OpenClaw + Claude Code 超强教程:一个人就能搭建完整的开发团队!
OpenClaw + Claude Code 超强教程:一个人就能搭建完整的开发团队!
Idag delar jag med mig av ett fantastiskt praktiskt exempel. (En guide finns i slutet av artikeln)
En oberoende utvecklare har med hjälp av OpenClaw + Codex/CC byggt ett AI Agent-system. Vilka resultat har han uppnått?
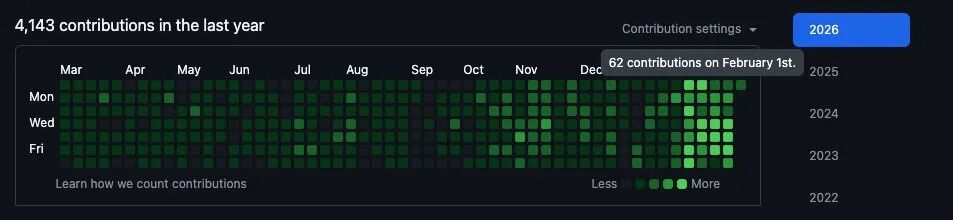
94 commits på en dag, 7 PR:er färdiga på 30 minuter, och under denna dag hade han även 3 kundmöten utan att ens öppna sin editor.
Detta hände faktiskt i januari 2026. Författaren har offentliggjort hela systemets arkitektur, arbetsflöde och kodkonfiguration. Efter att ha läst detta kände jag att denna metod är värd att lära sig, så jag har sammanställt det i denna artikel för att dela med dig.
Om du också använder Codex eller Claude Code, eller är intresserad av OpenClaw, kommer denna artikel att ge dig mycket inspiration.
En person, 94 kodcommits på en dag
Låt oss titta på några siffror för att känna av kraften i detta system:
- Högsta antal commits på en dag: 94 (genomsnittligt 50 commits per dag)
- 7 PR:er färdiga på 30 minuter
- Från idé till lansering så snabbt att man kan "leverera kundens krav samma dag"
Vad kostar det? $190 per månad (Claude $100 + Codex $90), nybörjare kan komma igång för $20.
Du kanske undrar: Är detta bara en hög av AI-verktyg som genererar skräpkod?
Nej. Författarens Git-historik ser ut som "om man just anställt ett utvecklingsteam", men i verkligheten är det bara han själv. Den avgörande förändringen är: han har gått från att "hantera Claude Code" till att "hantera en AI-assistent som i sin tur hanterar en grupp Claude Code".
- Före januari: Skriva kod direkt med Codex eller Claude Code
- Efter januari: Använda OpenClaw som en orkestreringsnivå för att schemalägga Codex/Claude Code/Gemini
Varför är Codex och Claude Code inte tillräckligt bra att använda var för sig?
Vid det här laget kanske du tänker: Codex och Claude Code är redan mycket kraftfulla, varför behövs det ett extra lager av orkestrering?
Författarens svar är mycket direkt: Codex och Claude Code vet nästan ingenting om ditt företag. De ser bara koden och inte den fullständiga affärsbilden.
Här finns en grundläggande begränsning: kontextfönstret är fast, och du kan bara välja en av två.
Du måste välja vad du ska stoppa in:
- Fyllt med kod → Ingen plats för affärskontext
- Fyllt med kundhistorik → Ingen plats för kodbasen
- Den vet inte vilken kund denna funktion är för
- Den vet inte varför liknande krav misslyckades senast
- Den vet inte din produktpositionering och designprinciper
- Den kan bara arbeta utifrån den aktuella koden och din prompt
Det fungerar som en orkestreringsnivå mellan dig och alla AI-verktyg. Dess roll är:
- Hålla all affärskontext (kunddata, mötesanteckningar, historiska beslut, framgångs-/misslyckandescenarier)
- Översätta affärskontexten till exakta prompts och mata dem till specifika agenter
- Låta dessa agenter fokusera på det de är bra på: skriva kod
- Codex/Claude Code = professionella kockar, som bara lagar mat
- OpenClaw = köksmästare, som vet kundernas smak, ingredienslager och menypositionering, och ger varje kock exakta instruktioner
Den specifika arkitekturen för dubbellagersystemet: orkestreringsnivå + exekveringsnivå
Låt oss titta på den specifika arkitekturen för detta system.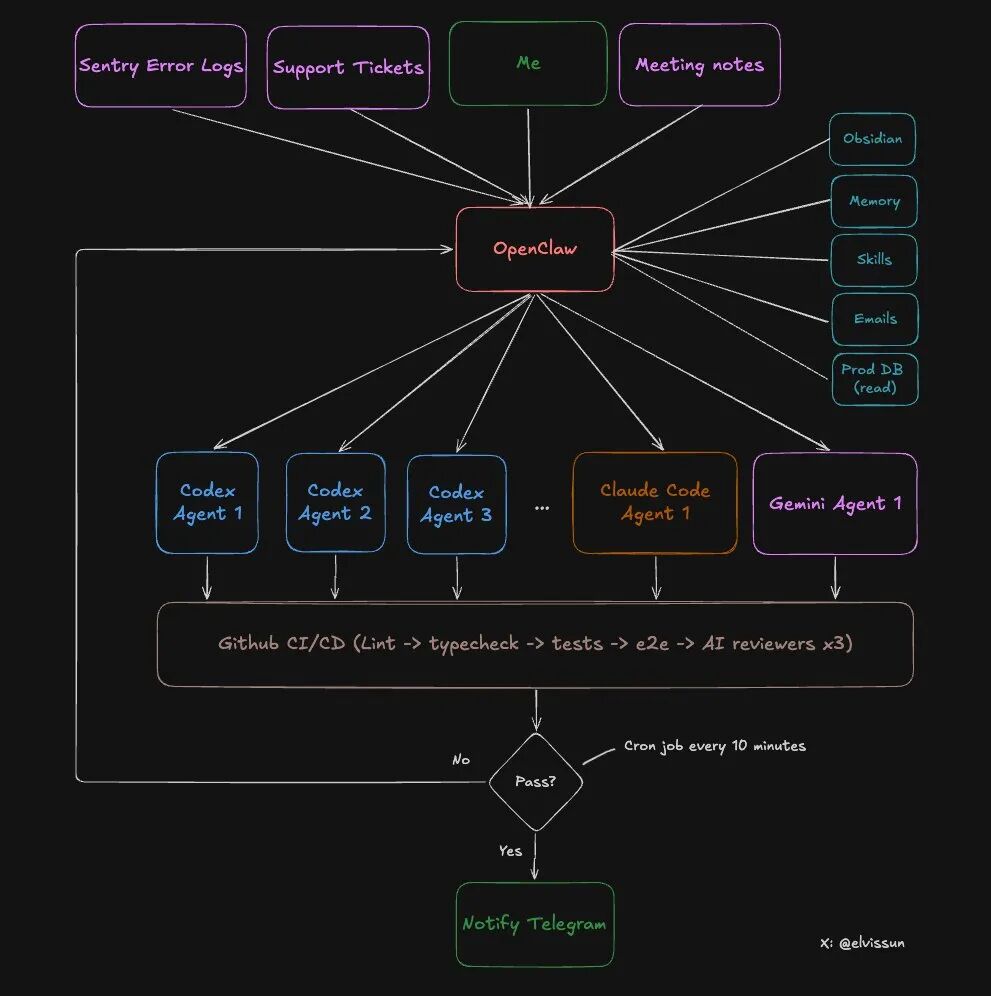
Två lager, var och en med sina uppgifter:

Vad kan OpenClaw (Orkestreringslager) göra?
- Läsa alla mötesprotokoll i Obsidian anteckningar (automatisk synkronisering)
- Åtkomst till produktionsdatabasen (endast läsbehörighet) för att hämta kundkonfigurationer
- Har administratörs-API-behörighet, kan direkt ge kunderna uppladdningar för att ta bort blockeringar
- Välja lämplig agent baserat på uppgiftstyp
- Övervaka alla agenters framsteg, om det misslyckas analyserar det orsaken och justerar prompten för att försöka igen
- Meddela författaren via Telegram när det är klart
Vad kan Agent (Exekveringslager) göra?
- Läsa och skriva i kodbasen
- Köra tester och byggen
- Skicka in kod och skapa PR
- Svara på feedback från kodgranskning

Denna design är smart: säkerhetsgränserna är tydliga och samtidigt garanterar den effektivitet.
Fullständig arbetsflöde: 8 steg från kundens krav till PR-sammanslagning
Nu går vi in i kärndelen. Med ett verkligt exempel från förra veckan tar jag dig genom hela processen.
Bakgrund: En företagskund ringde och sa att de ville återanvända sina redan konfigurerade inställningar för att dela inom teamet.
Steg 1: Kundens krav → OpenClaw förstår och bryter ner
Efter samtalet diskuterade författaren och Zoe (hans OpenClaw) detta krav.
Det fantastiska här: ingen förklaringskostnad. Eftersom alla mötesprotokoll automatiskt synkroniseras till Obsidian, hade Zoe redan läst samtalsinnehållet och visste vem kunden var, deras affärsscenario och befintliga konfiguration.
Författaren och Zoe bröt ner kravet till: skapa ett mallssystem så att användare kan spara och redigera befintliga konfigurationer.
Sedan gjorde Zoe tre saker:
- Laddade upp kunden — använde administratörs-API för att omedelbart ta bort kundens användarbegränsningar
- Hämtade kundkonfiguration — hämtade kundens befintliga inställningar från produktionsdatabasen (endast läsning)
- Genererade prompt och startade agenten — paketerade all kontext och matade den till Codex
Steg 2: Starta agenten
Zoe skapade för denna uppgift:
- En oberoende git worktree (isolerad grenmiljö)
- En tmux-session (så att Agent kan köras i bakgrunden)
# 创建 worktree + 启动代理 git worktree add ../feat-custom-templates -b feat/custom-templates origin/main cd ../feat-custom-templates && pnpm install
tmux new-session -d -s "codex-templates" \ -c "/Users/elvis/Documents/GitHub/medialyst-worktrees/feat-custom-templates" \ "$HOME/.codex-agent/run-agent.sh templates gpt-5.3-codex high Varför använda tmux? För att kunna ingripa mitt i processen.
Om AI går fel, behöver man inte döda och börja om, man kan direkt ge kommandon i tmux:
# 代理方向错了 tmux send-keys -t codex-templates "Stanna. Gör API-lagret först, skit i UI." Enter
代理需要更多上下文
tmux send-keys -t codex-templates "Typdefinition finns i src/types/template.ts, använd den." Enter Samtidigt kommer uppgiften att registreras i en JSON-fil: [[HTMLPLACEHOLDER0]] [[HTMLPLACEHOLDER1]] [[HTMLPLACEHOLDER2]] [[HTMLPLACEHOLDER3]] [[HTMLPLACEHOLDER4]] [[HTMLPLACEHOLDER5]] [[HTMLPLACEHOLDER6]] [[HTMLPLACEHOLDER7]] [[HTMLPLACEHOLDER8]] [[HTMLPLACEHOLDER9]] [[HTMLPLACEHOLDER10]] [[HTMLPLACEHOLDER11]] [[HTMLPLACEHOLDER12]] [[HTMLPLACEHOLDER13]] [[HTMLPLACEHOLDER14]] [[HTMLPLACEHOLDER15]] [[HTMLPLACEHOLDER16]] [[HTMLPLACEHOLDER17]] [[HTMLPLACEHOLDER18]] [[HTMLPLACEHOLDER19]] [[HTMLPLACEHOLDER20]] [[HTMLPLACEHOLDER21]] [[HTMLPLACEHOLDER22]] [[HTMLPLACEHOLDER23]] [[HTMLPLACEHOLDER24]] [[HTMLPLACEHOLDER25]] [[HTMLPLACEHOLDER26]] [[HTMLPLACEHOLDER27]] [[HTMLPLACEHOLDER28]]Hela processen från kundens krav till kodutgåvan kan ta endast 1-2 timmar, medan författarens faktiska insats kanske bara var 10 minuter.
Tre mekanismer för att göra systemet smartare
Mekanism 1: Förbättrad Ralph Loop — Inte bara upprepning, utan lärande
Du kanske har hört talas om Ralph Loop: hämta kontext från minnet → generera utdata → utvärdera resultat → spara lärande.
Men de flesta implementationer har ett problem: varje cykel använder samma prompt. Det som lärs sig förbättrar framtida hämtningar, men prompten i sig är statisk.
Detta system är annorlunda.
När Agenten misslyckas, kommer Zoe inte att starta om med samma prompt. Hon kommer att ta med sig hela affärskontexten, analysera orsaken till misslyckandet och sedan skriva om prompten:
❌ Dåligt exempel (statisk prompt): { "Implementera anpassad mallfunktion" }
✅ Bra exempel (dynamisk justering): { "Stopp. Kunden vill ha X, inte Y. Detta är deras exakta ord från mötet: Vi vill spara den befintliga konfigurationen, istället för att skapa en ny från grunden. Fokusera på att återanvända konfigurationen, gör inte en ny process." }Zoe kan göra denna justering eftersom hon har kontext som exekveringslagret Agenten inte har:
- Vad kunden sa på mötet
- Vad företaget gör
- Varför liknande krav misslyckades senast
- Morgon: skanna Sentry → upptäck 4 nya fel → starta 4 Agenten för att undersöka och åtgärda
- Efter mötet: skanna mötesprotokoll → upptäck 3 funktionalitetskrav nämnda av kunder → starta 3 Codex
- Kväll: skanna git log → starta Claude Code för att uppdatera changelog och kunddokument
Framgångsrika mönster kommer att dokumenteras:
- "Denna promptstruktur är mycket effektiv för faktureringsfunktionen"
- "Codex behöver få typdefinitioner i förväg"
- "Måste alltid inkludera sökväg till testfiler"
Ju längre tid som går, desto bättre blir de promptar som Zoe skriver, eftersom hon minns vad som kan lyckas.
Mekanism 2: Agentvalstrategi — Olika uppgifter, olika experter
Inte alla Agenten är lika starka. Författaren sammanfattar valstrategin:
- Codex(gpt-5.3-codex) — Huvudaktör - backend-logik, komplexa buggar, flerfilsomstrukturering, uppgifter som kräver resonemang över kodbaser
- Långsam men grundlig
- Utgör 90% av uppgifterna
- Claude Code(claude-opus-4.5) — Hastighetsfokuserad - frontend-arbete
- Färre behörighetsproblem, lämplig för git-operationer
- (Författaren använde det oftare tidigare, men bytte efter att Codex 5.3 kom ut)
- Gemini — Designer - har designestetik
- För vacker UI, låt först Gemini generera HTML/CSS-specifikationer, och överlämna sedan till Claude Code för implementering i komponent-systemet
- Gemini designar, Claude bygger
Mekanism 3: Var är flaskhalsen? RAM
Här finns en oväntad begränsning: det handlar inte om token-kostnader, inte om API-hastighet, utan om minne.
Varje Agent behöver:
- Sin egen worktree
- Sin egen nodemodules
- Köra bygg, typkontroll, tester
Författarens Mac Mini (16GB RAM) kan maximalt köra 4-5 Agenten samtidigt, fler än så börjar swap och man måste be till gudarna att de inte bygger samtidigt.## Du kan också bygga: Från noll till drift på bara 10 minuter
Vill du prova detta system?
Det enklaste sättet:
Kopiera hela denna artikel till OpenClaw och säg till den: "Implementera ett Agent-kluster system för mitt kodbibliotek enligt denna arkitektur."
Då kommer den att:
- Läsa arkitekturdesignen
- Skapa skript
- Ställa in katalogstrukturen
- Konfigurera cron-övervakning
Du behöver förbereda:
- OpenClaw-konto
- API-åtkomst till Codex och/eller Claude Code
- Ett git-förråd
- (valfritt) Obsidian för att lagra affärssammanhang
2026: En persons miljon dollar företag
Författaren säger en inspirerande sak i slutet av artikeln:
"Vi kommer att se en mängd enpersons miljon dollar företag börja dyka upp från 2026. Hävstången är enorm, och den tillhör dem som förstår hur man bygger rekursivt självförbättrande AI-system."
Det ser ut så här:
- En AI-koordinator som din förlängning (som Zoe för författaren)
- Delegerar arbete till specialiserade agenter som hanterar olika affärsfunktioner
- Ingenjörskonst, kundsupport, drift, marknadsföring
- Varje agent fokuserar på det den är bra på
- Du förblir fokuserad och har full kontroll
Nu finns det för mycket skräpinnehåll som genereras av AI. Olika hypen, olika "uppgiftskontrollcentraler" med flashy demo, men inget verkligt användbart.
Författaren säger att han vill göra motsatsen: mindre hype, mer dokumentation av den verkliga byggprocessen. Verkliga kunder, verkliga intäkter, verkliga inlämningar publicerade i produktionsmiljö, och även verkliga misslyckanden.
Denna artikel slutar här.
Kärnpoänger att återkalla:
- Dubbelstruktur: koordineringslagret har affärssammanhang, exekveringslagret fokuserar på kod
- Fullständig automatisering: 8-stegsprocess från krav till PR, de flesta uppgifter lyckas på första försöket
- Dynamisk inlärning: inte upprepad exekvering, utan justering av strategin baserat på orsaken till misslyckandet
- Kostnadskontroll: starta $20/månad, tung användning $190/månad
Referensadress:[[HTMLPLACEHOLDER_29]]



