OpenClaw + Claude Code Super Tutorial: Um único desenvolvedor pode montar uma equipe de desenvolvimento completa!
OpenClaw + Claude Code Super Tutorial: Um único desenvolvedor pode montar uma equipe de desenvolvimento completa!
Hoje vou compartilhar um caso prático incrível. (Tutorial no final)
Um desenvolvedor independente usou OpenClaw + Codex/CC para montar um sistema de Agente de IA. Quais foram os resultados?
94 submissões em um dia, 7 PRs concluídos em 30 minutos, e nesse mesmo dia ele teve 3 reuniões com clientes, sem sequer abrir o editor.
Isso realmente aconteceu em janeiro de 2026. O autor tornou pública toda a arquitetura do sistema, fluxo de trabalho e configuração de código. Depois de ver, achei que essa abordagem vale a pena aprender, então organizei este artigo para compartilhar com você.
Se você também está usando Codex ou Claude Code, ou se tem interesse em OpenClaw, este artigo vai te inspirar muito.
Um único desenvolvedor, 94 submissões de código em um dia
Vamos ver alguns dados para sentir o poder deste sistema:
- Máximo de 94 submissões em um único dia (média de 50 submissões por dia)
- 7 PRs concluídos em 30 minutos
- A velocidade de levar uma ideia ao lançamento é tão rápida que pode "entregar a demanda do cliente no mesmo dia"
E quanto ao custo? $190 por mês (Claude $100 + Codex $90), iniciantes podem começar com apenas $20.
Você pode estar se perguntando: isso não é apenas empilhar uma série de ferramentas de IA e gerar código lixo de forma frenética?
Não é. O histórico do Git do autor parece "como se tivesse acabado de contratar uma equipe de desenvolvedores", mas na verdade é apenas ele. A mudança chave é: ele passou de "gerenciar Claude Code" para "gerenciar um mordomo de IA, que por sua vez gerencia um grupo de Claude Code".
- Antes de janeiro: escrevendo código diretamente com Codex ou Claude Code
- Depois de janeiro: usando OpenClaw como camada de orquestração, permitindo que ele agende Codex/Claude Code/Gemini
Por que usar Codex e Claude Code separadamente não é suficiente?
Nesse momento, você pode estar pensando: Codex e Claude Code já são muito poderosos, por que adicionar uma camada de orquestração?
A resposta do autor é direta: Codex e Claude Code quase não sabem nada sobre o seu negócio. Eles apenas veem o código, não a imagem completa do negócio.
Aqui existe uma limitação fundamental: a janela de contexto é fixa, você só pode escolher um dos dois.
Você deve escolher o que colocar dentro:
- Preencher com código → sem espaço para o contexto do negócio
- Preencher com histórico do cliente → sem espaço para o repositório de código
- Ele não sabe para qual cliente essa funcionalidade está sendo desenvolvida
- Ele não sabe por que a última solicitação semelhante falhou
- Ele não sabe a sua posição de produto e princípios de design
- Ele só pode trabalhar com o código atual e seu prompt
Ele atua como uma camada de orquestração, situada entre você e todas as ferramentas de IA. Seu papel é:
- Manter todo o contexto do negócio (dados dos clientes, atas de reuniões, decisões históricas, casos de sucesso/falha)
- Traduzir o contexto do negócio em prompts precisos, alimentando-os para agentes específicos
- Permitir que esses agentes se concentrem no que eles fazem de melhor: escrever código
- Codex/Claude Code = Chefs profissionais, apenas cozinhando
- OpenClaw = Chef principal, que conhece o gosto dos clientes, o estoque de ingredientes, a posição do menu, dando instruções precisas a cada chef
Arquitetura específica do sistema de duas camadas: camada de orquestração + camada de execução
Vamos dar uma olhada na arquitetura específica deste sistema.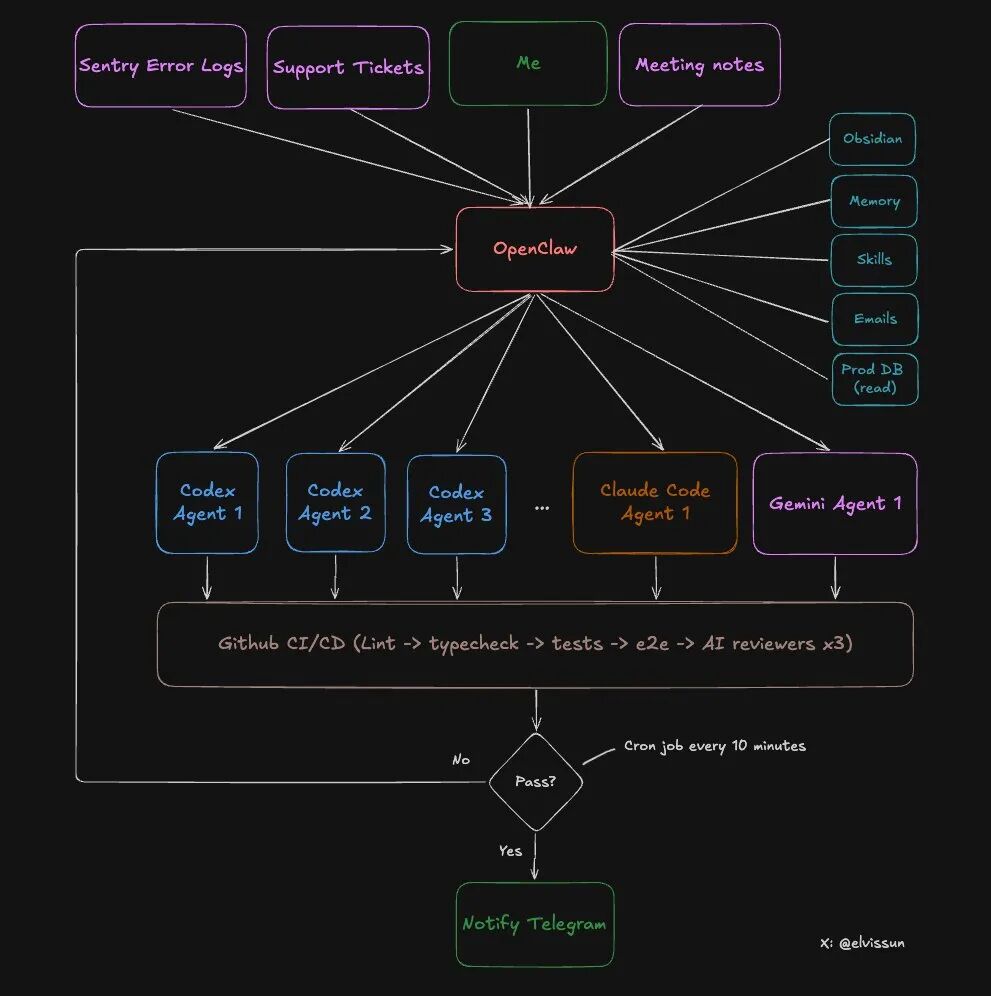
Duas camadas, cada uma com sua função:

O que o OpenClaw (Camada de Orquestração) pode fazer?
- Ler todos os registros de reuniões nas notas do Obsidian (sincronização automática)
- Acessar o banco de dados de produção (permissão somente leitura) para obter configurações de clientes
- Ter acesso à API de administrador, podendo recarregar e desbloquear clientes diretamente
- Escolher o agente apropriado com base no tipo de tarefa
- Monitorar o progresso de todos os agentes, analisando falhas e ajustando o prompt para nova tentativa
- Notificar o autor via Telegram após a conclusão
O que o Agent (Camada de Execução) pode fazer?
- Ler e escrever no repositório de código
- Executar testes e compilações
- Submeter código e criar PR
- Responder ao feedback da revisão de código

Esse design é inteligente: a fronteira de segurança é clara, garantindo eficiência.
Fluxo de Trabalho Completo: 8 Passos da Demanda do Cliente até a Mesclagem do PR
Agora vamos para a parte central. Usaremos um caso real do autor da semana passada para guiá-lo através do fluxo completo.
Contexto: Um cliente corporativo ligou, dizendo que gostaria de reutilizar suas configurações já configuradas e compartilhá-las dentro da equipe.
Passo 1: Demanda do Cliente → OpenClaw Entende e Desmonta
Após a ligação, o autor conversou com Zoe (seu OpenClaw) sobre essa demanda.
Aqui está a mágica: custo de explicação zero. Como todos os registros de reuniões são sincronizados automaticamente com o Obsidian, Zoe já leu o conteúdo da chamada e sabe quem é o cliente, seu cenário de negócios e configurações existentes.
O autor e Zoe desmontaram a demanda em: criar um sistema de templates para que os usuários possam salvar e editar as configurações existentes.
Então Zoe fez três coisas:
- Recarregou o cliente — usou a API de administrador para remover imediatamente as restrições de uso do cliente
- Buscou as configurações do cliente — obteve as configurações existentes do banco de dados de produção (somente leitura)
- Gerou o prompt e iniciou o agente — empacotou todo o contexto e alimentou o Codex
Passo 2: Iniciar o Agente
Zoe criou para essa tarefa:
- Uma worktree git independente (ambiente de branch isolado)
- Uma sessão tmux (para que o Agent funcione em segundo plano)
# Criar worktree + iniciar agente git worktree add ../feat-custom-templates -b feat/custom-templates origin/main cd ../feat-custom-templates && pnpm install
tmux new-session -d -s "codex-templates" \ -c "/Users/elvis/Documents/GitHub/medialyst-worktrees/feat-custom-templates" \ "$HOME/.codex-agent/run-agent.sh templates gpt-5.3-codex high Por que usar tmux? Porque permite intervenções a qualquer momento.
Se a IA se desviar, não é necessário reiniciar, basta enviar comandos diretamente no tmux:
# Direção do agente errada tmux send-keys -t codex-templates "Pare um pouco. Faça a camada API primeiro, não se preocupe com a UI." Enter
O agente precisa de mais contexto
tmux send-keys -t codex-templates "A definição de tipo está em src/types/template.ts, use isso." Enter Ao mesmo tempo, a tarefa será registrada em um arquivo JSON:{ "id": "feat-custom-templates", "tmuxSession": "codex-templates", "agent": "codex", "description": "Funcionalidade de modelos de email personalizados para clientes empresariais", "repo": "medialyst", "worktree": "feat-custom-templates", "branch": "feat/custom-templates", "startedAt": 1740268800000, "status": "running", "notifyOnComplete": true }
Passo 3: Monitoramento Automático
Uma tarefa cron verifica o estado de todos os agentes a cada 10 minutos.
Ponto chave: não se trata de "perguntar" ao Agente como está o progresso (isso consome muitos tokens), mas sim de verificar fatos objetivos:
- A sessão tmux ainda está ativa?
- Foi criado um PR?
- Qual é o estado do CI?
- Se falhou, é necessário reiniciar? (máximo de 3 tentativas)
Na verdade, esta é uma versão aprimorada do Ralph Loop, que será detalhada mais adiante.
Passo 4: Agente Cria PR
O Agente termina de escrever o código, faz o commit, faz o push e então cria o PR usando gh pr create --fill.
Nota: neste momento, o autor não receberá notificação. Porque um PR por si só não representa "concluído".
A definição de "concluído" é:
- ✅ PR foi criado
- ✅ Branch foi sincronizado com o main (sem conflitos)
- ✅ CI passou (lint, verificação de tipos, testes unitários, testes E2E)
- ✅ Revisão do Codex aprovada
- ✅ Revisão do Claude aprovada
- ✅ Revisão do Gemini aprovada
- ✅ Se houver alterações na UI, deve incluir capturas de tela
Passo 5: Revisão de Código Automatizada
Cada PR será revisado por três Agentes:
- Revisor Codex — O revisor mais confiável - especializado em identificar casos limites
- Capaz de detectar erros lógicos, tratamento de erros ausentes, condições de corrida
- Taxa de falsos positivos muito baixa
- Revisor de Assistência de Código Gemini — Gratuito e fácil de usar - capaz de descobrir problemas de segurança e escalabilidade que outros revisores podem ter perdido
- Fornecerá sugestões específicas de correção
- Não custa nada usar
- Revisor de Código Claude — Basicamente inútil - excessivamente cauteloso, sempre sugere "considere adicionar..."
- A maioria das sugestões é um excesso de design
- A menos que marcado como "crítico", caso contrário, é ignorado
Passo 6: Testes Automatizados
O pipeline CI executará:
- Verificações de Lint e TypeScript
- Testes unitários
- Testes E2E
- Testes Playwright (executados em um ambiente de pré-visualização idêntico ao ambiente de produção)
Essa regra reduziu significativamente o tempo de revisão - o autor pode ver rapidamente o que foi alterado apenas olhando as capturas de tela, sem precisar acessar o ambiente de pré-visualização.
Passo 7: Revisão Manual
Agora, o autor recebe uma notificação no Telegram: "PR #341 está pronto para revisão."
Neste momento:
- CI está totalmente verde
- Os três revisores de IA aprovaram
- As capturas de tela mostraram as mudanças na UI
- Todos os casos limites foram registrados nos comentários da revisão
Passo 8: Fusão
O PR é fundido. Há uma tarefa cron diária que limpa worktrees isolados e registros de tarefas.O processo completo, desde a demanda do cliente até a implementação do código, pode levar apenas 1-2 horas, enquanto o tempo real investido pelo autor pode ser de apenas 10 minutos.
Três Mecanismos para Tornar o Sistema Mais Inteligente
Mecanismo 1: Ralph Loop Aprimorado — Não é apenas repetição, mas aprendizado
Você pode ter ouvido falar do Ralph Loop: puxar contexto da memória → gerar saída → avaliar resultados → salvar aprendizado.
Mas a maioria das implementações tem um problema: o prompt usado em cada ciclo é o mesmo. O que é aprendido melhora a recuperação futura, mas o próprio prompt é estático.
Este sistema é diferente.
Quando o Agente falha, Zoe não reinicia com o mesmo prompt. Ela traz todo o contexto de negócios, analisa a razão da falha e então reescreve o prompt:
❌ Exemplo ruim (prompt estático): { "implementar funcionalidade de template personalizado" }
✅ Exemplo bom (ajuste dinâmico): { "Pare. O que o cliente quer é X, não Y. Estas são as palavras deles na reunião: Nós queremos manter a configuração existente, em vez de criar uma nova do zero. O foco deve ser na reutilização de configurações, não na criação de novos processos." }Zoe consegue fazer esse ajuste porque ela tem um contexto que o Agente não tem:
- O que o cliente disse na reunião
- O que essa empresa faz
- Por que a última demanda semelhante falhou
- De manhã: escaneia o Sentry → encontra 4 novos erros → inicia 4 Agentes para investigar e corrigir
- Após a reunião: escaneia as atas → encontra 3 demandas de funcionalidades mencionadas pelos clientes → inicia 3 Codex
- À noite: escaneia o git log → inicia Claude Code para atualizar o changelog e a documentação do cliente
Os padrões de sucesso são registrados:
- "Essa estrutura de prompt é muito eficaz para a funcionalidade de fatura"
- "Codex precisa receber definições de tipo com antecedência"
- "Sempre deve incluir o caminho do arquivo de teste"
Quanto mais tempo passa, melhor o prompt escrito por Zoe, porque ela se lembra do que pode ter sucesso.
Mecanismo 2: Estratégia de Seleção de Agentes — Diferentes tarefas, diferentes especialistas
Nem todos os Agentes são igualmente fortes. A estratégia de seleção resumida pelo autor:
- Codex(gpt-5.3-codex) — Principal - lógica de backend, bugs complexos, refatoração de múltiplos arquivos, tarefas que exigem raciocínio entre repositórios de código
- Lento, mas completo
- Representa 90% das tarefas
- Claude Code(claude-opus-4.5) — Especialista em velocidade - trabalho de frontend
- Poucos problemas de permissão, adequado para operações git
- (O autor costumava usar mais, mas mudou após o lançamento do Codex 5.3)
- Gemini — Designer - tem senso estético
- Para uma UI bonita, primeiro deixa o Gemini gerar as especificações HTML/CSS, depois entrega ao Claude Code para implementar no sistema de componentes
- Gemini projeta, Claude constrói
Mecanismo 3: Onde está o gargalo? RAM
Aqui há uma limitação inesperada: não é o custo do token, não é a taxa da API, mas sim a memória.
Cada Agente precisa:
- Sua própria worktree
- Seus próprios nodemodules
- Executar construção, verificação de tipos, testes
O Mac Mini do autor (16GB de RAM) pode rodar no máximo 4-5 Agentes ao mesmo tempo, mais do que isso começa a usar swap, e é preciso torcer para que eles não construam ao mesmo tempo.Então ele comprou um Mac Studio M4 Max (128GB RAM, $3500), que chegou no final de março. Ele disse que compartilhará se vale a pena.
Você também pode construir: de zero a funcionando em apenas 10 minutos
Quer experimentar este sistema?
A maneira mais simples:
Copie todo este artigo para o OpenClaw e diga a ele: "De acordo com esta arquitetura, implemente um sistema de cluster de agentes para meu repositório de código."
Então, ele irá:
- Ler o design da arquitetura
- Criar scripts
- Configurar a estrutura de diretórios
- Configurar monitoramento cron
Você precisa se preparar:
- Conta OpenClaw
- Acesso à API do Codex e/ou Claude Code
- Um repositório git
- (Opcional) Obsidian para armazenar o contexto de negócios
2026: A Empresa de Um Milhão de Dólares de Uma Só Pessoa
O autor disse uma frase no final que achei muito inspiradora:
"Veremos uma grande quantidade de empresas de um milhão de dólares surgindo a partir de 2026. O poder é enorme, pertencendo àqueles que entendem como construir sistemas de IA de autoaperfeiçoamento recursivo."
Isso é como se parece:
- Um orquestrador de IA como sua extensão (assim como Zoe para o autor)
- Delegar trabalho a agentes especializados, lidando com diferentes funções de negócios
- Engenharia, suporte ao cliente, operações, marketing
- Cada agente se concentra no que faz melhor
- Você mantém o foco e o controle total
Agora, há muito conteúdo lixo gerado por IA. Todo tipo de exagero, todo tipo de demo chamativa de "centro de controle de tarefas", mas nada realmente útil.
O autor disse que quer fazer o oposto: menos exagero, mais registro do verdadeiro processo de construção. Clientes reais, receita real, submissões reais publicadas no ambiente de produção, e também falhas reais.
Este artigo termina aqui.
Revisão dos pontos principais:
- Arquitetura em camadas: a camada de orquestração mantém o contexto de negócios, a camada de execução foca no código
- Automação completa: um processo de 8 etapas do requisito ao PR, a maioria das tarefas bem-sucedidas de primeira
- Aprendizado dinâmico: não é execução repetida, mas ajuste de estratégia com base nas razões das falhas
- Custos controláveis: começando em $20/mês, uso intenso $190/mês
Referência:[[HTMLPLACEHOLDER0]][[HTMLPLACEHOLDER1]][[HTMLPLACEHOLDER2]][[HTMLPLACEHOLDER3]][[HTMLPLACEHOLDER4]][[HTMLPLACEHOLDER_5]]



