Recentment, he vist 2 bons articles sobre LLM+KG per a raonament lògic complex
Recentment, he vist 2 bons articles sobre LLM+KG per a raonament lògic complex
-
LARK https://arxiv.org/abs/2305.01157 Complex Logical Reasoning over Knowledge Graphs using Large Language Models
-
ROG https://arxiv.org/abs/2512.19092 A Large Language Model Based Method for Complex Logical Reasoning over Knowledge Graphs
I. La dificultat del raonament de grafs de coneixement
El graf de coneixement (KG), com a portador central del coneixement estructurat, s'enfronta a tres problemes principals:
- Complexitat: raonament de múltiples salts, interseccions i unions, negació i altres combinacions que exploten
- Incompletesa: els KG del món real solen tenir soroll i mancances
- Generalització: els mètodes d'incrustació tradicionals són difícils de transferir entre conjunts de dades
Les solucions tradicionals (com Query2Box, BetaE) depenen de l'espai d'incrustació geomètrica, modelant les operacions lògiques com a operacions vectorials/de caixa, però la pèrdua d'informació és greu durant el raonament profund. Com fer que el model entengui l'estructura lògica i raoni de manera flexible? L'auge dels models de llenguatge grans (LLM) ofereix una nova idea.
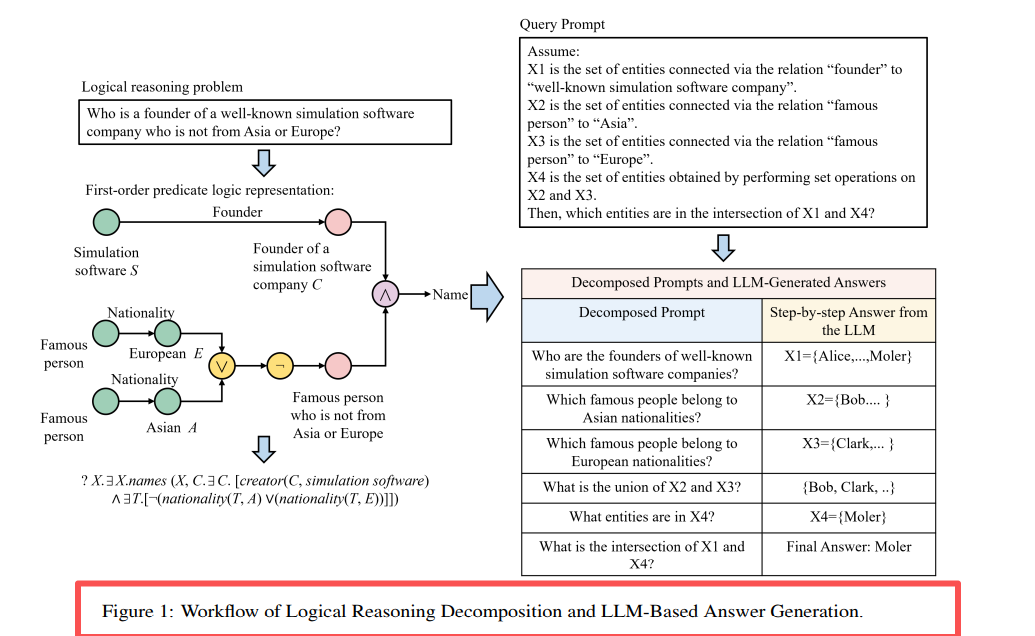
 Figura 1: Descomposició de la cadena de consulta de LARK i flux de raonament LLM. Descompon la consulta complexa de múltiples operacions en subconsultes d'una sola operació i resol pas a pas.
Figura 1: Descomposició de la cadena de consulta de LARK i flux de raonament LLM. Descompon la consulta complexa de múltiples operacions en subconsultes d'una sola operació i resol pas a pas.
II. Solució: Herència i evolució de dues generacions de mètodes
LARK (2023) —— Obra pionera
Figura 2: Estratègia de descomposició de 14 tipus de consulta. 3p es divideix en 3 projeccions, 3i es divideix en 3 projeccions + 1 intersecció.
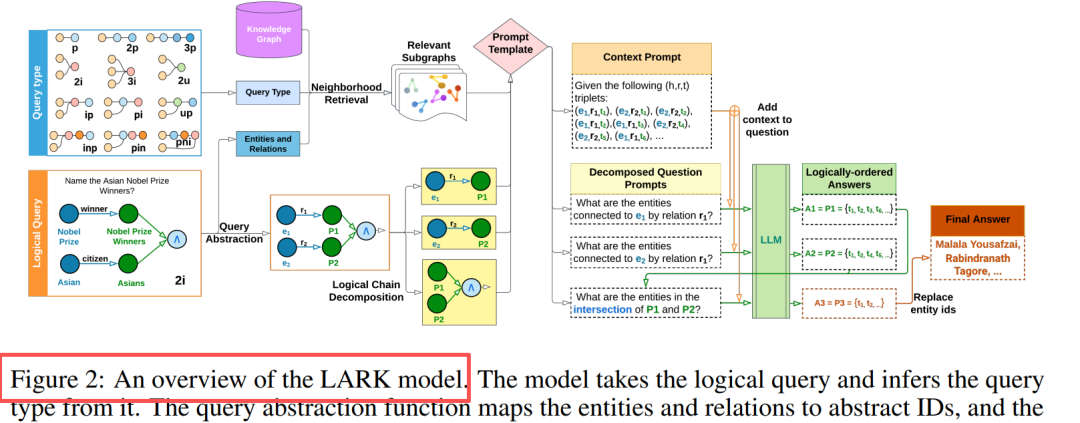 Innovació central: abstracció de consulta + descomposició de cadena lògica
Innovació central: abstracció de consulta + descomposició de cadena lògica
Disseny de components Abstracció de consulta Substitució d'entitats/relacions per ID, eliminant al·lucinacions i millorant la generalització Recuperació de veïnat Recorregut en profunditat k-hop (k=3), extraient subgrafs rellevants Descomposició en cadena Consulta de múltiples operacions → Seqüència de subconsultes d'una sola operació Raonament seqüencial Emmagatzematge en memòria cau dels resultats intermedis, reemplaçant els marcadors de posició lògicament ordenats Perspectiva clau: els LLM destaquen en consultes senzilles, el rendiment millora entre un 20% i un 33% després de descompondre les consultes complexes.
ROG (2025) —— Versió avançada
 Hereta el marc LARK, afegint un mecanisme de consens d'Agent:
Hereta el marc LARK, afegint un mecanisme de consens d'Agent:
ROG = Nucli LARK + Col·laboració multi-Agent + Reforç de la cadena de pensament
Explicació de les millores
Disseny d'Agent
Agent = Base de coneixement + LLM, presa de decisions per consens multi-Agent
Millora CoT
Plantilles d'indicacions de cadena de pensament més clares
Adaptació nacional
Basat en ChatGLM+Neo4j, orientat a camps verticals com l'energia elèctrica
 Model de flux de dades de ROG
Model de flux de dades de ROG
Salt de rendiment: a FB15k, la consulta ip (projecció després de la intersecció) MRR augmenta de 29,3→62,0, un augment del 111%!
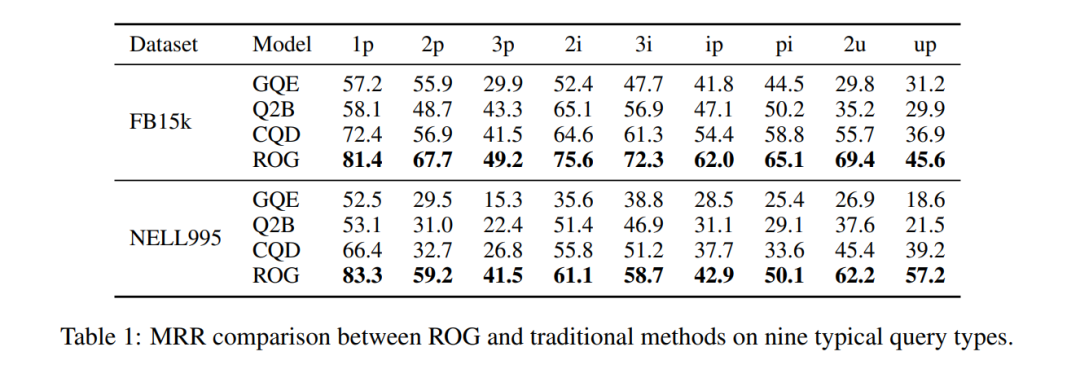 Taula 1: Comparació MRR del conjunt de dades FB15k. ROG lidera de manera integral, la millora de la consulta composta és la més significativa.
Taula 1: Comparació MRR del conjunt de dades FB15k. ROG lidera de manera integral, la millora de la consulta composta és la més significativa.
III. Establiment de paradigma i direcció futura
Dues generacions d'articles verifiquen conjuntament un paradigma:
"Recuperació millorada + Descomposició de consulta + Raonament LLM" és un camí eficaç per al raonament lògic complex de KG.
Tendències clau:
- L'abstracció és crucial —— Eliminar el soroll semàntic, centrar-se en l'estructura lògica
- L'estratègia de descomposició determina el límit superior —— La descomposició en cadena és més fiable que l'extrem a extrem
- La capacitat del model s'allibera contínuament —— Des de Llama2-7B fins a ChatGLM, el progrés de la base aporta guanys significatius
El mecanisme d'Agent de ROG millora la interpretabilitat, però la innovació central rau en l'optimització d'enginyeria en lloc d'un avenç teòric. La direcció futura podria ser: estratègies de descomposició dinàmica (complexitat de consulta adaptativa), fusió KG multimodal i verificació de domini obert a major escala.



