OpenClaw + Claude Code/Codex : Créer un essaim d'agents de développement personnel
OpenClaw + Claude Code/Codex : Créer un essaim d'agents de développement personnel
Bonjour à tous, je suis Lu Gong.
Récemment, j'ai vu un tweet sur X qui m'a immédiatement captivé. Un développeur indépendant nommé Elvis a déclaré qu'il n'utilisait plus directement Claude Code et Codex, mais qu'il utilisait OpenClaw comme couche d'orchestration, permettant à un AI orchestrateur nommé Zoe de gérer tout un essaim d'agents Claude Code et Codex.
Les données de ce tweet étaient également impressionnantes, avec 4,9 millions de vues, 11 000 likes et 1800 partages.
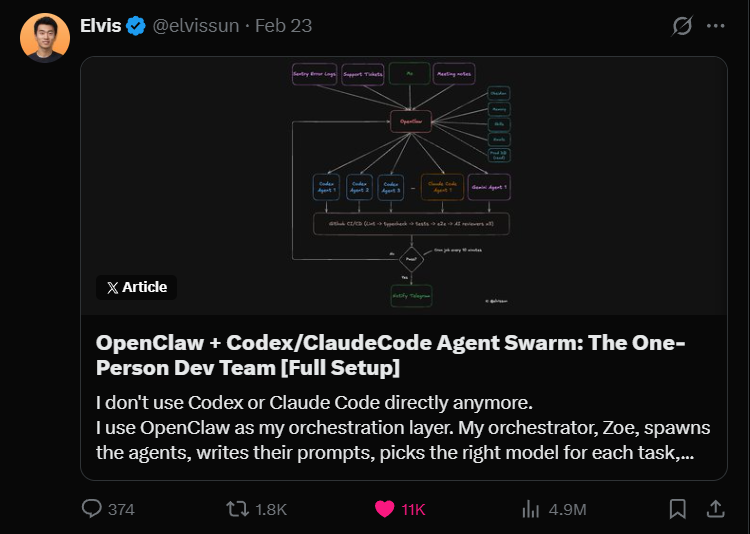 Nous avons écrit sur Vibe Coding pendant plus de quatre mois, et Claude Code a toujours été notre outil principal. J'ai également écrit quelques articles sur la collaboration multi-agents et l'architecture multi-agents de VSCode.
Nous avons écrit sur Vibe Coding pendant plus de quatre mois, et Claude Code a toujours été notre outil principal. J'ai également écrit quelques articles sur la collaboration multi-agents et l'architecture multi-agents de VSCode.
Mais en voyant la méthode d'Elvis, je ne peux que l'appeler expert. Une personne, avec un système d'orchestration, soumet en moyenne 50 fois du code par jour, et a même soumis 94 fois en une seule journée, tout en prenant 3 appels de clients, sans jamais ouvrir l'éditeur.
N'est-ce pas comme si une seule personne faisait le travail d'une équipe de développement ?
Aujourd'hui, cet article va décomposer comment il a réussi cela.
OpenClaw, tout le monde le connaît déjà
Ce petit homard a été très populaire depuis le Nouvel An. En termes simples, c'est un cadre d'agent AI open source, qui a actuellement plus de 240 000 étoiles sur GitHub, et a officiellement dépassé React il y a quelques jours, devenant le projet open source à la croissance d'étoiles la plus rapide de l'histoire de GitHub.
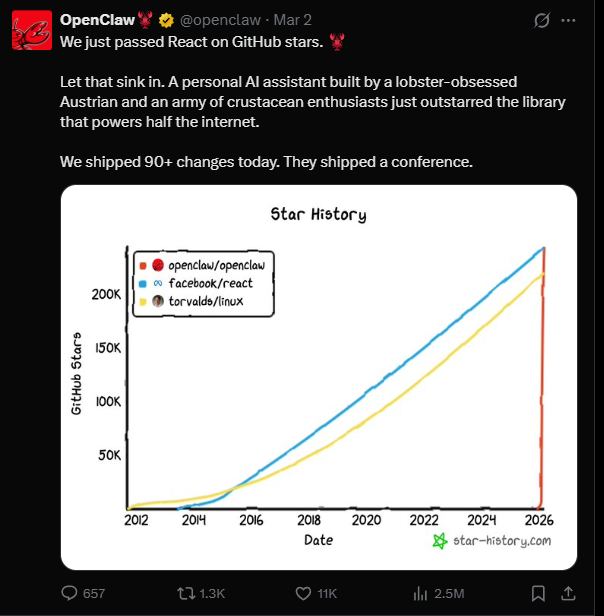 Le fondateur, Peter Steinberger, est un développeur autrichien, qui a précédemment fondé PSPDFKit (une entreprise B2B de cadre PDF), et a reçu un investissement de 100 millions d'euros de Insight Partners en 2021. En février de cette année, Peter a annoncé rejoindre OpenAI, et le projet OpenClaw a été transféré à une fondation open source pour son exploitation.
Le fondateur, Peter Steinberger, est un développeur autrichien, qui a précédemment fondé PSPDFKit (une entreprise B2B de cadre PDF), et a reçu un investissement de 100 millions d'euros de Insight Partners en 2021. En février de cette année, Peter a annoncé rejoindre OpenAI, et le projet OpenClaw a été transféré à une fondation open source pour son exploitation.
La position d'OpenClaw n'est pas celle d'un chatbot, mais d'un runtime d'agent AI qui fonctionne sur votre appareil local. Il a quatre composants principaux : Gateway (passerelle, connectant plus de 50 plateformes de messagerie), Agent (moteur d'inférence), Skills (plus de 5400 plugins), Memory (système de mémoire).
Mais la façon dont Elvis utilise OpenClaw est assez particulière. Il l'utilise directement comme couche d'orchestration, spécifiquement pour gérer les agents de codage Claude Code et Codex, sans l'utiliser comme assistant général.
Cette approche est en effet très originale.
Pourquoi a-t-on besoin d'une couche d'orchestration ?
Elvis a soulevé un point clé dans son tweet : la fenêtre contextuelle est un jeu à somme nulle.
Si vous y mettez du code, il n'y a plus d'espace pour le contexte commercial. Si vous y mettez l'historique des clients et les comptes rendus de réunion, il n'y a plus d'espace pour le dépôt de code. Peu importe la puissance d'un AI, il ne peut pas contenir simultanément ces deux types d'informations complètement différentes.
C'est pourquoi il a divisé le système en deux couches.
La couche supérieure est l'orchestrateur OpenClaw, Zoe, qui maîtrise tout le contexte commercial, y compris les données clients, les comptes rendus de réunion, les décisions historiques, quelles solutions ont été essayées et lesquelles ont échoué. Toutes ces informations sont stockées dans la bibliothèque de notes Obsidian d'Elvis, que Zoe peut lire directement.
La couche inférieure est composée des agents de codage Claude Code et Codex, qui ne se concentrent que sur le code. Chaque fois qu'un agent est lancé, Zoe lui écrit un prompt précis basé sur le contexte commercial, lui indiquant ce qu'il doit faire, quel est le contexte et ce que le client veut.
En résumé : l'orchestrateur est responsable de la compréhension des besoins, les agents de codage sont responsables de l'exécution. Chacun fait ce qu'il sait faire le mieux.
Cette architecture est similaire à celle du système interne Minions récemment dévoilé par Stripe. Les Minions de Stripe sont également conçus avec des agents de codage parallèles et une couche d'orchestration centralisée, pouvant fusionner plus de 1000 PR entièrement écrites par AI chaque semaine. Elvis dit qu'il a accidentellement construit une architecture similaire, mais qui fonctionne sur son propre Mac mini.
Flux de travail d'un cas réel
Elvis a utilisé un cas réel dans son tweet pour expliquer son flux de travail complet, je vais brièvement résumer les étapes clés.Il a répondu à un appel client, le client souhaitait réutiliser une configuration existante au sein de l'équipe. Après l'appel, il a discuté de ce besoin avec Zoe. Comme tous les comptes rendus de réunion sont automatiquement synchronisés avec Obsidian, Zoe savait déjà ce que le client avait dit, il n'était pas nécessaire qu'Elvis explique davantage. Ils ont ensemble défini la portée des fonctionnalités, et la solution finale était de créer un système de modèles.
Ensuite, Zoe a automatiquement effectué trois actions : recharger le service de déverrouillage pour le client (elle a des droits d'API administrateur), extraire la configuration existante du client depuis la base de données de production (droits en lecture seule, l'Agent de codage n'aura jamais ce droit), puis générer un Agent Codex, avec un prompt détaillé contenant le contexte commercial complet.
Chaque Agent a son propre worktree (branche isolée) et sa session tmux. La commande de démarrage est à peu près comme suit :
# Créer un worktree + lancer l'agent git worktree add ../feat-custom-templates -b feat/custom-templates origin/main cd ../feat-custom-templates && pnpm install tmux new-session -d -s "codex-templates" \ -c "/Users/elvis/Documents/GitHub/medialyst-worktrees/feat-custom-templates" \ "$HOME/.codex-agent/run-agent.sh templates gpt-5.3-codex high" Après que l'Agent a démarré, il y a une tâche planifiée qui vérifie toutes les 10 minutes. Mais il ne va pas directement demander à l'Agent (ce qui consommerait trop de tokens), mais exécute un script Shell déterministe, vérifiant si la session tmux est toujours active, s'il y a eu des PR créées, et si le CI a réussi.
Si le CI échoue, l'Agent redémarre automatiquement, avec un maximum de 3 tentatives. Une notification n'est envoyée que lorsque l'intervention humaine est nécessaire.
Après que l'Agent a terminé sa tâche, il crée automatiquement une PR. Mais créer une PR ne suffit pas, Elvis a défini un ensemble de critères d'achèvement : création de la PR, synchronisation de la branche avec main (sans conflit de fusion), CI entièrement réussi, révision de code par les trois modèles d'IA entièrement réussie, et si des modifications UI sont effectuées, une capture d'écran doit également être jointe.
Trois modèles d'IA effectuent la révision de code
Trois modèles d'IA effectuant la révision de code semblent très fiables. Discutons de son évaluation de ces trois modèles, c'est assez intéressant.
Codex Reviewer, il lui donne la meilleure note, disant que sa révision est très approfondie en ce qui concerne les cas limites et les erreurs logiques, avec un faible taux de faux positifs.
Gemini Code Assist Reviewer, gratuit, il dit qu'il est très utile, capable de détecter les vulnérabilités de sécurité et les problèmes d'évolutivité que d'autres modèles ont manqués, et peut également fournir des solutions de correction spécifiques.
Claude Code Reviewer, ses mots exacts étaient "pratiquement inutile", disant qu'il est trop prudent, avec plein de suggestions comme "envisagez d'ajouter...", la plupart relevant d'une surconception. À moins qu'il ne soit marqué comme un problème critique, il passe directement.
Quand j'ai vu cette partie, j'ai été un peu surpris. En tant qu'utilisateur intensif de Claude Code, j'ai effectivement rencontré des situations où il était trop conservateur lors de la révision de code, mais dire qu'il est pratiquement inutile est un peu exagéré. Cependant, cela souligne également que la révision croisée par plusieurs modèles a effectivement de la valeur, les biais différents des modèles se complétant parfaitement.
Une fois que les trois révisions sont toutes passées, Elvis reçoit une notification Telegram. À ce stade, il se concentre principalement sur les captures d'écran pour confirmer si les modifications UI sont correctes, et il fusionne de nombreuses PR sans même regarder le code. Il dit que sa révision manuelle ne prend que 5 à 10 minutes.
Proactivité de Zoe
Zoe n'est pas seulement une exécutante. Ce qui est plus intéressant que le flux de travail lui-même, c'est la proactivité de Zoe.
Elvis dit que Zoe ne va pas attendre qu'on lui attribue des tâches, elle cherche activement du travail à faire. Le matin, elle scanne les journaux d'erreurs de Sentry, découvre 4 nouvelles erreurs, et génère automatiquement 4 Agents pour les corriger. Après la réunion, elle scanne le compte rendu de réunion, marque les 3 besoins fonctionnels mentionnés par le client, puis lance automatiquement 3 Agents Codex. Le soir, elle scanne les journaux Git, et lance Claude Code pour mettre à jour le changelog et la documentation client.
Quand Elvis sort faire un tour et revient, il trouve un message sur Telegram : 7 PR sont prêtes, 3 nouvelles fonctionnalités, 4 corrections de bugs. N'est-ce pas l'effet d'une équipe de développement d'entreprise à une personne OPC que j'ai toujours espéré créer ?Et quand l'Agent échoue, la manière dont Zoe gère la situation est bien plus avancée qu'un simple nouvel essai. Elle analyse la raison de l'échec en tenant compte du contexte commercial. Le contexte de l'Agent est-il saturé ? Elle va réduire le champ d'action, permettant à l'Agent de se concentrer uniquement sur trois fichiers. L'Agent s'est-il égaré ? Elle va également corriger cela, en indiquant à l'Agent que le client veut X et non Y, et en fournissant les mots exacts de la réunion.
Avec le temps, Zoe accumulera également de l'expérience, se souvenant de quelles structures de prompt fonctionnent bien pour quel type de tâche, afin de rédiger des prompts plus précis la prochaine fois.
Cette idée est en fait une version améliorée de Ralph Loop. La logique centrale de Ralph Loop est un cycle de récupération de contexte, génération de sortie, évaluation des résultats et sauvegarde d'expérience, mais la plupart des implémentations utilisent un prompt fixe à chaque cycle. Le système d'Elvis est différent, à chaque nouvel essai, Zoe ajuste dynamiquement le prompt en fonction de la raison de l'échec, tout en bénéficiant d'un contexte commercial complet.
Coûts et matériel
En ce qui concerne les coûts, les données publiques d'Elvis indiquent que Claude coûte environ 100 dollars par mois, et Codex environ 90 dollars par mois. Il a également mentionné qu'on peut commencer à tester avec un budget de 20 dollars.
Ce coût est évidemment dérisoire comparé à l'embauche d'un développeur. Mais si l'on considère que vous devez également prendre des décisions produit, communiquer avec les clients et effectuer des revues de code, cela ressemble davantage à un amplificateur d'efficacité, vous permettant d'économiser sur les tâches répétitives de codage et de test.
En termes de matériel, Elvis a mentionné que son plus grand goulot d'étranglement est la RAM. Chaque Agent nécessite un worktree indépendant, chaque worktree a ses propres node_modules, et chaque Agent doit exécuter des constructions, des vérifications de type et des tests. Faire fonctionner 5 Agents simultanément signifie 5 compilateurs TypeScript parallèles, 5 exécuteurs de tests, et 5 ensembles de dépendances.
Son Mac mini avec 16 Go de RAM peut faire fonctionner au maximum 4 à 5 Agents en même temps, au-delà de cela, il commence à échanger de la mémoire. C'est pourquoi il a acheté un Mac Studio M4 Max avec 128 Go de RAM (3500 dollars), qu'il prévoit d'utiliser pour gérer plus d'Agents en parallèle.
Résumé et problèmes réels
Honnêtement, le système d'Elvis m'a vraiment impressionné. Auparavant, je considérais OpenClaw comme un jouet, et pour la productivité, je comptais sur Claude Code de manière indépendante. J'utilisais parfois des worktrees pour le parallélisme, mais cela n'atteignait pas le niveau de systématisation de ce système. Après avoir lu ses tweets, je pense que le plafond de l'IA en programmation a encore été relevé.
Je suis récemment en train de suivre son approche pour créer une équipe de développement entièrement automatisée avec OpenClaw. Donc, nous publierons bientôt plusieurs articles pratiques sur OpenClaw.
Il y a quelques problèmes réels dont je dois vous avertir.
Le prérequis pour ce système est d'avoir un produit clair, des besoins clients définis, et une pipeline CI/CD bien établie. Elvis travaille sur un véritable produit SaaS B2B, avec des clients, des revenus, et un environnement de production. Si vous êtes encore en phase de démonstration ou d'apprentissage, le ROI de cette architecture pourrait ne pas être très avantageux.
De plus, il faut également faire attention aux problèmes de sécurité d'OpenClaw. Selon les informations publiques, plusieurs CVE critiques ont été divulgués, et 341 plugins communautaires malveillants ont été découverts avec des comportements de vol de données. Lors du déploiement d'OpenClaw, l'isolement et le contrôle des permissions doivent être bien gérés. C'est aussi la raison pour laquelle je n'ai pas encore déployé OpenClaw sur ma machine principale.
Une autre chose, Elvis a une évaluation plutôt basse de la révision de code de Claude Code dans ses tweets, mais récemment, Claude Code a lancé la fonctionnalité Agent Teams (collaboration multi-Agent intégrée), et Anthropic s'oriente également vers l'orchestration dans cette direction.
Cependant, en mettant de côté ces détails, l'architecture d'Elvis, qui combine une couche d'orchestration et une couche d'exécution, mérite vraiment d'être examinée. Le jeu à somme nulle de la fenêtre de contexte est une contrainte réelle, et utiliser une architecture en couches pour résoudre ce problème, permettant à différentes IA de jouer leur rôle, est, à mon avis, la bonne direction....



