ PR créé
- ✅ Branche synchronisée avec main (sans conflit)
- ✅ CI réussi (lint, vérification de type, tests unitaires, tests E2E)
- ✅ Revue Codex approuvée
- ✅ Revue Claude approuvée
- ✅ Revue Gemini approuvée
- ✅ S'il y a des modifications UI, des captures d'écran doivent être incluses
Étape 5 : Revue de code automatisée
Chaque PR sera examinée par trois Agents :
- Relecteur Codex — Le relecteur le plus fiable - expert dans la détection des cas limites
- Capable de détecter des erreurs logiques, des erreurs de gestion manquantes, des conditions de concurrence
- Taux de faux positifs très bas
- Relecteur d'assistance au code Gemini — Gratuit et facile à utiliser - capable de détecter des problèmes de sécurité et d'évolutivité que d'autres relecteurs ont manqués
- Fournira des suggestions de correction spécifiques
- À utiliser sans hésitation
- Relecteur de code Claude — Pratiquement inutile - trop prudent, suggère toujours "envisagez d'ajouter..."
- La plupart des suggestions sont des conceptions excessives
- À moins qu'il ne soit marqué comme "critique", il est directement ignoré
Étape 6 : Tests automatisés
Le pipeline CI exécutera :
- Vérifications Lint et TypeScript
- Tests unitaires
- Tests E2E
- Tests Playwright (exécutés dans un environnement de prévisualisation identique à l'environnement de production)
Cette règle a considérablement réduit le temps de révision - l'auteur peut jeter un œil à la capture d'écran pour savoir ce qui a été modifié, sans avoir à accéder à l'environnement de prévisualisation.
Étape 7 : Revue manuelle
Maintenant, l'auteur reçoit une notification Telegram : "PR #341 est prêt, vous pouvez le réviser."
À ce moment-là :
- CI tout vert
- Les trois relecteurs AI ont tous approuvé
- La capture d'écran montre les changements d'UI
- Tous les cas limites ont été enregistrés dans les commentaires de révision
Étape 8 : Fusion
Le PR est fusionné. Chaque jour, une tâche cron nettoie les worktrees isolés et les enregistrements de tâches.Le processus complet, de la demande du client au déploiement du code, peut ne prendre que 1 à 2 heures, alors que l'investissement réel de l'auteur n'est peut-être que de 10 minutes.
Trois mécanismes pour rendre le système plus intelligent
Mécanisme 1 : Version améliorée de Ralph Loop — Pas seulement répéter, mais apprendre
Vous avez peut-être entendu parler de Ralph Loop : tirer le contexte de la mémoire → générer une sortie → évaluer le résultat → sauvegarder l'apprentissage.
Mais la plupart des implémentations ont un problème : le prompt utilisé à chaque boucle est le même. Ce qui est appris améliore la récupération future, mais le prompt lui-même est statique.
Ce système est différent.
Lorsque l'Agent échoue, Zoe ne redémarre pas avec le même prompt. Elle analyse la raison de l'échec avec le contexte commercial complet, puis réécrit le prompt :
❌ Mauvais exemple (prompt statique) : { "Implémenter la fonctionnalité de modèle personnalisé" }
✅ Bon exemple (ajustement dynamique) : { "Arrêtez. Le client veut X, pas Y. Voici leurs mots lors de la réunion : Nous voulons conserver la configuration existante, plutôt que de créer une nouvelle à partir de zéro. L'accent doit être mis sur la réutilisation de la configuration, pas sur la création d'un nouveau processus." }Zoe peut faire ce genre d'ajustement parce qu'elle a un contexte que l'Agent n'a pas :
- Ce que le client a dit lors de la réunion
- Ce que fait cette entreprise
- Pourquoi une demande similaire a échoué la dernière fois
- Matin : scanner Sentry → découvrir 4 nouvelles erreurs → lancer 4 Agents pour enquêter et corriger
- Après la réunion : scanner les comptes rendus → découvrir 3 fonctionnalités mentionnées par le client → lancer 3 Codex
- Soir : scanner le git log → lancer Claude Code pour mettre à jour le changelog et la documentation client
Les modèles de réussite seront enregistrés :
- "Cette structure de prompt est très efficace pour la fonctionnalité de facturation"
- "Codex a besoin d'obtenir les définitions de type à l'avance"
- "Il faut toujours inclure le chemin des fichiers de test"
Plus le temps passe, meilleur est le prompt écrit par Zoe, car elle se souvient de ce qui peut réussir.
Mécanisme 2 : Stratégie de sélection des Agents — Différents experts pour différentes tâches
Tous les Agents ne sont pas également puissants. Voici la stratégie de sélection résumée par l'auteur :
- Codex(gpt-5.3-codex) — Principal - Logique backend, bugs complexes, refactorisation de plusieurs fichiers, tâches nécessitant un raisonnement à travers des bibliothèques de code
- Lent mais complet
- Représente 90 % des tâches
- Claude Code(claude-opus-4.5) — Rapide - Travail frontend
- Moins de problèmes de permissions, adapté aux opérations git
- (L'auteur l'utilisait plus souvent auparavant, mais a changé après la sortie de Codex 5.3)
- Gemini — Designer - A un sens esthétique du design
- Pour une UI attrayante, laissez d'abord Gemini générer les spécifications HTML/CSS, puis confiez-les à Claude Code pour les implémenter dans le système de composants
- Gemini conçoit, Claude construit
Mécanisme 3 : Où se trouve le goulot d'étranglement ? RAM
Il y a une limitation inattendue : ce n'est pas le coût des tokens, ce n'est pas le taux d'API, mais la mémoire.
Chaque Agent a besoin de :
- Son propre worktree
- Ses propres nodemodules
- Exécuter des constructions, des vérifications de type, des tests
Le Mac Mini de l'auteur (16 Go de RAM) peut faire fonctionner au maximum 4-5 Agents en même temps, au-delà, il commence à échanger, et il faut prier pour qu'ils ne construisent pas en même temps.Donc, il a acheté un Mac Studio M4 Max (128 Go de RAM, 3500 $), qui arrivera fin mars. Il a dit qu'il partagerait son avis sur la valeur de l'achat.
Vous pouvez aussi construire : de zéro à opérationnel en seulement 10 minutes
Vous voulez essayer ce système ?
La méthode la plus simple :
Copiez tout cet article à OpenClaw et dites-lui : "En suivant cette architecture, implémentez un système de cluster d'Agent pour ma bibliothèque de code."
Ensuite, il fera :
- Lire la conception de l'architecture
- Créer des scripts
- Configurer la structure des répertoires
- Configurer la surveillance cron
Vous devez préparer :
- Un compte OpenClaw
- Accès API à Codex et/ou Claude Code
- Un dépôt git
- (optionnel) Obsidian pour stocker le contexte commercial
2026 : Une société d'un million de dollars pour une seule personne
L'auteur a dit quelque chose à la fin qui m'a semblé très inspirant :
"Nous verrons de nombreuses sociétés d'un million de dollars pour une seule personne apparaître à partir de 2026. Le levier est énorme, appartenant à ceux qui comprennent comment construire des systèmes d'IA d'auto-amélioration récursifs."
Voici à quoi cela ressemble :
- Un orchestrateur IA comme votre extension (comme Zoe pour l'auteur)
- Déléguer le travail à des Agents spécialisés, traitant différentes fonctions commerciales
- Ingénierie, support client, opérations, marketing
- Chaque Agent se concentre sur ce qu'il fait le mieux
- Vous restez concentré et totalement en contrôle
Il y a trop de contenu généré par l'IA qui est de mauvaise qualité. Toutes sortes de battage médiatique, toutes sortes de démos flashy de "centres de contrôle de tâches", mais rien de vraiment utile.
L'auteur dit qu'il veut faire le contraire : moins de battage, plus de documentation du processus de construction réel. Des clients réels, des revenus réels, des soumissions réelles mises en production, et aussi de vrais échecs.
Cet article s'arrête ici.
Récapitulatif des points clés :
- Architecture à deux niveaux : la couche d'orchestration détient le contexte commercial, la couche d'exécution se concentre sur le code
- Automatisation complète : un processus en 8 étapes de la demande à la PR, la plupart des tâches réussies du premier coup
- Apprentissage dynamique : pas d'exécution répétée, mais ajustement de la stratégie en fonction des raisons d'échec
- Coûts maîtrisés : à partir de 20 $/mois, utilisation intensive 190 $/mois
Adresse de référence :[[HTMLPLACEHOLDER_0]]



