Nedávno jsem viděl 2 skvělé články o LLM+KG pro komplexní logické usuzování
Nedávno jsem viděl 2 skvělé články o LLM+KG pro komplexní logické usuzování
-
LARK https://arxiv.org/abs/2305.01157 Complex Logical Reasoning over Knowledge Graphs using Large Language Models
-
ROG https://arxiv.org/abs/2512.19092 A Large Language Model Based Method for Complex Logical Reasoning over Knowledge Graphs
I. Obtíže usuzování znalostních grafů
Znalostní grafy (KG) jakožto klíčový nosič strukturovaných znalostí čelí třem hlavním problémům:
- Složitost: Kombinatorická exploze vícehopových odvozování, průniků a sjednocení, negací atd.
- Neúplnost: Reálné KG obecně vykazují šum a chybějící data
- Generalizace: Tradiční metody vkládání se obtížně přenášejí mezi datovými sadami
Tradiční řešení (jako Query2Box, BetaE) spoléhají na geometrický vkládací prostor a modelují logické operace jako vektorové/krabicové operace, ale při hlubokém usuzování dochází k závažným ztrátám informací. Jak zajistit, aby model rozuměl logické struktuře a zároveň flexibilně usuzoval? Vzestup velkých jazykových modelů (LLM) nabízí nový přístup.
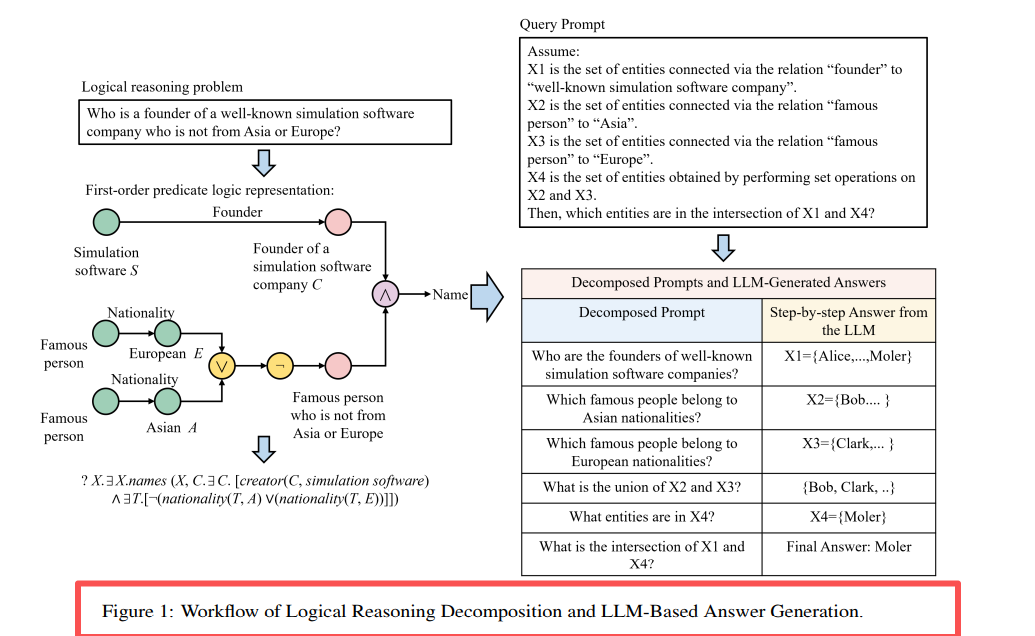
 Obrázek 1: Rozklad dotazovacího řetězce LARK a proces usuzování LLM. Rozkládá složité dotazy s více operacemi na dílčí dotazy s jednou operací a postupně je řeší.
Obrázek 1: Rozklad dotazovacího řetězce LARK a proces usuzování LLM. Rozkládá složité dotazy s více operacemi na dílčí dotazy s jednou operací a postupně je řeší.
II. Řešení: Dědictví a evoluce dvou generací metod
LARK (2023) —— Průkopnické dílo
Obrázek 2: Strategie rozkladu pro 14 typů dotazů. 3p je rozděleno na 3 projekce, 3i je rozděleno na 3 projekce + 1 průnik.
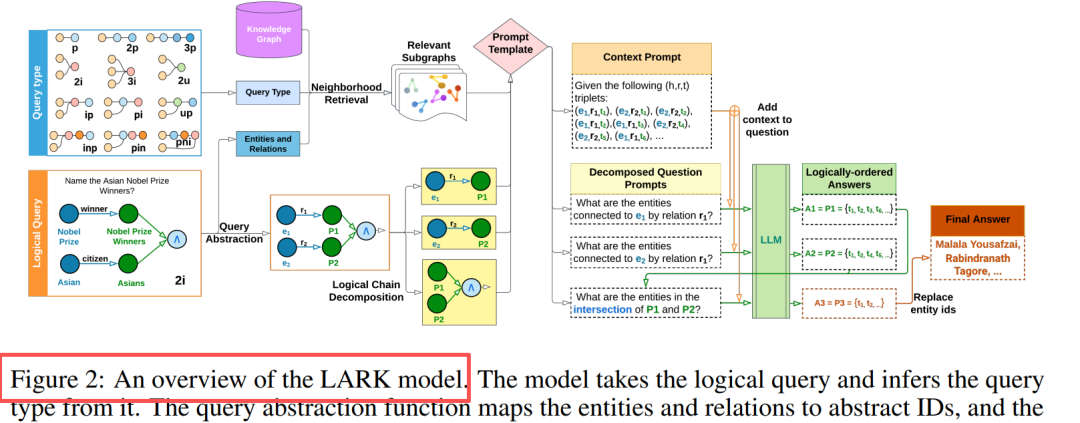 Klíčové inovace: Abstrakce dotazů + Rozklad logického řetězce
Klíčové inovace: Abstrakce dotazů + Rozklad logického řetězce
Komponenty Návrh Abstrakce dotazů Entity/vztahy jsou nahrazeny ID, čímž se eliminuje halucinace a zvyšuje generalizace Vyhledávání sousedství Prohledávání do hloubky k-hop (k=3), extrahování souvisejících podgrafů Řetězový rozklad Dotazy s více operacemi → Sekvence dílčích dotazů s jednou operací Sekvenční usuzování Ukládání mezivýsledků do mezipaměti, logické uspořádané nahrazování zástupných symbolů Klíčový postřeh: LLM vynikají v jednoduchých dotazech, složité dotazy po rozkladu zlepšují výkon o 20 % - 33 %.
ROG (2025) —— Pokročilá verze
 Dědí rámec LARK a přidává mechanismus konsensu Agentů:
Dědí rámec LARK a přidává mechanismus konsensu Agentů:
ROG = Jádro LARK + Spolupráce více Agentů + Posílení myšlenkového řetězce
Vysvětlení vylepšení
Návrh Agenta
Agent = Znalostní báze + LLM, rozhodování konsensem více Agentů
CoT vylepšení
Jasnější šablony pro myšlenkový řetězec
Domácí adaptace
Založeno na ChatGLM+Neo4j, zaměřeno na vertikální oblasti, jako je energetika
 Model datového toku ROG
Model datového toku ROG
Skokový nárůst výkonu: Na FB15k, ip dotaz (projekce po průniku) MRR z 29,3 → 62,0, zlepšení o 111 %!
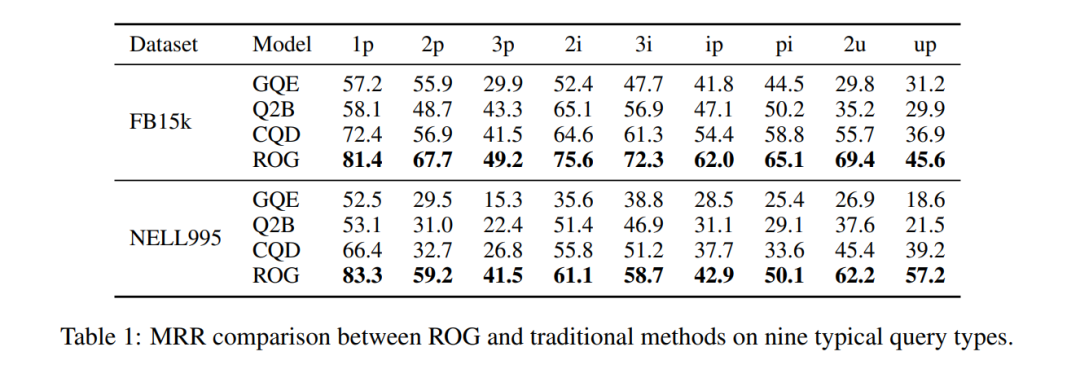 Tabulka 1: Srovnání MRR datové sady FB15k. ROG je celkově lepší, nejvýraznější zlepšení u složených dotazů.
Tabulka 1: Srovnání MRR datové sady FB15k. ROG je celkově lepší, nejvýraznější zlepšení u složených dotazů.
III. Stanovení paradigmatu a budoucí směr
Oba články společně ověřují paradigma:
"Rozšíření vyhledávání + Rozklad dotazů + Usuzování LLM" je efektivní cesta pro komplexní logické usuzování KG.
Klíčové trendy:
- Abstrakce je zásadní —— Odstranění sémantického šumu, zaměření na logickou strukturu
- Strategie rozkladu určuje horní hranici —— Řetězový rozklad je spolehlivější než end-to-end
- Schopnosti modelu se neustále uvolňují —— Od Llama2-7B po ChatGLM, pokrok základny přináší významné zisky
Mechanismus Agentů ROG sice zvyšuje vysvětlitelnost, ale klíčová inovace spočívá spíše v inženýrské optimalizaci než v teoretickém průlomu. Budoucí směr může spočívat v: strategiích dynamického rozkladu (adaptivní složitost dotazů), fúzi multimodálních KG a rozsáhlejším ověřování v otevřené doméně.



