OpenClaw + Claude Code super tutorial: En person kan bygge et komplett utviklingsteam!
OpenClaw + Claude Code super tutorial: En person kan bygge et komplett utviklingsteam!
I dag deler jeg et veldig imponerende praksiseksempel. (Tutorialen er vedlagt på slutten)
En uavhengig utvikler har brukt OpenClaw + Codex/CC til å bygge et AI Agent-system. Hva har han oppnådd?
94 innsendelser på en dag, 7 PR-er fullført på 30 minutter, og denne dagen hadde han også 3 kundemøter uten å åpne editoren.
Dette skjedde faktisk i januar 2026. Forfatteren har offentliggjort hele systemets arkitektur, arbeidsflyt og kodekonfigurasjon. Etter å ha sett på dette, følte jeg at denne tilnærmingen er veldig verdt å lære, så jeg har samlet det i denne artikkelen for å dele med deg.
Hvis du også bruker Codex eller Claude Code, eller er interessert i OpenClaw, vil denne artikkelen gi deg mye inspirasjon.
En person, 94 kodeinnsendelser på en dag
La oss se på noen data for å føle kraften i dette systemet:
- Maksimalt 94 innsendelser på en dag (gjennomsnittlig 50 innsendelser per dag)
- Fullført 7 PR-er på 30 minutter
- Hastigheten fra idé til lansering er så rask at man kan "levere kundens krav samme dag"
Hva med kostnadene? Hver måned $190 (Claude $100 + Codex $90), nybegynnere kan starte med $20.
Du lurer kanskje på: Er dette bare å stable opp en haug med AI-verktøy og deretter generere søppelkode?
Nei. Forfatterens Git-historikk ser ut som "jeg har nettopp ansatt et utviklingsteam", men i virkeligheten er det bare ham. Den viktigste endringen er: han har gått fra "å administrere Claude Code" til "å administrere en AI hushjelp, som deretter administrerer en gruppe Claude Code".
- Før januar: Skrive kode direkte med Codex eller Claude Code
- Etter januar: Bruke OpenClaw som et orkestreringslag, som koordinerer Codex/Claude Code/Gemini
Hvorfor er Codex og Claude Code ikke gode nok alene?
På dette tidspunktet kan du tenke: Codex og Claude Code er allerede veldig sterke, hvorfor trenger vi et ekstra lag med orkestrering?
Forfatterens svar er veldig direkte: Codex og Claude Code vet nesten ingenting om virksomheten din. De ser bare koden, men ikke det komplette forretningsbildet.
Her er det en grunnleggende begrensning: kontekstvinduet er fast, og du må velge mellom to alternativer.
Du må ta et valg om hva du skal fylle inn:
- Fylle opp med kode → Ingen plass til forretningskontekst
- Fylle opp med kundehistorikk → Ingen plass til kodebasen
- Den vet ikke hvilken kunde denne funksjonen er laget for
- Den vet ikke hvorfor forrige lignende krav feilet
- Den vet ikke produktets posisjonering og designprinsipper
- Den kan bare jobbe basert på den nåværende koden og din prompt
Det fungerer som et orkestreringslag, plassert mellom deg og alle AI-verktøyene. Dets rolle er:
- Inneha all forretningskontekst (kundedata, møtereferater, historiske beslutninger, suksess-/feilcaser)
- Oversette forretningskonteksten til presise prompts, som mates til spesifikke agenter
- La disse agentene fokusere på det de er gode på: skrive kode
- Codex/Claude Code = Profesjonelle kokker, som bare lager mat
- OpenClaw = Kjøkkensjef, som vet om kundenes smak, ingredienslager, menyposisjonering, og gir hver kokk presise instruksjoner
Den spesifikke arkitekturen til to-lags systemet: Orkestreringslag + Utførelseslag
La oss se på den spesifikke arkitekturen til dette systemet.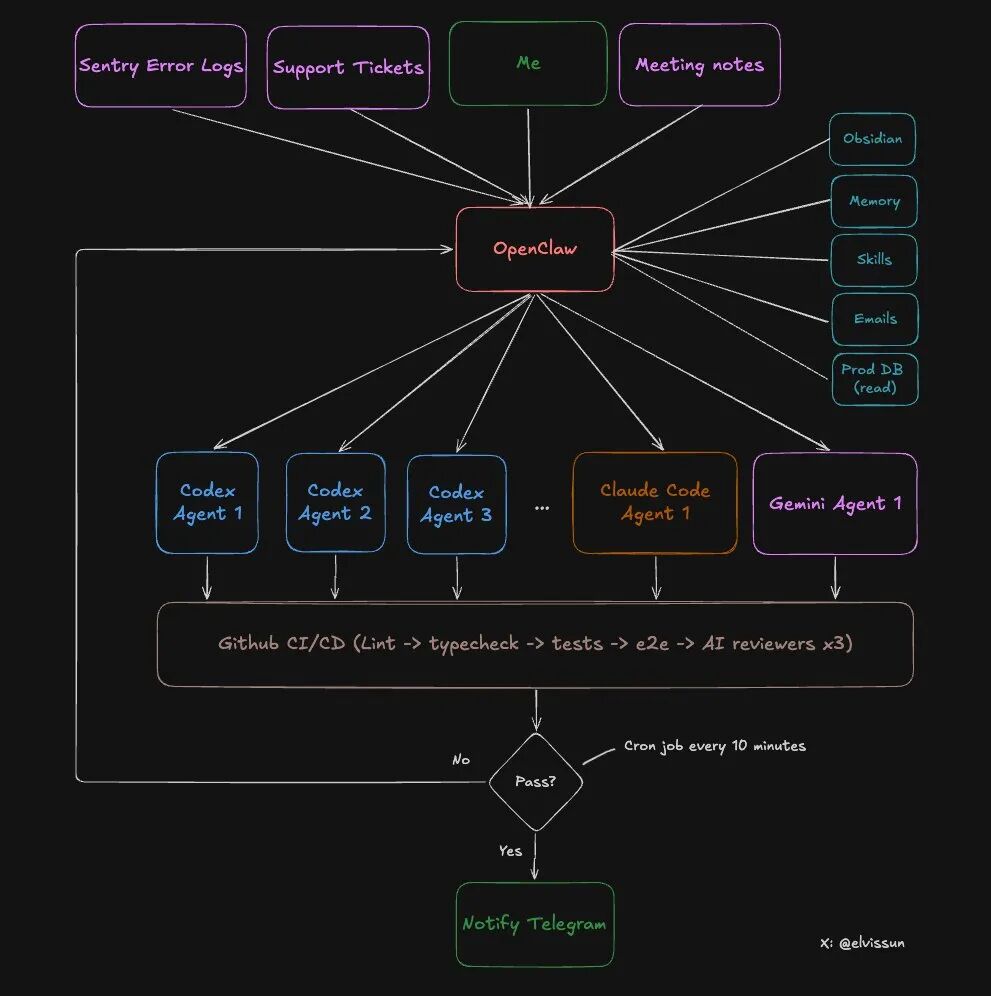
To lag, hver med sitt ansvar:

Hva kan OpenClaw (koordinasjonslag) gjøre?
- Lese alle møtereferater i Obsidian-notatene (automatisk synkronisering)
- Få tilgang til produksjonsdatabasen (kun lesetilgang) for å hente kundeoppsett
- Har administrator API-rettigheter, kan direkte lade opp kunder og fjerne blokkeringer
- Velge passende agent basert på oppgavetype
- Overvåke fremdriften til alle agenter, analysere årsaken til feil og justere prompt for å prøve igjen
- Varsle forfatteren via Telegram når oppgaven er fullført
Hva kan Agent (utførelseslag) gjøre?
- Lese og skrive i kodebasen
- Kjøring av tester og bygging
- Innsending av kode og oppretting av PR
- Svare på tilbakemeldinger fra kodegjennomgang

Dette designet er smart: sikkerhetsgrensen er klar, samtidig som det sikrer effektivitet.
Fullstendig arbeidsflyt: Fra kundens behov til PR-sammenslåing i 8 trinn
Nå går vi inn i kjernen av saken. Med et ekte eksempel fra forfatterens forrige uke, tar vi deg gjennom hele prosessen.
Bakgrunn: En bedriftskunde ringte og sa at de ønsket å gjenbruke sine allerede konfigurerte innstillinger for å dele i teamet.
Trinn 1: Kundens behov → OpenClaw forstår og bryter det ned
Etter samtalen snakket forfatteren med Zoe (hans OpenClaw) om dette behovet.
Det magiske her: null forklaringskostnad. Fordi alle møtereferater automatisk synkroniseres til Obsidian, har Zoe allerede lest innholdet fra samtalen, vet hvem kunden er, deres forretningsscenario og eksisterende oppsett.
Forfatteren og Zoe brøt ned behovet til: lage et mal-system som lar brukeren lagre og redigere eksisterende oppsett.
Deretter gjorde Zoe tre ting:
- Lade opp kunden — Brukte administrator API for å umiddelbart fjerne kundens bruksbegrensninger
- Hente kundeoppsett — Fikk eksisterende innstillinger fra produksjonsdatabasen (kun lesetilgang)
- Generere prompt og starte agent — Pakket all kontekst og ga det til Codex
Trinn 2: Starte agent
Zoe opprettet for denne oppgaven:
- Et uavhengig git worktree (isolert grenmiljø)
- En tmux-økt (lar Agent kjøre i bakgrunnen)
# Opprett worktree + start agent git worktree add ../feat-custom-templates -b feat/custom-templates origin/main cd ../feat-custom-templates && pnpm install
tmux new-session -d -s "codex-templates" \ -c "/Users/elvis/Documents/GitHub/medialyst-worktrees/feat-custom-templates" \ "$HOME/.codex-agent/run-agent.sh templates gpt-5.3-codex high Hvorfor bruke tmux? Fordi det lar deg gripe inn underveis.
Hvis AI går feil, trenger du ikke å drepe og starte på nytt, bare gi kommandoer direkte i tmux:
# Agenten går i feil retning tmux send-keys -t codex-templates "Stopp litt. Gjør API-laget først, ikke bry deg om UI." Enter
Agenten trenger mer kontekst
tmux send-keys -t codex-templates "Type definert i src/types/template.ts, bruk den." Enter Samtidig vil oppgaven bli registrert i en JSON-fil: [[HTMLPLACEHOLDER0]]
[[HTMLPLACEHOLDER1]]
[[HTMLPLACEHOLDER2]]
[[HTMLPLACEHOLDER3]]
[[HTMLPLACEHOLDER4]]
[[HTMLPLACEHOLDER5]]
[[HTMLPLACEHOLDER6]]
[[HTMLPLACEHOLDER7]]
[[HTMLPLACEHOLDER8]]
[[HTMLPLACEHOLDER9]]
[[HTMLPLACEHOLDER10]]
[[HTMLPLACEHOLDER11]]
[[HTMLPLACEHOLDER12]]
[[HTMLPLACEHOLDER13]] [[HTMLPLACEHOLDER14]] [[HTMLPLACEHOLDER15]] [[HTMLPLACEHOLDER16]] [[HTMLPLACEHOLDER17]]
[[HTMLPLACEHOLDER18]]
[[HTMLPLACEHOLDER19]]
[[HTMLPLACEHOLDER20]]
[[HTMLPLACEHOLDER21]]
[[HTMLPLACEHOLDER22]]
[[HTMLPLACEHOLDER23]]
[[HTMLPLACEHOLDER24]]
[[HTMLPLACEHOLDER25]]
[[HTMLPLACEHOLDER26]]
[[HTMLPLACEHOLDER27]]
[[HTMLPLACEHOLDER28]]
[[HTMLPLACEHOLDER29]]
[[HTMLPLACEHOLDER30]]Fullstendig prosess fra kundens behov til kodeutgivelse kan ta bare 1-2 timer, mens forfatterens faktiske innsats kanskje bare var 10 minutter.
Tre mekanismer for å gjøre systemet smartere
Mekanisme 1: Forbedret Ralph Loop — ikke bare gjentakelse, men læring
Du har kanskje hørt om Ralph Loop: hente kontekst fra minnet → generere utdata → evaluere resultater → lagre læring.
Men de fleste implementeringer har et problem: hver syklus bruker den samme prompten. Det som læres forbedrer fremtidig søk, men prompten i seg selv er statisk.
Dette systemet er annerledes.
Når Agent feiler, vil Zoe ikke starte på nytt med den samme prompten. Hun vil ta med seg full forretningskontekst, analysere årsaken til feilen, og deretter omskrive prompten:
❌ Dårlig eksempel (statisk prompt): { "Implementer tilpasset malfunksjon" }
✅ Godt eksempel (dynamisk justering): { "Stopp. Kunden ønsker X, ikke Y. Dette er deres ord fra møtet: Vi ønsker å bevare eksisterende konfigurasjon, ikke lage noe nytt fra bunnen av. Fokuser på konfigurasjonsgjenbruk, ikke på å lage nye prosesser." }Zoe kan gjøre denne justeringen fordi hun har konteksten som utførelseslaget Agent ikke har:
- Hva kunden sa i møtet
- Hva selskapet driver med
- Hvorfor lignende forespørsel feilet sist
- Om morgenen: skanner Sentry → oppdager 4 nye feil → starter 4 Agenter for å undersøke og fikse
- Etter møtet: skanner møtereferater → oppdager 3 funksjonsbehov nevnt av kunden → starter 3 Codex
- Om kvelden: skanner git log → starter Claude Code for å oppdatere changelog og kundedokumentasjon
Suksessmønstre blir dokumentert:
- "Denne promptstrukturen er veldig effektiv for faktureringsfunksjonen"
- "Codex trenger å få type definisjoner på forhånd"
- "Må alltid inkludere testfilbane"
Jo lenger tid, jo bedre blir promptene Zoe skriver, fordi hun husker hva som kan lykkes.
Mekanisme 2: Agentvalgstrategi — forskjellige oppgaver, forskjellige eksperter
Ikke alle Agenter er like sterke. Forfatterens oppsummerte valgstrategi:
- Codex(gpt-5.3-codex) — Hovedkraften - backend-logikk, komplekse feil, flerfils omstrukturering, oppgaver som krever tverrkodebibliotekresonnement
- Langsom, men grundig
- Utgjør 90% av oppgavene
- Claude Code(claude-opus-4.5) — Hastighetsutøver - frontend-arbeid
- Få tillatelsesproblemer, egnet for git-operasjoner
- (Forfatteren brukte dette mer før, men byttet etter at Codex 5.3 kom ut)
- Gemini — Designer - har designestetikk
- For vakre UI, la Gemini generere HTML/CSS-spesifikasjoner først, deretter gi det til Claude Code for implementering i komponent systemet
- Gemini designer, Claude bygger
Mekanisme 3: Hvor er flaskehalsen? RAM
Her er det en uventet begrensning: ikke token kostnad, ikke API-hastighet, men minne.
Hver Agent trenger:
- Egen worktree
- Egen nodemodules
- Kjør bygge, typekontroll, tester
Forfatterens Mac Mini (16GB RAM) kan maksimalt kjøre 4-5 Agenter samtidig, mer enn det begynner å bytte, og man må be til gudene om at de ikke bygger samtidig.## Du kan også sette opp: Fra null til drift på bare 10 minutter
Vil du prøve dette systemet?
Den enkleste måten:
Kopier hele denne artikkelen til OpenClaw, og si til den: "I henhold til denne arkitekturen, implementer et Agent-klynge-system for mitt kodebibliotek."
Så vil den:
- Lese arkitekturdesign
- Opprette skript
- Sette opp katalogstruktur
- Konfigurere cron-overvåking
Du må forberede:
- OpenClaw-konto
- API-tilgang til Codex og/eller Claude Code
- Et git-repositorium
- (valgfritt) Obsidian for å lagre forretningskonteksten
2026: En million dollar bedrift for én person
Forfatteren sa noe inspirerende på slutten av artikkelen:
"Vi vil se mange million dollar bedrifter for én person begynne å dukke opp fra 2026. Giret er enormt, og tilhører de som forstår hvordan man bygger selvforbedrende AI-systemer."
Dette er hvordan det ser ut:
- En AI-koordinator som din forlengelse (som Zoe for forfatteren)
- Delegering av arbeid til spesialiserte Agenter, som håndterer forskjellige forretningsfunksjoner
- Ingeniørfag, kundestøtte, drift, markedsføring
- Hver Agent fokuserer på det de er gode på
- Du forblir fokusert og har full kontroll
Nå er det altfor mye søppelinnhold generert av AI. Ulike hype, forskjellige fancy demoer av "oppgavekontrollsentre", men ingenting virkelig nyttig.
Forfatteren sier han ønsker å gjøre det motsatte: mindre hype, mer dokumentasjon av den virkelige byggeprosessen. Virkelige kunder, ekte inntekter, ekte innleveringer publisert til produksjonsmiljøet, og også ekte feil.
Denne artikkelen slutter her.
Kjernepunkter oppsummert:
- Dobbeltlagsarkitektur: Orkestreringslaget holder forretningskonteksten, utførelseslaget fokuserer på kode
- Full automatisering: 8-trinns prosess fra krav til PR, de fleste oppgaver lykkes ved første forsøk
- Dynamisk læring: ikke gjentatt utførelse, men justering av strategi basert på årsaken til feil
- Kostnadskontroll: starter på $20/måned, tung bruk $190/måned
Referanseadresse:[[HTMLPLACEHOLDER_31]]



