OpenClaw + Claude Code/Codex: Erstellung eines persönlichen Entwicklungs-Agenten-Swarms
OpenClaw + Claude Code/Codex: Erstellung eines persönlichen Entwicklungs-Agenten-Swarms
Hallo zusammen, ich bin Lu Gong.
Vor kurzem habe ich auf X einen Tweet gesehen, der sofort meine Aufmerksamkeit erregte. Ein unabhängiger Entwickler namens Elvis sagte, dass er jetzt nicht mehr direkt Claude Code und Codex verwendet, sondern OpenClaw als Orchestrierungsebene nutzt, um einen AI-Orchestrator namens Zoe zu verwalten, der ein ganzes Claude Code und Codex Agenten-Swarm steuert.
Die Daten zu diesem Tweet sind ebenfalls beeindruckend: 4,9 Millionen Aufrufe, 11.000 Likes, 1800 Retweets.
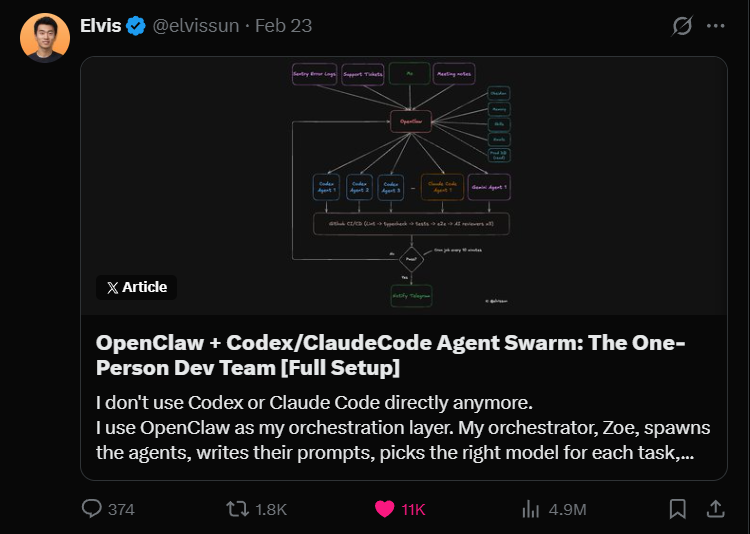 Unser Account hat Vibe Coding seit über vier Monaten, und Claude Code war immer das Hauptwerkzeug. Ich habe zuvor auch einige Artikel über Multi-Agent-Zusammenarbeit, VSCode-Multi-Agent-Architekturen usw. geschrieben.
Unser Account hat Vibe Coding seit über vier Monaten, und Claude Code war immer das Hauptwerkzeug. Ich habe zuvor auch einige Artikel über Multi-Agent-Zusammenarbeit, VSCode-Multi-Agent-Architekturen usw. geschrieben.
Aber als ich Elviss Ansatz sah, konnte ich nur sagen, dass er wirklich professionell ist. Eine Person, die mit einem Orchestrierungssystem durchschnittlich 50 Code-Commits pro Tag macht, hat an einem Tag 94 Commits abgegeben und gleichzeitig 3 Kundenanrufe entgegengenommen, ohne den Editor auch nur einmal zu öffnen.
Ist das nicht so, als würde eine Person ein ganzes Entwicklungsteam ersetzen?
Heute wird dieser Artikel analysieren, wie er das geschafft hat.
OpenClaw ist allen bekannt
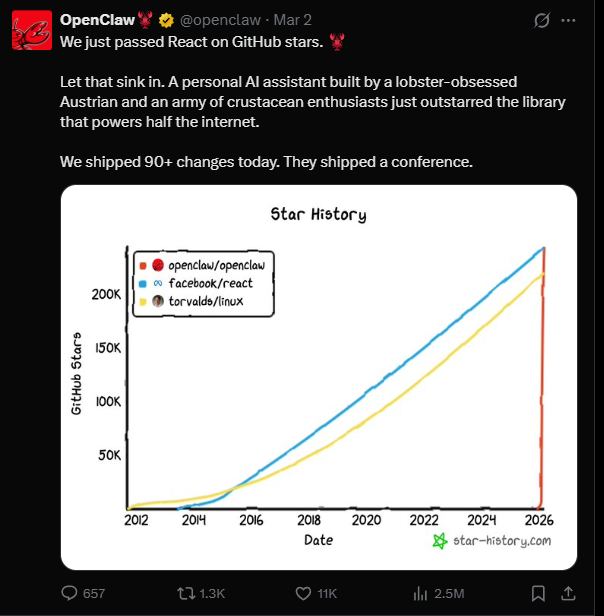
Dieser kleine Flusskrebs ist seit dem chinesischen Neujahr sehr beliebt. Einfach gesagt, es handelt sich um ein Open-Source-AI-Agenten-Framework, das auf GitHub mittlerweile über 240.000 Sterne hat und vor zwei Tagen offiziell React überholt hat, um das am schnellsten wachsende Open-Source-Projekt in der Geschichte von GitHub zu werden.
 Der Gründer Peter Steinberger ist ein österreichischer Entwickler, der zuvor PSPDFKit (ein B2B-Unternehmen für ein PDF-Framework) gegründet hat und 2021 eine Investition von 100 Millionen Euro von Insight Partners erhalten hat. Im Februar dieses Jahres kündigte Peter an, dass er zu OpenAI wechselt und das OpenClaw-Projekt an eine Open-Source-Stiftung übergibt.
Der Gründer Peter Steinberger ist ein österreichischer Entwickler, der zuvor PSPDFKit (ein B2B-Unternehmen für ein PDF-Framework) gegründet hat und 2021 eine Investition von 100 Millionen Euro von Insight Partners erhalten hat. Im Februar dieses Jahres kündigte Peter an, dass er zu OpenAI wechselt und das OpenClaw-Projekt an eine Open-Source-Stiftung übergibt.
Die Positionierung von OpenClaw ist nicht als Chatbot gedacht, sondern als eine AI-Agenten-Laufzeitumgebung, die auf deinem lokalen Gerät läuft. Es hat vier Kernkomponenten: Gateway (verbindet über 50 Messaging-Plattformen), Agent (Inferenz-Engine), Skills (über 5400 Plugins), Memory (Gedächtnissystem).
Aber Elviss Nutzung von OpenClaw ist besonders. Er verwendet es direkt als Orchestrierungsebene, um speziell Claude Code und Codex als Codierungsagenten zu verwalten, ohne es als allgemeinen Assistenten zu verwenden.
Dieser Ansatz ist in der Tat außergewöhnlich.
Warum braucht man eine Orchestrierungsebene?
Elvis erwähnte in seinem Tweet einen sehr wichtigen Punkt: Das Kontextfenster ist ein Nullsummenspiel.
Wenn du Code hineinstopfst, bleibt kein Platz für geschäftlichen Kontext. Wenn du historische Kundendaten und Besprechungsnotizen hineinstopfst, bleibt kein Platz für das Code-Repository. Selbst der stärkste AI-Agent kann nicht gleichzeitig zwei völlig unterschiedliche Arten von Informationen aufnehmen.
Deshalb hat er das System in zwei Ebenen aufgeteilt.
Die obere Ebene ist der Orchestrator Zoe von OpenClaw, der alle geschäftlichen Kontexte verwaltet, einschließlich Kundendaten, Besprechungsnotizen, historische Entscheidungen, welche Lösungen ausprobiert wurden und welche gescheitert sind. Diese Informationen sind alle in Elviss Obsidian-Notizbibliothek gespeichert, und Zoe kann sie direkt abrufen.
Die untere Ebene sind die Codierungsagenten Claude Code und Codex, die nur Code betrachten und nur Code schreiben. Jedes Mal, wenn ein Agent gestartet wird, erstellt Zoe basierend auf dem geschäftlichen Kontext einen präzisen Prompt für ihn, der ihm sagt, was zu tun ist, was der Hintergrund ist und was der Kunde will.
Einfach gesagt: Der Orchestrator ist dafür verantwortlich, die Anforderungen zu verstehen, während die Codierungsagenten die Arbeit erledigen. Jeder macht das, was er am besten kann.
Diese Architektur ähnelt dem internen System Minions, das Stripe kürzlich veröffentlicht hat. Stripes Minions sind ebenfalls ein Design aus parallelen Codierungsagenten und einer zentralisierten Orchestrierungsebene, die jede Woche über 1000 vollständig von AI geschriebene PRs zusammenführen kann. Elvis sagte, dass er zufällig eine ähnliche Architektur aufgebaut hat, die jedoch auf seinem eigenen Mac mini läuft.
Echte Anwendungsfall-Workflow
Elvis verwendete in seinem Tweet einen echten Anwendungsfall, um seinen vollständigen Workflow zu erläutern. Ich werde die Kernpunkte kurz zusammenfassen.Er nahm einen Anruf von einem Kunden entgegen, der die bestehende Konfiguration im Team wiederverwenden wollte. Nach dem Gespräch sprach er mit Zoe über dieses Bedürfnis. Da alle Besprechungsprotokolle automatisch mit Obsidian synchronisiert werden, wusste Zoe bereits, was der Kunde gesagt hatte, und Elvis musste nicht zusätzlich erklären. Gemeinsam legten sie den Funktionsumfang fest, und die endgültige Lösung war die Erstellung eines Templatesystems.
Dann erledigte Zoe automatisch drei Dinge: Sie lud den Kunden für den Entsperrservice auf (sie hat Administrator-API-Rechte), zog die bestehende Konfiguration des Kunden aus der Produktionsdatenbank (nur Leserechte, der Codex Agent wird niemals diese Rechte haben) und generierte dann einen Codex Agent, der mit einem detaillierten Prompt ausgestattet war, der den vollständigen Geschäftskontext enthielt.
Jeder Agent hat seinen eigenen unabhängigen Worktree (isolierter Branch) und tmux-Sitzung. Der Startbefehl sieht ungefähr so aus:
# Create worktree + spawn agent git worktree add ../feat-custom-templates -b feat/custom-templates origin/main cd ../feat-custom-templates && pnpm install tmux new-session -d -s "codex-templates" \ -c "/Users/elvis/Documents/GitHub/medialyst-worktrees/feat-custom-templates" \ "$HOME/.codex-agent/run-agent.sh templates gpt-5.3-codex high Nach dem Start des Agents gibt es einen Zeitplan, der alle 10 Minuten eine Überprüfung durchführt. Aber er fragt den Agenten nicht direkt (das würde zu viele Tokens verbrauchen), sondern führt ein deterministisches Shell-Skript aus, das überprüft, ob die tmux-Sitzung noch aktiv ist, ob ein PR erstellt wurde und ob CI erfolgreich war.
Wenn CI fehlschlägt, wird der Agent automatisch neu gestartet, maximal 3 Mal. Nur wenn menschliches Eingreifen erforderlich ist, wird eine Benachrichtigung gesendet.
Nachdem der Agent die Aufgabe abgeschlossen hat, wird automatisch ein PR erstellt. Aber nur das Erstellen eines PR reicht nicht aus; Elvis hat einen Satz von Abschlusskriterien definiert: PR erstellt, Branch mit main synchronisiert (keine Merge-Konflikte), CI vollständig bestanden, Codeüberprüfung durch alle drei AI-Modelle bestanden, und wenn es UI-Änderungen gibt, müssen Screenshots angehängt werden.
Drei AI-Modelle zur Codeüberprüfung
Die drei AI-Modelle zur Codeüberprüfung scheinen sehr stabil zu sein. Es ist interessant, seine Bewertungen zu diesen drei Modellen zu hören.
Codex Reviewer, er bewertet es am höchsten und sagt, dass die Überprüfung in Bezug auf Grenzfälle und logische Fehler sehr gründlich ist und die Fehlalarmrate sehr niedrig ist.
Gemini Code Assist Reviewer, kostenlos, er sagt, dass es sehr nützlich ist, um Sicherheitsrisiken und Skalierbarkeitsprobleme zu entdecken, die von anderen Modellen übersehen wurden, und es kann spezifische Lösungsvorschläge geben.
Claude Code Reviewer, sein Wortlaut ist "praktisch nutzlos", er sagt, dass es übermäßig vorsichtig ist und voller Vorschläge wie "Überlegen Sie, hinzuzufügen..." ist, die größtenteils überdesignt sind. Es sei denn, es wird als kritisches Problem gekennzeichnet, überspringt er es einfach.
Als ich diesen Abschnitt las, war ich etwas überrascht. Als intensiver Nutzer von Claude Code habe ich tatsächlich auch erlebt, dass es bei der Codeüberprüfung zu konservativ war, aber die Bewertung "praktisch nutzlos" ist doch etwas übertrieben. Dies zeigt jedoch auch, dass die Kreuzüberprüfung durch mehrere Modelle tatsächlich wertvoll ist, da die Vorurteile der verschiedenen Modelle sich gegenseitig ergänzen.
Nachdem alle drei Überprüfungen bestanden sind, erhält Elvis eine Telegram-Benachrichtigung. Bis zu diesem Punkt schaut er sich hauptsächlich die Screenshots an, um zu bestätigen, ob die UI-Änderungen korrekt sind; viele PRs merge er direkt, ohne den Code zu überprüfen. Er sagt, dass seine manuelle Überprüfung nur 5 bis 10 Minuten dauert.
Zoes Proaktivität
Zoe ist nicht nur eine Ausführende. Interessanter als der Workflow selbst ist Zoes Proaktivität.
Elvis sagt, dass Zoe nicht darauf wartet, dass ihr Aufgaben zugewiesen werden; sie sucht aktiv nach Arbeit. Morgens scannt sie die Fehlerprotokolle von Sentry, entdeckt 4 neue Fehler und generiert automatisch 4 Agents zur Behebung. Nach dem Meeting scannt sie die Protokolle, markiert 3 Funktionsanforderungen, die der Kunde erwähnt hat, und startet dann automatisch 3 Codex Agents. Abends scannt sie die Git-Protokolle und startet Claude Code, um das Changelog und die Kundendokumentation zu aktualisieren.
Wenn Elvis nach einem Spaziergang zurückkommt, liegt eine Nachricht auf Telegram: 7 PRs sind bereit, 3 neue Funktionen, 4 Bugfixes. Ist das nicht genau der Effekt, den ich mir immer für das OPC-Ein-Personen-Unternehmen-Entwicklungsteam gewünscht habe?Und wenn der Agent fehlschlägt, ist Zoes Umgang damit viel fortschrittlicher als einfaches Wiederholen. Sie analysiert die Gründe für das Scheitern unter Berücksichtigung des Geschäftskontexts. Ist der Agent-Kontext überlastet? Dann wird der Fokus eingegrenzt, sodass der Agent sich nur auf drei Dateien konzentriert. Hat der Agent die Richtung verloren? Dann wird er korrigiert und erhält die Information, dass der Kunde X und nicht Y möchte, und es wird das genaue Zitat aus dem Meeting beigefügt.
Im Laufe der Zeit wird Zoe auch Erfahrungen sammeln und sich merken, welche Prompt-Strukturen bei welchen Aufgaben gut funktionieren, um beim nächsten Mal präzisere Prompts zu erstellen.
Dieser Ansatz ist eigentlich eine verbesserte Version des Ralph Loop. Die Kernlogik des Ralph Loop besteht aus dem Ziehen des Kontexts, dem Generieren von Ausgaben, der Bewertung der Ergebnisse und dem Speichern von Erfahrungen in einem solchen Zyklus, aber die meisten Implementierungen verwenden für jeden Zyklus feste Prompts. Das System von Elvis ist anders; bei jedem Wiederholen passt Zoe die Prompts dynamisch an die Gründe für das Scheitern an und hat dabei den vollständigen Geschäftskontext zur Verfügung.
Kosten und Hardware
In Bezug auf die Kosten gibt Elvis an, dass Claude etwa 100 Dollar pro Monat und Codex etwa 90 Dollar pro Monat kostet. Er erwähnte auch, dass man mit 20 Dollar anfangen kann, um es auszuprobieren.
Diese Kosten sind im Vergleich zur Einstellung eines Entwicklers natürlich lächerlich günstig. Aber wenn man bedenkt, dass man auch eigene Produktentscheidungen treffen, mit Kunden kommunizieren und Code überprüfen muss, ähnelt es eher einem Effizienzverstärker, der einem die zeitaufwendigen Schritte des Codierens und Testens abnimmt.
In Bezug auf die Hardware erwähnte Elvis, dass sein derzeit größtes Problem der RAM ist. Jeder Agent benötigt einen eigenen Arbeitsbaum, jeder Arbeitsbaum hat seine eigenen node_modules, und jeder Agent muss bauen, Typprüfungen durchführen und testen. Wenn 5 Agenten gleichzeitig laufen, bedeutet das 5 parallele TypeScript-Compiler, 5 Testläufer und 5 Sätze von Abhängigkeiten.
Sein Mac mini mit 16 GB RAM kann maximal 4 bis 5 Agenten gleichzeitig ausführen; mehr führt zu Speicherwechsel. Daher kaufte er einen Mac Studio M4 Max mit 128 GB RAM (3500 Dollar), um mehr gleichzeitige Agenten zu unterstützen.
Zusammenfassung und reale Probleme
Ehrlich gesagt hat mich dieses System von Elvis ziemlich beeindruckt. Ich habe OpenClaw bisher immer als Spielzeug betrachtet, und bei der Steigerung der Produktivität habe ich mich auf das unabhängige Claude Code verlassen. Gelegentlich benutze ich Arbeitsbäume für Parallelität, aber es hat lange nicht das Niveau einer systematischen Anordnung erreicht. Nach dem Lesen seiner Tweets habe ich das Gefühl, dass die Grenzen des AI-Programmings erneut angehoben wurden.
Ich plane, basierend auf seinem Ansatz, OpenClaw zu verwenden, um ein vollständig automatisiertes Ein-Personen-Entwicklungsteam zu schaffen. Daher werden wir in naher Zukunft mehrere Artikel über die Praxis von OpenClaw veröffentlichen.
Es gibt einige reale Probleme, auf die ich hinweisen möchte.
Die Voraussetzung für dieses System ist, dass man ein klares Produkt, klare Kundenanforderungen und eine ausgereifte CI/CD-Pipeline hat. Elvis arbeitet an einem echten B2B-SaaS-Produkt mit Kunden, Einnahmen und Produktionsumgebungen. Wenn Sie noch Demos schreiben oder sich in der Lernphase befinden, könnte der ROI dieser Architektur nicht sehr rentabel sein.
Außerdem müssen die aktuellen Sicherheitsprobleme von OpenClaw beachtet werden. Laut öffentlichen Informationen wurden bereits mehrere kritische CVEs offengelegt, und es wurden 341 bösartige Community-Plugins entdeckt, die Datenstehlverhalten aufweisen. Bei der Bereitstellung von OpenClaw müssen Isolation und Berechtigungssteuerung gut umgesetzt werden. Das ist auch der Grund, warum ich OpenClaw bisher nicht auf meinem Hauptrechner bereitgestellt habe.
Ein weiterer Punkt ist, dass Elvis in seinen Tweets die Codeüberprüfung von Claude Code eher negativ bewertet hat, aber kürzlich hat Claude Code die Funktion Agent Teams (offizielle integrierte Multi-Agent-Zusammenarbeit) eingeführt, und Anthropic arbeitet ebenfalls in diese Richtung.
Aber abgesehen von diesen Details ist der Architekturansatz von Elvis mit einer Orchestrierungsebene und einer Ausführungsebene definitiv bemerkenswert. Das Nullsummenspiel des Kontextfensters ist eine echte Einschränkung, und die Verwendung einer Schichtenarchitektur zur Lösung dieses Problems, sodass verschiedene KI ihre eigenen Aufgaben erfüllen, halte ich persönlich für den richtigen Weg....



